 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Instance and Semantic Segmentation for Robotic Pick-and-Place with Heavy Occlusions in Clutter
Paper and Code
Jan 21, 2020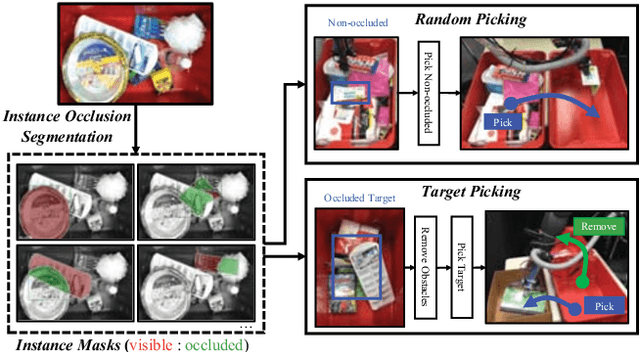



We present joint learning of instance and semantic segmentation for visible and occluded region masks. Sharing the feature extractor with instance occlusion segmentation, we introduce semantic occlusion segmentation into the instance segmentation model. This joint learning fuses the instance- and image-level reasoning of the mask prediction on the different segmentation tasks, which was missing in the previous work of learning instance segmentation only (instance-only). In the experiments, we evaluated the proposed joint learning comparing the instance-only learning on the test dataset. We also applied the joint learning model to 2 different types of robotic pick-and-place tasks (random and target picking) and evaluated its effectiveness to achieve real-world robotic tasks.