 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Review of Causal Reasoning Benchmarks for Large Language Models
Jul 10, 2024


Numerous benchmarks aim to evaluate the capabilities of Large Language Models (LLMs) for causal inference and reasoning. However, many of them can likely be solved through the retrieval of domain knowledge, questioning whether they achieve their purpose. In this review, we present a comprehensive overview of LLM benchmarks for causality. We highlight how recent benchmarks move towards a more thorough definition of causal reasoning by incorporating interventional or counterfactual reasoning. We derive a set of criteria that a useful benchmark or set of benchmarks should aim to satisfy. We hope this work will pave the way towards a general framework for the assessment of causal understanding in LLMs and the design of novel benchmarks.
Targeting Relative Risk Heterogeneity with Causal Forests
Sep 26, 2023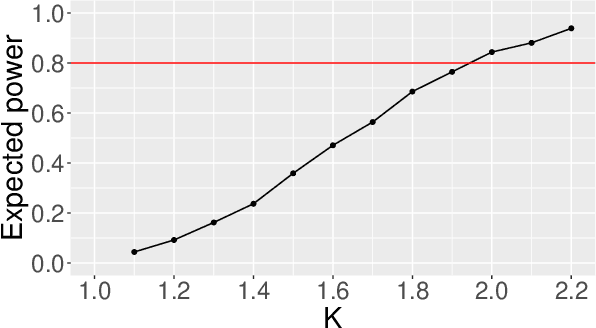
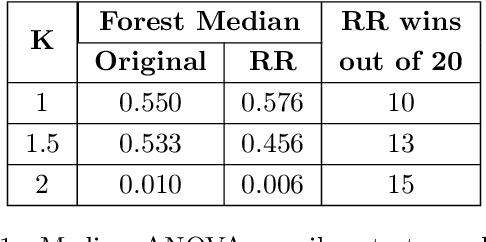
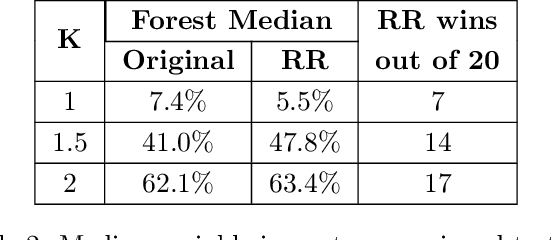
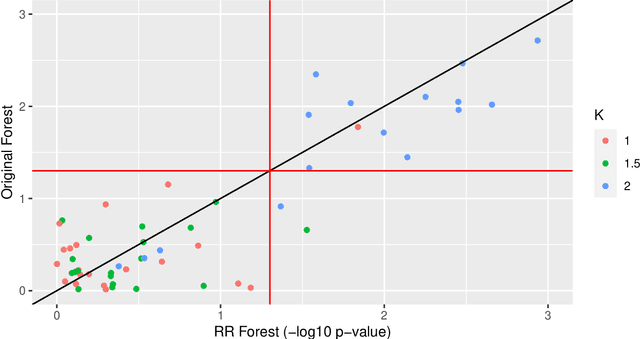
Treatment effect heterogeneity (TEH), or variability in treatment effect for different subgroups within a population, is of significant interest in clinical trial analysis. Causal forests (Wager and Athey, 2018) is a highly popular method for this problem, but like many other methods for detecting TEH, its criterion for separating subgroups focuses on differences in absolute risk. This can dilute statistical power by masking nuance in the relative risk, which is often a more appropriate quantity of clinical interest. In this work, we propose and implement a methodology for modifying causal forests to target relative risk using a novel node-splitting procedure based on generalized linear model (GLM) comparison. We present results on simulated and real-world data that suggest relative risk causal forests can capture otherwise unobserved sources of heterogeneity.
Social Determinants of Recidivism: A Machine Learning Solution
Dec 04, 2020



Current literature in criminal justice analytics often focuses on predicting the likelihood of recidivism (repeat offenses committed by released defendants), but this problem is fraught with ethical missteps ranging from selection bias in data collection to model interpretability. This paper re-purposes Machine Learning (ML) in criminal justice to identify social determinants of recidivism, with contributions along three dimensions. (1) We shift the focus from predicting which individuals will re-offend to identifying the broader underlying factors that explain differences in recidivism, with the goal of providing a reliable framework for preventative policy intervention. (2) Recidivism models typically agglomerate all individuals into one dataset to carry out ML tasks. We instead apply unsupervised learning to reduce noise and extract homogeneous subgroups of individuals, with a novel heuristic to find the optimal number of subgroups. (3) We subsequently apply supervised learning within the subgroups to determine statistically significant features that are correlated to recidivism. It is our view that this new approach to a long-standing question will serve as a useful guide for the practical application of ML in policymaking.