 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Generalizability in Causal Inference
Nov 05, 2024
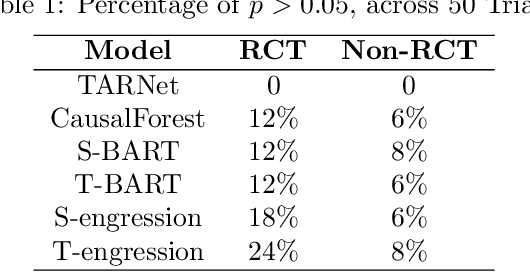


Ensuring robust model performance across diverse real-world scenarios requires addressing both transportability across domains with covariate shifts and extrapolation beyond observed data ranges. However, there is no formal procedure for statistically evaluating generalizability in machine learning algorithms, particularly in causal inference. Existing methods often rely on arbitrary metrics like AUC or MSE and focus predominantly on toy datasets, providing limited insights into real-world applicability. To address this gap, we propose a systematic and quantitative framework for evaluating model generalizability under covariate distribution shifts, specifically within causal inference settings. Our approach leverages the frugal parameterization, allowing for flexible simulations from fully and semi-synthetic benchmarks, offering comprehensive evaluations for both mean and distributional regression methods. By basing simulations on real data, our method ensures more realistic evaluations, which is often missing in current work relying on simplified datasets. Furthermore, using simulations and statistical testing, our framework is robust and avoids over-reliance on conventional metrics. Grounded in real-world data, it provides realistic insights into model performance, bridging the gap between synthetic evaluations and practical applications.
Marginal Causal Flows for Validation and Inference
Nov 02, 2024Investigating the marginal causal effect of an intervention on an outcome from complex data remains challenging due to the inflexibility of employed models and the lack of complexity in causal benchmark datasets, which often fail to reproduce intricate real-world data patterns. In this paper we introduce Frugal Flows, a novel likelihood-based machine learning model that uses normalising flows to flexibly learn the data-generating process, while also directly inferring the marginal causal quantities from observational data. We propose that these models are exceptionally well suited for generating synthetic data to validate causal methods. They can create synthetic datasets that closely resemble the empirical dataset, while automatically and exactly satisfying a user-defined average treatment effect. To our knowledge, Frugal Flows are the first generative model to both learn flexible data representations and also exactly parameterise quantities such as the average treatment effect and the degree of unobserved confounding. We demonstrate the above with experiments on both simulated and real-world datasets.
Stereotype and Skew: Quantifying Gender Bias in Pre-trained and Fine-tuned Language Models
Feb 16, 2021


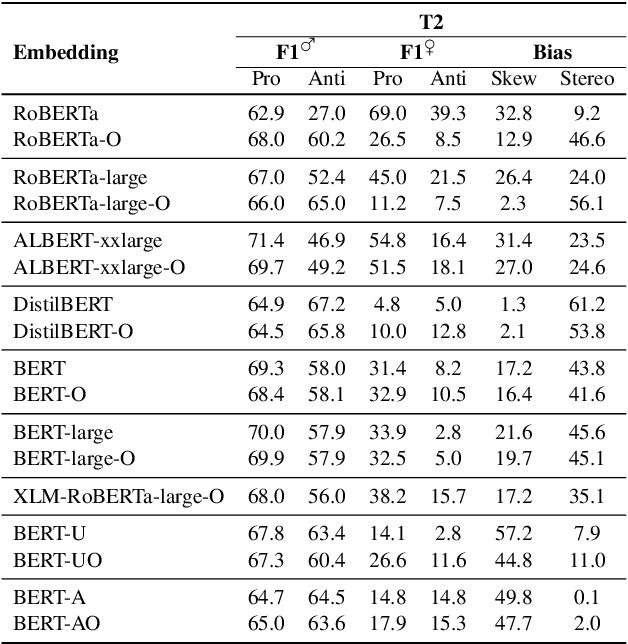
This paper proposes two intuitive metrics, skew and stereotype, that quantify and analyse the gender bias present in contextual language models when tackling the WinoBias pronoun resolution task. We find evidence that gender stereotype correlates approximately negatively with gender skew in out-of-the-box models, suggesting that there is a trade-off between these two forms of bias. We investigate two methods to mitigate bias. The first approach is an online method which is effective at removing skew at the expense of stereotype. The second, inspired by previous work on ELMo, involves the fine-tuning of BERT using an augmented gender-balanced dataset. We show that this reduces both skew and stereotype relative to its unaugmented fine-tuned counterpart. However, we find that existing gender bias benchmarks do not fully probe professional bias as pronoun resolution may be obfuscated by cross-correlations from other manifestations of gender prejudice. Our code is available online, at https://github.com/12kleingordon34/NLP_masters_project.