 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Interpretability Methods and Perturbation Artifacts in Deep Neural Networks
Paper and Code
Mar 06, 2022

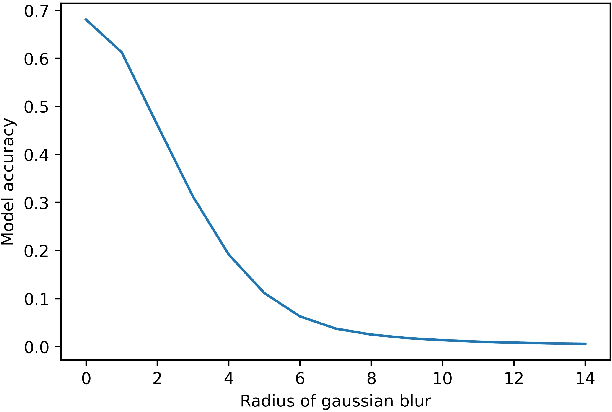
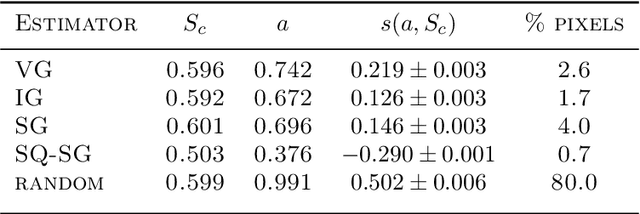
The challenge of interpreting predictions from deep neural networks has prompted the development of numerous interpretability methods. Many of interpretability methods attempt to quantify the importance of input features with respect to the class probabilities, and are called importance estimators or saliency maps. A popular approach to evaluate such interpretability methods is to perturb input features deemed important for predictions and observe the decrease in accuracy. However, perturbation-based evaluation methods may confound the sources of accuracy degradation. We conduct computational experiments that allow to empirically estimate the $\textit{fidelity}$ of interpretability methods and the contribution of perturbation artifacts. All considered importance estimators clearly outperform a random baseline, which contradicts the findings of ROAR [arXiv:1806.10758]. We further compare our results to the crop-and-resize evaluation framework [arXiv:1705.07857], which are largely in agreement. Our study suggests that we can estimate the impact of artifacts and thus empirically evaluate interpretability methods without retraining.