 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sample Efficiency in Evolutionary RL Using Off-Policy Ranking
Aug 22, 2022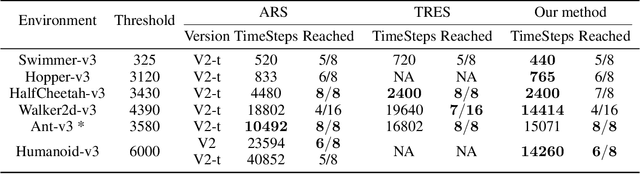
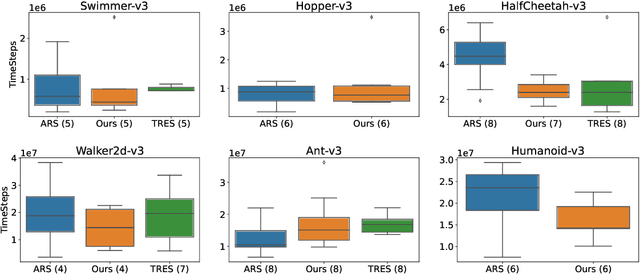
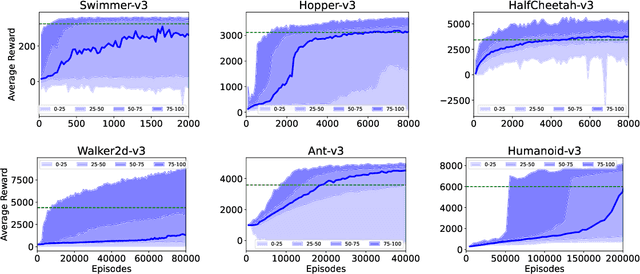
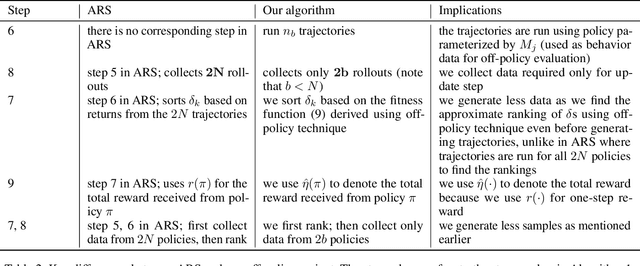
Evolution Strategy (ES) is a powerful black-box optimization technique based on the idea of natural evolution. In each of its iterations, a key step entails ranking candidate solutions based on some fitness score. For an ES method in Reinforcement Learning (RL), this ranking step requires evaluating multiple policies. This is presently done via on-policy approaches: each policy's score is estimated by interacting several times with the environment using that policy. This leads to a lot of wasteful interactions since, once the ranking is done, only the data associated with the top-ranked policies is used for subsequent learning. To improve sample efficiency, we propose a novel off-policy alternative for ranking, based on a local approximation for the fitness function. We demonstrate our idea in the context of a state-of-the-art ES method called the Augmented Random Search (ARS). Simulations in MuJoCo tasks show that, compared to the original ARS, our off-policy variant has similar running times for reaching reward thresholds but needs only around 70% as much data. It also outperforms the recent Trust Region ES. We believe our ideas should be extendable to other ES methods as well.