 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Attention Scores with Bootstrapping
Apr 01, 2026Vision transformers (ViT) rely on attention mechanism to weigh input features, and therefore attention scores have naturally been considered as explanations for its decision-making process. However, attention scores are almost always non-zero, resulting in noisy and diffused attention maps and limiting interpretability. Can we quantify uncertainty measures of attention scores and obtain regularized attention scores? To this end, we consider attention scores of ViT in a statistical framework where independent noise would lead to insignificant yet non-zero scores. Leveraging statistical learning techniques, we introduce the bootstrapping for attention scores which generates a baseline distribution of attention scores by resampling input features. Such a bootstrap distribution is then used to estimate significances and posterior probabilities of attention scores. In natural and medical images, the proposed \emph{Attention Regularization} approach demonstrates a straightforward removal of spurious attention arising from noise, drastically improving shrinkage and sparsity. Quantitative evaluations are conducted using both simulation and real-world datasets. Our study highlights bootstrapping as a practical regularization tool when using attention scores as explanations for ViT. Code available: https://github.com/ncchung/AttentionRegularization
Explain and Monitor Deep Learning Models for Computer Vision using Obz AI
Aug 25, 2025


Deep learning has transformed computer vision (CV), achieving outstanding performance in classification, segmentation, and related tasks. Such AI-based CV systems are becoming prevalent, with applications spanning from medical imaging to surveillance. State of the art models such as convolutional neural networks (CNNs) and vision transformers (ViTs) are often regarded as ``black boxes,'' offering limited transparency into their decision-making processes. Despite a recent advancement in explainable AI (XAI), explainability remains underutilized in practical CV deployments. A primary obstacle is the absence of integrated software solutions that connect XAI techniques with robust knowledge management and monitoring frameworks. To close this gap, we have developed Obz AI, a comprehensive software ecosystem designed to facilitate state-of-the-art explainability and observability for vision AI systems. Obz AI provides a seamless integration pipeline, from a Python client library to a full-stack analytics dashboard. With Obz AI, a machine learning engineer can easily incorporate advanced XAI methodologies, extract and analyze features for outlier detection, and continuously monitor AI models in real time. By making the decision-making mechanisms of deep models interpretable, Obz AI promotes observability and responsible deployment of computer vision systems.
Safeguarding Generative AI Applications in Preclinical Imaging through Hybrid Anomaly Detection
Aug 11, 2025

Generative AI holds great potentials to automate and enhance data synthesis in nuclear medicine. However, the high-stakes nature of biomedical imaging necessitates robust mechanisms to detect and manage unexpected or erroneous model behavior. We introduce development and implementation of a hybrid anomaly detection framework to safeguard GenAI models in BIOEMTECH's eyes(TM) systems. Two applications are demonstrated: Pose2Xray, which generates synthetic X-rays from photographic mouse images, and DosimetrEYE, which estimates 3D radiation dose maps from 2D SPECT/CT scans. In both cases, our outlier detection (OD) enhances reliability, reduces manual oversight, and supports real-time quality control. This approach strengthens the industrial viability of GenAI in preclinical settings by increasing robustness, scalability, and regulatory compliance.
False Sense of Security in Explainable Artificial Intelligence (XAI)
May 06, 2024A cautious interpretation of AI regulations and policy in the EU and the USA place explainability as a central deliverable of compliant AI systems. However, from a technical perspective, explainable AI (XAI) remains an elusive and complex target where even state of the art methods often reach erroneous, misleading, and incomplete explanations. "Explainability" has multiple meanings which are often used interchangeably, and there are an even greater number of XAI methods - none of which presents a clear edge. Indeed, there are multiple failure modes for each XAI method, which require application-specific development and continuous evaluation. In this paper, we analyze legislative and policy developments in the United States and the European Union, such as the Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence, the AI Act, the AI Liability Directive, and the General Data Protection Regulation (GDPR) from a right to explanation perspective. We argue that these AI regulations and current market conditions threaten effective AI governance and safety because the objective of trustworthy, accountable, and transparent AI is intrinsically linked to the questionable ability of AI operators to provide meaningful explanations. Unless governments explicitly tackle the issue of explainability through clear legislative and policy statements that take into account technical realities, AI governance risks becoming a vacuous "box-ticking" exercise where scientific standards are replaced with legalistic thresholds, providing only a false sense of security in XAI.
Class-Discriminative Attention Maps for Vision Transformers
Dec 04, 2023Interpretability methods are critical components for examining and exploring deep neural networks (DNN), as well as increasing our understanding of and trust in them. Vision transformers (ViT), which can be trained to state-of-the-art performance with a self-supervised learning (SSL) training method, provide built-in attention maps (AM). While AMs can provide high-quality semantic segmentation of input images, they do not account for any signal coming from a downstream classifier. We introduce class-discriminative attention maps (CDAM), a novel post-hoc explanation method that is highly sensitive to the target class. Our method essentially scales attention scores by how relevant the corresponding tokens are for the predictions of a classifier head. Alternative to classifier outputs, CDAM can also explain a user-defined concept by targeting similarity measures in the latent space of the ViT. This allows for explanations of arbitrary concepts, defined by the user through a few sample images. We investigate the operating characteristics of CDAM in comparison with relevance propagation (RP) and token ablation maps (TAM), an alternative to pixel occlusion methods. CDAM is highly class-discriminative and semantically relevant, while providing implicit regularization of relevance scores. PyTorch implementation: \url{https://github.com/lenbrocki/CDAM} Web live demo: \url{https://cdam.informatism.com/}
Challenges of Large Language Models for Mental Health Counseling
Nov 23, 2023The global mental health crisis is looming with a rapid increase in mental disorders, limited resources, and the social stigma of seeking treatment. As the field of artificial intelligence (AI) has witnessed significant advancements in recent years, large language models (LLMs) capable of understanding and generating human-like text may be used in supporting or providing psychological counseling. However, the application of LLMs in the mental health domain raises concerns regarding the accuracy, effectiveness, and reliability of the information provided. This paper investigates the major challenges associated with the development of LLMs for psychological counseling, including model hallucination, interpretability, bias, privacy, and clinical effectiveness. We explore potential solutions to these challenges that are practical and applicable to the current paradigm of AI. From our experience in developing and deploying LLMs for mental health, AI holds a great promise for improving mental health care, if we can carefully navigate and overcome pitfalls of LLMs.
Integration of Radiomics and Tumor Biomarkers in Interpretable Machine Learning Models
Mar 20, 2023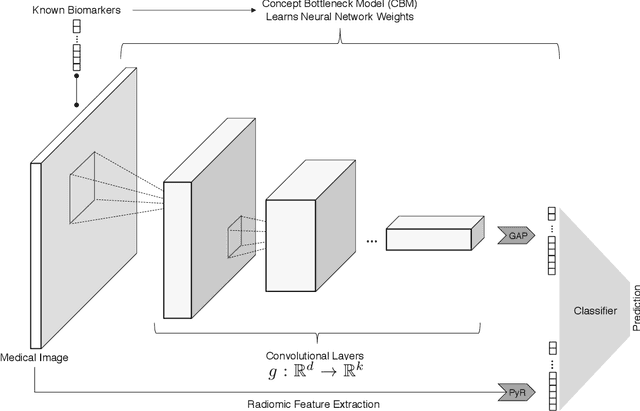
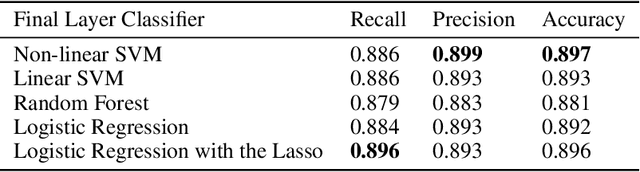
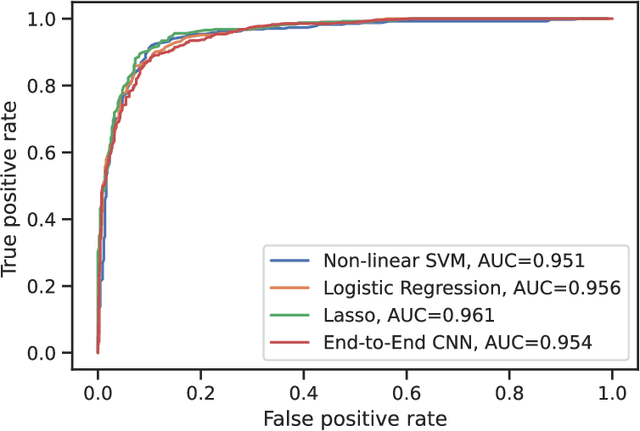

Despite the unprecedented performance of deep neural networks (DNNs) in computer vision, their practical application in the diagnosis and prognosis of cancer using medical imaging has been limited. One of the critical challenges for integrating diagnostic DNNs into radiological and oncological applications is their lack of interpretability, preventing clinicians from understanding the model predictions. Therefore, we study and propose the integration of expert-derived radiomics and DNN-predicted biomarkers in interpretable classifiers which we call ConRad, for computerized tomography (CT) scans of lung cancer. Importantly, the tumor biomarkers are predicted from a concept bottleneck model (CBM) such that once trained, our ConRad models do not require labor-intensive and time-consuming biomarkers. In our evaluation and practical application, the only input to ConRad is a segmented CT scan. The proposed model is compared to convolutional neural networks (CNNs) which act as a black box classifier. We further investigated and evaluated all combinations of radiomics, predicted biomarkers and CNN features in five different classifiers. We found the ConRad models using non-linear SVM and the logistic regression with the Lasso outperform others in five-fold cross-validation, although we highlight that interpretability of ConRad is its primary advantage. The Lasso is used for feature selection, which substantially reduces the number of non-zero weights while increasing the accuracy. Overall, the proposed ConRad model combines CBM-derived biomarkers and radiomics features in an interpretable ML model which perform excellently for the lung nodule malignancy classification.
Feature Perturbation Augmentation for Reliable Evaluation of Importance Estimators
Mar 02, 2023

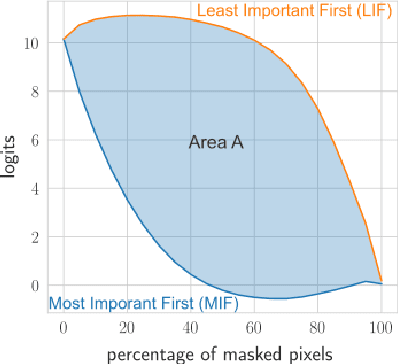
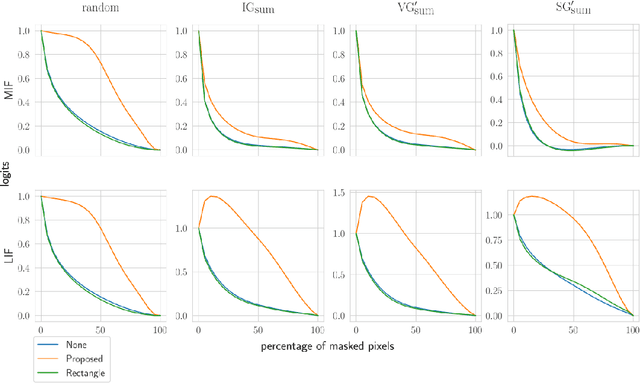
Post-hoc explanation methods attempt to make the inner workings of deep neural networks more interpretable. However, since a ground truth is in general lacking, local post-hoc interpretability methods, which assign importance scores to input features, are challenging to evaluate. One of the most popular evaluation frameworks is to perturb features deemed important by an interpretability method and to measure the change in prediction accuracy. Intuitively, a large decrease in prediction accuracy would indicate that the explanation has correctly quantified the importance of features with respect to the prediction outcome (e.g., logits). However, the change in the prediction outcome may stem from perturbation artifacts, since perturbed samples in the test dataset are out of distribution (OOD) compared to the training dataset and can therefore potentially disturb the model in an unexpected manner. To overcome this challenge, we propose feature perturbation augmentation (FPA) which creates and adds perturbed images during the model training. Through extensive computational experiments, we demonstrate that FPA makes deep neural networks (DNNs) more robust against perturbations. Furthermore, training DNNs with FPA demonstrate that the sign of importance scores may explain the model more meaningfully than has previously been assumed. Overall, FPA is an intuitive data augmentation technique that improves the evaluation of post-hoc interpretability methods.
Deep Learning Mental Health Dialogue System
Jan 23, 2023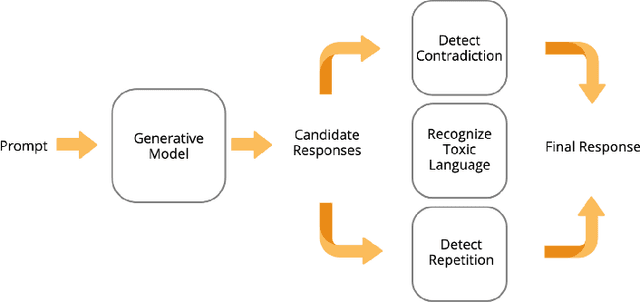
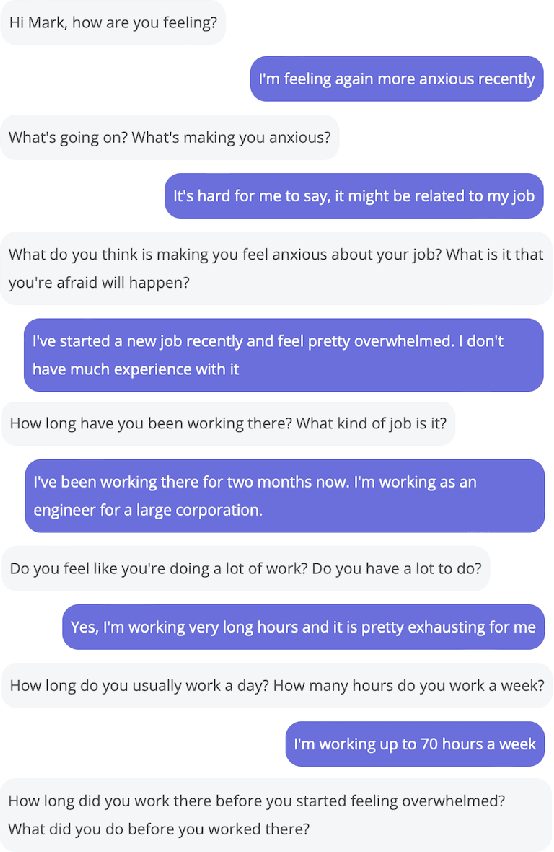
Mental health counseling remains a major challenge in modern society due to cost, stigma, fear, and unavailability. We posit that generative artificial intelligence (AI) models designed for mental health counseling could help improve outcomes by lowering barriers to access. To this end, we have developed a deep learning (DL) dialogue system called Serena. The system consists of a core generative model and post-processing algorithms. The core generative model is a 2.7 billion parameter Seq2Seq Transformer fine-tuned on thousands of transcripts of person-centered-therapy (PCT) sessions. The series of post-processing algorithms detects contradictions, improves coherency, and removes repetitive answers. Serena is implemented and deployed on \url{https://serena.chat}, which currently offers limited free services. While the dialogue system is capable of responding in a qualitatively empathetic and engaging manner, occasionally it displays hallucination and long-term incoherence. Overall, we demonstrate that a deep learning mental health dialogue system has the potential to provide a low-cost and effective complement to traditional human counselors with less barriers to access.
Evaluation of importance estimators in deep learning classifiers for Computed Tomography
Sep 30, 2022Deep learning has shown superb performance in detecting objects and classifying images, ensuring a great promise for analyzing medical imaging. Translating the success of deep learning to medical imaging, in which doctors need to understand the underlying process, requires the capability to interpret and explain the prediction of neural networks. Interpretability of deep neural networks often relies on estimating the importance of input features (e.g., pixels) with respect to the outcome (e.g., class probability). However, a number of importance estimators (also known as saliency maps) have been developed and it is unclear which ones are more relevant for medical imaging applications. In the present work, we investigated the performance of several importance estimators in explaining the classification of computed tomography (CT) images by a convolutional deep network, using three distinct evaluation metrics. First, the model-centric fidelity measures a decrease in the model accuracy when certain inputs are perturbed. Second, concordance between importance scores and the expert-defined segmentation masks is measured on a pixel level by a receiver operating characteristic (ROC) curves. Third, we measure a region-wise overlap between a XRAI-based map and the segmentation mask by Dice Similarity Coefficients (DSC). Overall, two versions of SmoothGrad topped the fidelity and ROC rankings, whereas both Integrated Gradients and SmoothGrad excelled in DSC evaluation. Interestingly, there was a critical discrepancy between model-centric (fidelity) and human-centric (ROC and DSC) evaluation. Expert expectation and intuition embedded in segmentation maps does not necessarily align with how the model arrived at its prediction. Understanding this difference in interpretability would help harnessing the power of deep learning in medicine.
* 4th International Workshop on EXplainable and TRAnsparent AI and Multi-Agent Systems (EXTRAAMAS 2022) - International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS)