 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePicking: Learning Safe Object Extraction via Object-Level Mapping
Mar 01, 2022



Robots need object-level scene understanding to manipulate objects while reasoning about contact, support, and occlusion among objects. Given a pile of objects, object recognition and reconstruction can identify the boundary of object instances, giving important cues as to how the objects form and support the pile. In this work, we present a system, SafePicking, that integrates object-level mapping and learning-based motion planning to generate a motion that safely extracts occluded target objects from a pile. Planning is done by learning a deep Q-network that receives observations of predicted poses and a depth-based heightmap to output a motion trajectory, trained to maximize a safety metric reward. Our results show that the observation fusion of poses and depth-sensing gives both better performance and robustness to the model. We evaluate our methods using the YCB objects in both simulation and the real world, achieving safe object extraction from piles.
ReorientBot: Learning Object Reorientation for Specific-Posed Placement
Feb 22, 2022
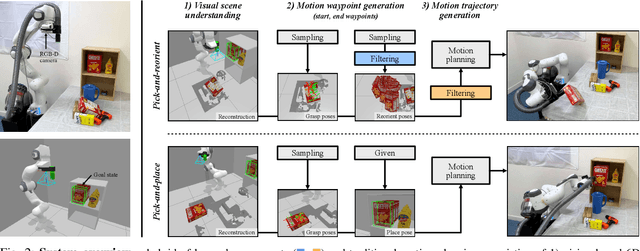
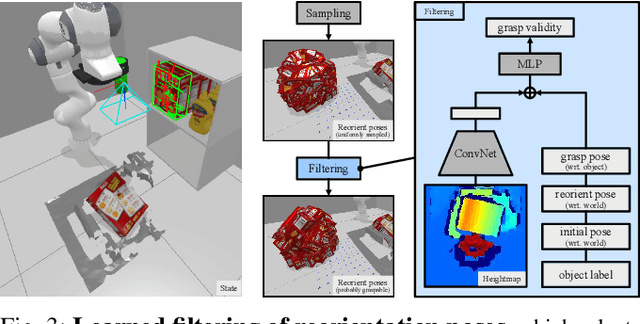
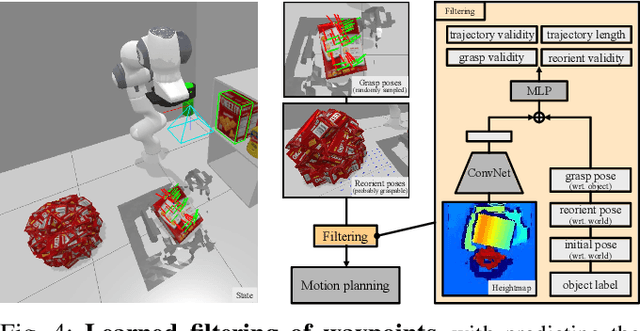
Robots need the capability of placing objects in arbitrary, specific poses to rearrange the world and achieve various valuable tasks. Object reorientation plays a crucial role in this as objects may not initially be oriented such that the robot can grasp and then immediately place them in a specific goal pose. In this work, we present a vision-based manipulation system, ReorientBot, which consists of 1) visual scene understanding with pose estimation and volumetric reconstruction using an onboard RGB-D camera; 2) learned waypoint selection for successful and efficient motion generation for reorientation; 3) traditional motion planning to generate a collision-free trajectory from the selected waypoints. We evaluate our method using the YCB objects in both simulation and the real world, achieving 93% overall success, 81% improvement in success rate, and 22% improvement in execution time compared to a heuristic approach. We demonstrate extended multi-object rearrangement showing the general capability of the system.
Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation
Jun 23, 2021
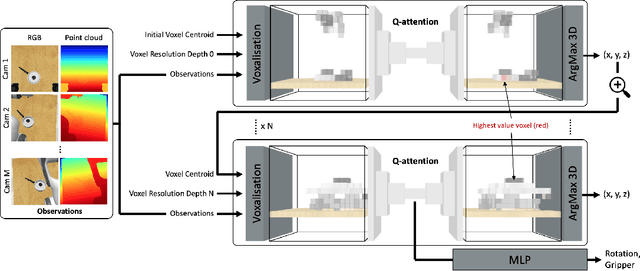
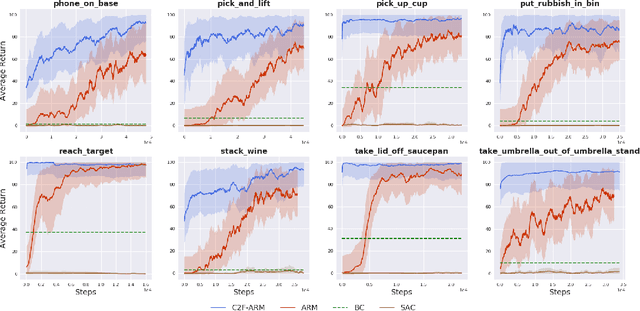
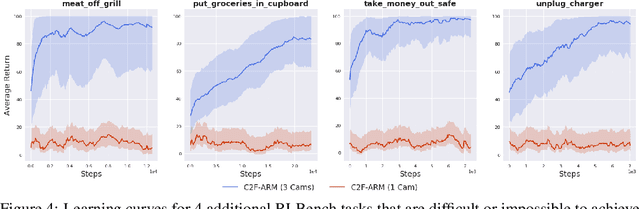
Reflecting on the last few years, the biggest breakthroughs in deep reinforcement learning (RL) have been in the discrete action domain. Robotic manipulation, however, is inherently a continuous control environment, but these continuous control reinforcement learning algorithms often depend on actor-critic methods that are sample-inefficient and inherently difficult to train, due to the joint optimisation of the actor and critic. To that end, we explore how we can bring the stability of discrete action RL algorithms to the robot manipulation domain. We extend the recently released ARM algorithm, by replacing the continuous next-best pose agent with a discrete next-best pose agent. Discretisation of rotation is trivial given its bounded nature, while translation is inherently unbounded, making discretisation difficult. We formulate the translation prediction as the voxel prediction problem by discretising the 3D space; however, voxelisation of a large workspace is memory intensive and would not work with a high density of voxels, crucial to obtaining the resolution needed for robotic manipulation. We therefore propose to apply this voxel prediction in a coarse-to-fine manner by gradually increasing the resolution. In each step, we extract the highest valued voxel as the predicted location, which is then used as the centre of the higher-resolution voxelisation in the next step. This coarse-to-fine prediction is applied over several steps, giving a near-lossless prediction of the translation. We show that our new coarse-to-fine algorithm is able to accomplish RLBench tasks much more efficiently than the continuous control equivalent, and even train some real-world tasks, tabular rasa, in less than 7 minutes, with only 3 demonstrations. Moreover, we show that by moving to a voxel representation, we are able to easily incorporate observations from multiple cameras.
Neural Object Descriptors for Multi-View Shape Reconstruction
Apr 09, 2020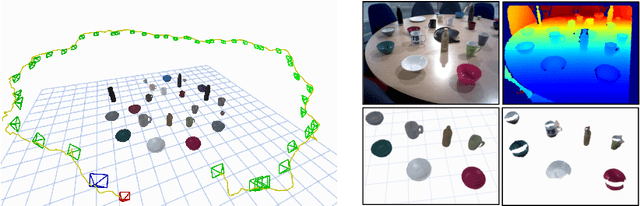
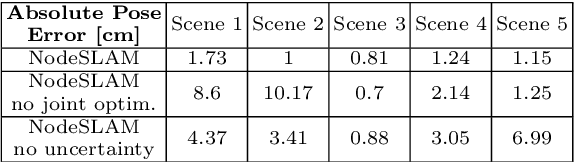
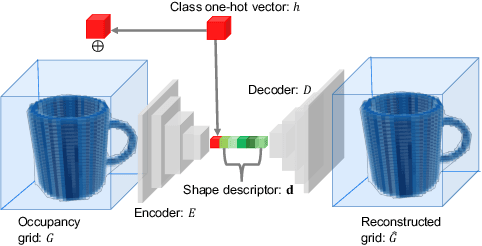
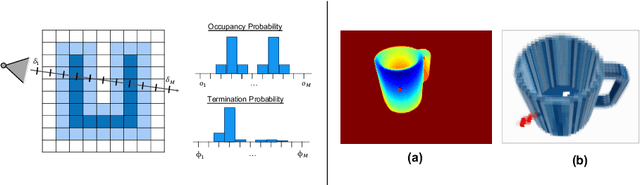
The choice of scene representation is crucial in both the shape inference algorithms it requires and the smart applications it enables. We present efficient and optimisable multi-class learned object descriptors together with a novel probabilistic and differential rendering engine, for principled full object shape inference from one or more RGB-D images. Our framework allows for accurate and robust 3D object reconstruction which enables multiple applications including robot grasping and placing, augmented reality, and the first object-level SLAM system capable of optimising object poses and shapes jointly with camera trajectory.
MoreFusion: Multi-object Reasoning for 6D Pose Estimation from Volumetric Fusion
Apr 09, 2020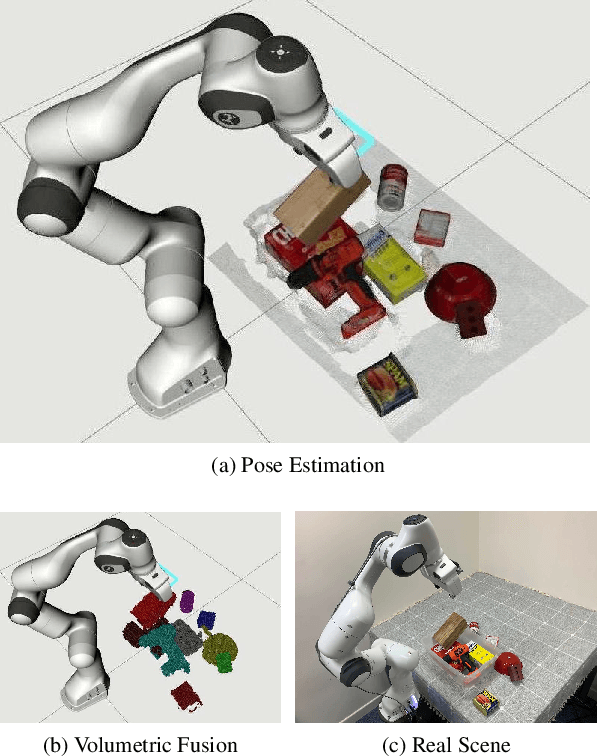
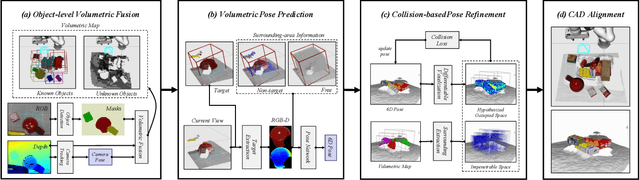
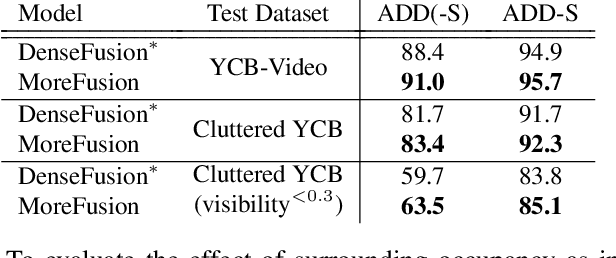

Robots and other smart devices need efficient object-based scene representations from their on-board vision systems to reason about contact, physics and occlusion. Recognized precise object models will play an important role alongside non-parametric reconstructions of unrecognized structures. We present a system which can estimate the accurate poses of multiple known objects in contact and occlusion from real-time, embodied multi-view vision. Our approach makes 3D object pose proposals from single RGB-D views, accumulates pose estimates and non-parametric occupancy information from multiple views as the camera moves, and performs joint optimization to estimate consistent, non-intersecting poses for multiple objects in contact. We verify the accuracy and robustness of our approach experimentally on 2 object datasets: YCB-Video, and our own challenging Cluttered YCB-Video. We demonstrate a real-time robotics application where a robot arm precisely and orderly disassembles complicated piles of objects, using only on-board RGB-D vision.
Joint Learning of Instance and Semantic Segmentation for Robotic Pick-and-Place with Heavy Occlusions in Clutter
Jan 21, 2020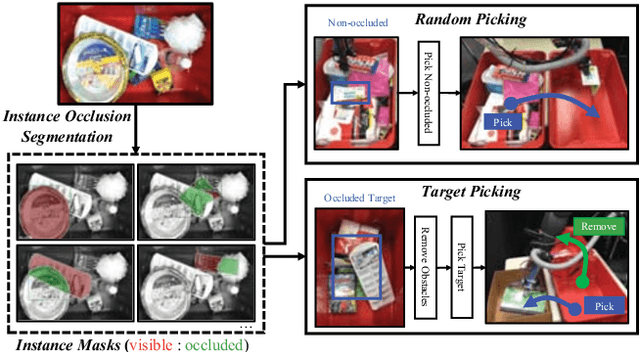



We present joint learning of instance and semantic segmentation for visible and occluded region masks. Sharing the feature extractor with instance occlusion segmentation, we introduce semantic occlusion segmentation into the instance segmentation model. This joint learning fuses the instance- and image-level reasoning of the mask prediction on the different segmentation tasks, which was missing in the previous work of learning instance segmentation only (instance-only). In the experiments, we evaluated the proposed joint learning comparing the instance-only learning on the test dataset. We also applied the joint learning model to 2 different types of robotic pick-and-place tasks (random and target picking) and evaluated its effectiveness to achieve real-world robotic tasks.
Instance Segmentation of Visible and Occluded Regions for Finding and Picking Target from a Pile of Objects
Jan 21, 2020



We present a robotic system for picking a target from a pile of objects that is capable of finding and grasping the target object by removing obstacles in the appropriate order. The fundamental idea is to segment instances with both visible and occluded masks, which we call `instance occlusion segmentation'. To achieve this, we extend an existing instance segmentation model with a novel `relook' architecture, in which the model explicitly learns the inter-instance relationship. Also, by using image synthesis, we make the system capable of handling new objects without human annotations. The experimental results show the effectiveness of the relook architecture when compared with a conventional model and of the image synthesis when compared to a human-annotated dataset. We also demonstrate the capability of our system to achieve picking a target in a cluttered environment with a real robot.
Probabilistic 3D Multilabel Real-time Mapping for Multi-object Manipulation
Jan 16, 2020
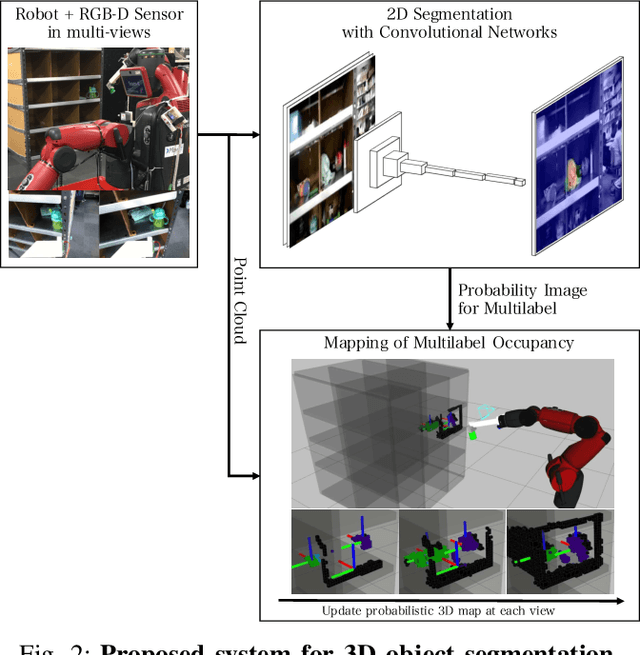


Probabilistic 3D map has been applied to object segmentation with multiple camera viewpoints, however, conventional methods lack of real-time efficiency and functionality of multilabel object mapping. In this paper, we propose a method to generate three-dimensional map with multilabel occupancy in real-time. Extending our previous work in which only target label occupancy is mapped, we achieve multilabel object segmentation in a single looking around action. We evaluate our method by testing segmentation accuracy with 39 different objects, and applying it to a manipulation task of multiple objects in the experiments. Our mapping-based method outperforms the conventional projection-based method by 40 - 96\% relative (12.6 mean $IU_{3d}$), and robot successfully recognizes (86.9\%) and manipulates multiple objects (60.7\%) in an environment with heavy occlusions.
3D Object Segmentation for Shelf Bin Picking by Humanoid with Deep Learning and Occupancy Voxel Grid Map
Jan 16, 2020

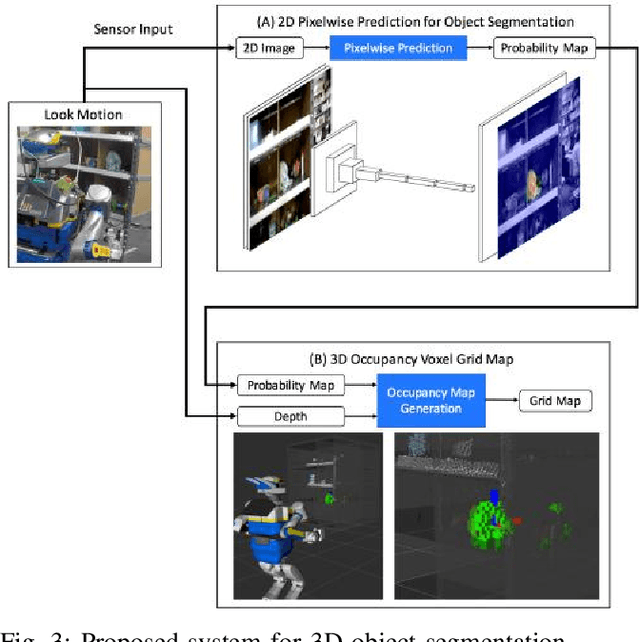
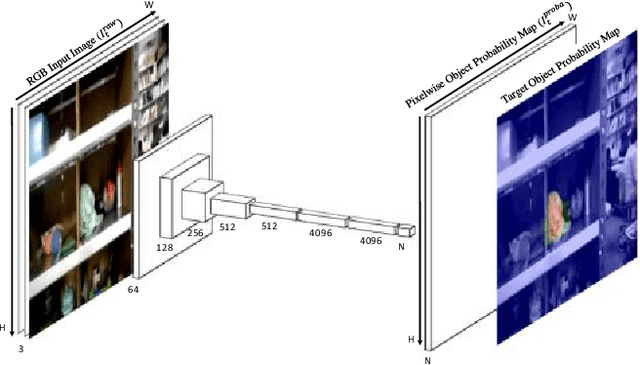
Picking objects in a narrow space such as shelf bins is an important task for humanoid to extract target object from environment. In those situations, however, there are many occlusions between the camera and objects, and this makes it difficult to segment the target object three dimensionally because of the lack of three dimentional sensor inputs. We address this problem with accumulating segmentation result with multiple camera angles, and generating voxel model of the target object. Our approach consists of two components: first is object probability prediction for input image with convolutional networks, and second is generating voxel grid map which is designed for object segmentation. We evaluated the method with the picking task experiment for target objects in narrow shelf bins. Our method generates dense 3D object segments even with occlusions, and the real robot successfuly picked target objects from the narrow space.