 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Fusion with Distributional Equivalence Test-then-pool
Mar 12, 2026Randomized controlled trials (RCTs) are the gold standard for causal inference, yet practical constraints often limit the size of the concurrent control arm. Borrowing control data from previous trials offers a potential efficiency gain, but naive borrowing can induce bias when historical and current populations differ. Existing test-then-pool (TTP) procedures address this concern by testing for equality of control outcomes between historical and concurrent trials before borrowing; however, standard implementations may suffer from reduced power or inadequate control of the Type-I error rate. We develop a new TTP framework that fuses control arms while rigorously controlling the Type-I error rate of the final treatment effect test. Our method employs kernel two-sample testing via maximum mean discrepancy (MMD) to capture distributional differences, and equivalence testing to avoid introducing uncontrolled bias, providing a more flexible and informative criterion for pooling. To ensure valid inference, we introduce partial bootstrap and partial permutation procedures for approximating null distributions in the presence of heterogeneous controls. We further establish the overall validity and consistency. We provide empirical studies demonstrating that the proposed approach achieves higher power than standard TTP methods while maintaining nominal error control, highlighting its value as a principled tool for leveraging historical controls in modern clinical trials.
Testing Generalizability in Causal Inference
Nov 05, 2024
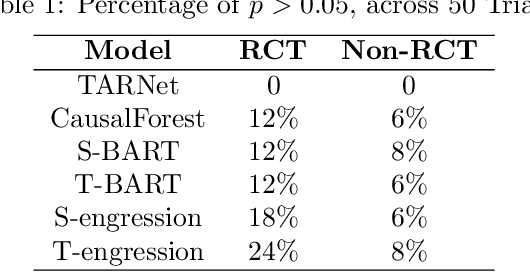


Ensuring robust model performance across diverse real-world scenarios requires addressing both transportability across domains with covariate shifts and extrapolation beyond observed data ranges. However, there is no formal procedure for statistically evaluating generalizability in machine learning algorithms, particularly in causal inference. Existing methods often rely on arbitrary metrics like AUC or MSE and focus predominantly on toy datasets, providing limited insights into real-world applicability. To address this gap, we propose a systematic and quantitative framework for evaluating model generalizability under covariate distribution shifts, specifically within causal inference settings. Our approach leverages the frugal parameterization, allowing for flexible simulations from fully and semi-synthetic benchmarks, offering comprehensive evaluations for both mean and distributional regression methods. By basing simulations on real data, our method ensures more realistic evaluations, which is often missing in current work relying on simplified datasets. Furthermore, using simulations and statistical testing, our framework is robust and avoids over-reliance on conventional metrics. Grounded in real-world data, it provides realistic insights into model performance, bridging the gap between synthetic evaluations and practical applications.
A Critical Review of Causal Reasoning Benchmarks for Large Language Models
Jul 10, 2024


Numerous benchmarks aim to evaluate the capabilities of Large Language Models (LLMs) for causal inference and reasoning. However, many of them can likely be solved through the retrieval of domain knowledge, questioning whether they achieve their purpose. In this review, we present a comprehensive overview of LLM benchmarks for causality. We highlight how recent benchmarks move towards a more thorough definition of causal reasoning by incorporating interventional or counterfactual reasoning. We derive a set of criteria that a useful benchmark or set of benchmarks should aim to satisfy. We hope this work will pave the way towards a general framework for the assessment of causal understanding in LLMs and the design of novel benchmarks.