 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing interaction recovery of predicted protein-ligand poses
Sep 30, 2024The field of protein-ligand pose prediction has seen significant advances in recent years, with machine learning-based methods now being commonly used in lieu of classical docking methods or even to predict all-atom protein-ligand complex structures. Most contemporary studies focus on the accuracy and physical plausibility of ligand placement to determine pose quality, often neglecting a direct assessment of the interactions observed with the protein. In this work, we demonstrate that ignoring protein-ligand interaction fingerprints can lead to overestimation of model performance, most notably in recent protein-ligand cofolding models which often fail to recapitulate key interactions.
De novo antibody design with SE diffusion
May 13, 2024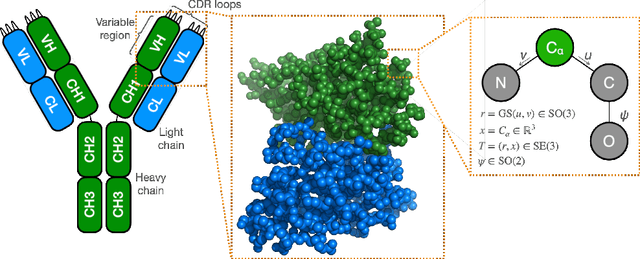



We introduce IgDiff, an antibody variable domain diffusion model based on a general protein backbone diffusion framework which was extended to handle multiple chains. Assessing the designability and novelty of the structures generated with our model, we find that IgDiff produces highly designable antibodies that can contain novel binding regions. The backbone dihedral angles of sampled structures show good agreement with a reference antibody distribution. We verify these designed antibodies experimentally and find that all express with high yield. Finally, we compare our model with a state-of-the-art generative backbone diffusion model on a range of antibody design tasks, such as the design of the complementarity determining regions or the pairing of a light chain to an existing heavy chain, and show improved properties and designability.
Stereotype and Skew: Quantifying Gender Bias in Pre-trained and Fine-tuned Language Models
Feb 16, 2021


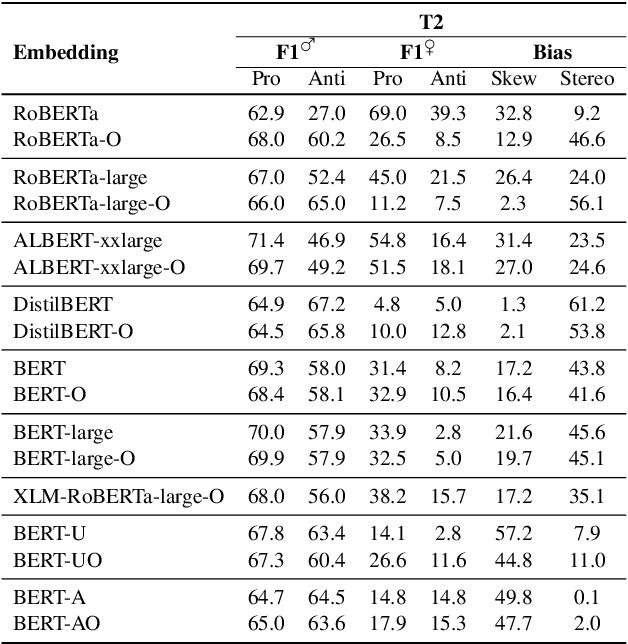
This paper proposes two intuitive metrics, skew and stereotype, that quantify and analyse the gender bias present in contextual language models when tackling the WinoBias pronoun resolution task. We find evidence that gender stereotype correlates approximately negatively with gender skew in out-of-the-box models, suggesting that there is a trade-off between these two forms of bias. We investigate two methods to mitigate bias. The first approach is an online method which is effective at removing skew at the expense of stereotype. The second, inspired by previous work on ELMo, involves the fine-tuning of BERT using an augmented gender-balanced dataset. We show that this reduces both skew and stereotype relative to its unaugmented fine-tuned counterpart. However, we find that existing gender bias benchmarks do not fully probe professional bias as pronoun resolution may be obfuscated by cross-correlations from other manifestations of gender prejudice. Our code is available online, at https://github.com/12kleingordon34/NLP_masters_project.