 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and ethics in insurance: a new solution to mitigate proxy discrimination in risk modeling
Jul 25, 2023The development of Machine Learning is experiencing growing interest from the general public, and in recent years there have been numerous press articles questioning its objectivity: racism, sexism, \dots Driven by the growing attention of regulators on the ethical use of data in insurance, the actuarial community must rethink pricing and risk selection practices for fairer insurance. Equity is a philosophy concept that has many different definitions in every jurisdiction that influence each other without currently reaching consensus. In Europe, the Charter of Fundamental Rights defines guidelines on discrimination, and the use of sensitive personal data in algorithms is regulated. If the simple removal of the protected variables prevents any so-called `direct' discrimination, models are still able to `indirectly' discriminate between individuals thanks to latent interactions between variables, which bring better performance (and therefore a better quantification of risk, segmentation of prices, and so on). After introducing the key concepts related to discrimination, we illustrate the complexity of quantifying them. We then propose an innovative method, not yet met in the literature, to reduce the risks of indirect discrimination thanks to mathematical concepts of linear algebra. This technique is illustrated in a concrete case of risk selection in life insurance, demonstrating its simplicity of use and its promising performance.
Applying Machine Learning to Life Insurance: some knowledge sharing to master it
Sep 05, 2022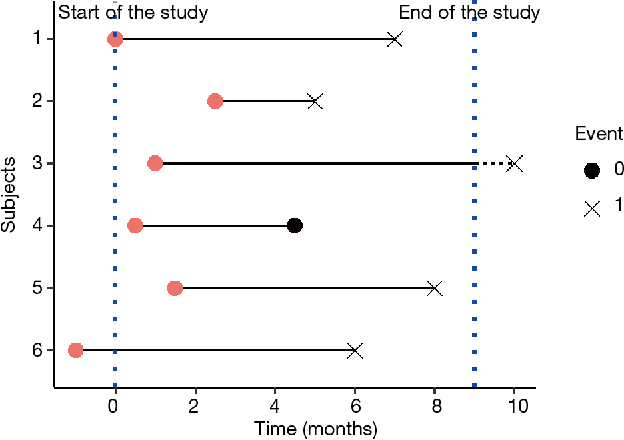
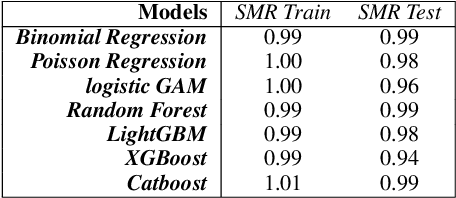

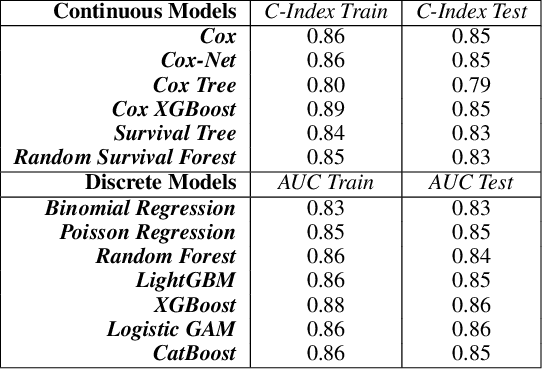
Machine Learning permeates many industries, which brings new source of benefits for companies. However within the life insurance industry, Machine Learning is not widely used in practice as over the past years statistical models have shown their efficiency for risk assessment. Thus insurers may face difficulties to assess the value of the artificial intelligence. Focusing on the modification of the life insurance industry over time highlights the stake of using Machine Learning for insurers and benefits that it can bring by unleashing data value. This paper reviews traditional actuarial methodologies for survival modeling and extends them with Machine Learning techniques. It points out differences with regular machine learning models and emphasizes importance of specific implementations to face censored data with machine learning models family.In complement to this article, a Python library has been developed. Different open-source Machine Learning algorithms have been adjusted to adapt the specificities of life insurance data, namely censoring and truncation. Such models can be easily applied from this SCOR library to accurately model life insurance risks.