 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Algorithms for Adaptive Estimation of the Average Treatment Effect
Feb 07, 2025Estimation and inference for the Average Treatment Effect (ATE) is a cornerstone of causal inference and often serves as the foundation for developing procedures for more complicated settings. Although traditionally analyzed in a batch setting, recent advances in martingale theory have paved the way for adaptive methods that can enhance the power of downstream inference. Despite these advances, progress in understanding and developing adaptive algorithms remains in its early stages. Existing work either focus on asymptotic analyses that overlook exploration-exploitation tradeoffs relevant in finite-sample regimes or rely on simpler but suboptimal estimators. In this work, we address these limitations by studying adaptive sampling procedures that take advantage of the asymptotically optimal Augmented Inverse Probability Weighting (AIPW) estimator. Our analysis uncovers challenges obscured by asymptotic approaches and introduces a novel algorithmic design principle reminiscent of optimism in multiarmed bandits. This principled approach enables our algorithm to achieve significant theoretical and empirical gains compared to prior methods. Our findings mark a step forward in advancing adaptive causal inference methods in theory and practice.
Logarithmic Neyman Regret for Adaptive Estimation of the Average Treatment Effect
Nov 21, 2024Estimation of the Average Treatment Effect (ATE) is a core problem in causal inference with strong connections to Off-Policy Evaluation in Reinforcement Learning. This paper considers the problem of adaptively selecting the treatment allocation probability in order to improve estimation of the ATE. The majority of prior work on adaptive ATE estimation focus on asymptotic guarantees, and in turn overlooks important practical considerations such as the difficulty of learning the optimal treatment allocation as well as hyper-parameter selection. Existing non-asymptotic methods are limited by poor empirical performance and exponential scaling of the Neyman regret with respect to problem parameters. In order to address these gaps, we propose and analyze the Clipped Second Moment Tracking (ClipSMT) algorithm, a variant of an existing algorithm with strong asymptotic optimality guarantees, and provide finite sample bounds on its Neyman regret. Our analysis shows that ClipSMT achieves exponential improvements in Neyman regret on two fronts: improving the dependence on $T$ from $O(\sqrt{T})$ to $O(\log T)$, as well as reducing the exponential dependence on problem parameters to a polynomial dependence. Finally, we conclude with simulations which show the marked improvement of ClipSMT over existing approaches.
Sample Efficient Reinforcement Learning from Human Feedback via Active Exploration
Dec 01, 2023Preference-based feedback is important for many applications in reinforcement learning where direct evaluation of a reward function is not feasible. A notable recent example arises in reinforcement learning from human feedback (RLHF) on large language models. For many applications of RLHF, the cost of acquiring the human feedback can be substantial. In this work, we take advantage of the fact that one can often choose contexts at which to obtain human feedback in order to most efficiently identify a good policy, and formalize this as an offline contextual dueling bandit problem. We give an upper-confidence-bound style algorithm for this problem and prove a polynomial worst-case regret bound. We then provide empirical confirmation in a synthetic setting that our approach outperforms existing methods. After, we extend the setting and methodology for practical use in RLHF training of large language models. Here, our method is able to reach better performance with fewer samples of human preferences than multiple baselines on three real-world datasets.
Kernelized Offline Contextual Dueling Bandits
Jul 21, 2023Preference-based feedback is important for many applications where direct evaluation of a reward function is not feasible. A notable recent example arises in reinforcement learning from human feedback on large language models. For many of these applications, the cost of acquiring the human feedback can be substantial or even prohibitive. In this work, we take advantage of the fact that often the agent can choose contexts at which to obtain human feedback in order to most efficiently identify a good policy, and introduce the offline contextual dueling bandit setting. We give an upper-confidence-bound style algorithm for this setting and prove a regret bound. We also give empirical confirmation that this method outperforms a similar strategy that uses uniformly sampled contexts.
Best Arm Identification under Additive Transfer Bandits
Dec 08, 2021We consider a variant of the best arm identification (BAI) problem in multi-armed bandits (MAB) in which there are two sets of arms (source and target), and the objective is to determine the best target arm while only pulling source arms. In this paper, we study the setting when, despite the means being unknown, there is a known additive relationship between the source and target MAB instances. We show how our framework covers a range of previously studied pure exploration problems and additionally captures new problems. We propose and theoretically analyze an LUCB-style algorithm to identify an $\epsilon$-optimal target arm with high probability. Our theoretical analysis highlights aspects of this transfer learning problem that do not arise in the typical BAI setup, and yet recover the LUCB algorithm for single domain BAI as a special case.
A Design Methodology for Efficient Implementation of Deconvolutional Neural Networks on an FPGA
May 07, 2017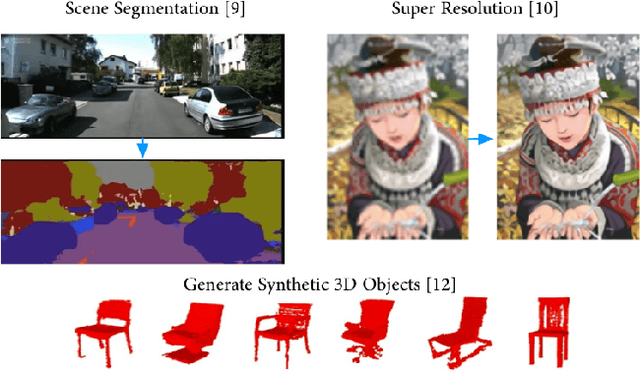



In recent years deep learning algorithms have shown extremely high performance on machine learning tasks such as image classification and speech recognition. In support of such applications, various FPGA accelerator architectures have been proposed for convolutional neural networks (CNNs) that enable high performance for classification tasks at lower power than CPU and GPU processors. However, to date, there has been little research on the use of FPGA implementations of deconvolutional neural networks (DCNNs). DCNNs, also known as generative CNNs, encode high-dimensional probability distributions and have been widely used for computer vision applications such as scene completion, scene segmentation, image creation, image denoising, and super-resolution imaging. We propose an FPGA architecture for deconvolutional networks built around an accelerator which effectively handles the complex memory access patterns needed to perform strided deconvolutions, and that supports convolution as well. We also develop a three-step design optimization method that systematically exploits statistical analysis, design space exploration and VLSI optimization. To verify our FPGA deconvolutional accelerator design methodology we train DCNNs offline on two representative datasets using the generative adversarial network method (GAN) run on Tensorflow, and then map these DCNNs to an FPGA DCNN-plus-accelerator implementation to perform generative inference on a Xilinx Zynq-7000 FPGA. Our DCNN implementation achieves a peak performance density of 0.012 GOPs/DSP.
A Nonparametric Framework for Quantifying Generative Inference on Neuromorphic Systems
Feb 18, 2016


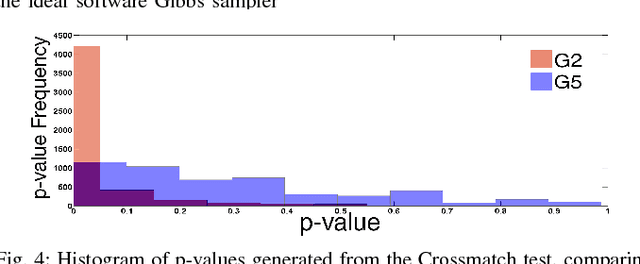
Restricted Boltzmann Machines and Deep Belief Networks have been successfully used in probabilistic generative model applications such as image occlusion removal, pattern completion and motion synthesis. Generative inference in such algorithms can be performed very efficiently on hardware using a Markov Chain Monte Carlo procedure called Gibbs sampling, where stochastic samples are drawn from noisy integrate and fire neurons implemented on neuromorphic substrates. Currently, no satisfactory metrics exist for evaluating the generative performance of such algorithms implemented on high-dimensional data for neuromorphic platforms. This paper demonstrates the application of nonparametric goodness-of-fit testing to both quantify the generative performance as well as provide decision-directed criteria for choosing the parameters of the neuromorphic Gibbs sampler and optimizing usage of hardware resources used during sampling.