 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoWTracker: Tracking by Warping instead of Correlation
Feb 04, 2026Dense point tracking is a fundamental problem in computer vision, with applications ranging from video analysis to robotic manipulation. State-of-the-art trackers typically rely on cost volumes to match features across frames, but this approach incurs quadratic complexity in spatial resolution, limiting scalability and efficiency. In this paper, we propose \method, a novel dense point tracker that eschews cost volumes in favor of warping. Inspired by recent advances in optical flow, our approach iteratively refines track estimates by warping features from the target frame to the query frame based on the current estimate. Combined with a transformer architecture that performs joint spatiotemporal reasoning across all tracks, our design establishes long-range correspondences without computing feature correlations. Our model is simple and achieves state-of-the-art performance on standard dense point tracking benchmarks, including TAP-Vid-DAVIS, TAP-Vid-Kinetics, and Robo-TAP. Remarkably, the model also excels at optical flow, sometimes outperforming specialized methods on the Sintel, KITTI, and Spring benchmarks. These results suggest that warping-based architectures can unify dense point tracking and optical flow estimation.
V-DPM: 4D Video Reconstruction with Dynamic Point Maps
Jan 14, 2026Powerful 3D representations such as DUSt3R invariant point maps, which encode 3D shape and camera parameters, have significantly advanced feed forward 3D reconstruction. While point maps assume static scenes, Dynamic Point Maps (DPMs) extend this concept to dynamic 3D content by additionally representing scene motion. However, existing DPMs are limited to image pairs and, like DUSt3R, require post processing via optimization when more than two views are involved. We argue that DPMs are more useful when applied to videos and introduce V-DPM to demonstrate this. First, we show how to formulate DPMs for video input in a way that maximizes representational power, facilitates neural prediction, and enables reuse of pretrained models. Second, we implement these ideas on top of VGGT, a recent and powerful 3D reconstructor. Although VGGT was trained on static scenes, we show that a modest amount of synthetic data is sufficient to adapt it into an effective V-DPM predictor. Our approach achieves state of the art performance in 3D and 4D reconstruction for dynamic scenes. In particular, unlike recent dynamic extensions of VGGT such as P3, DPMs recover not only dynamic depth but also the full 3D motion of every point in the scene.
Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
Mar 20, 2025

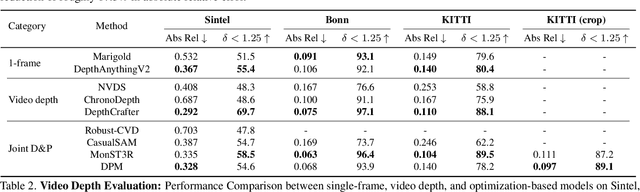

DUSt3R has recently shown that one can reduce many tasks in multi-view geometry, including estimating camera intrinsics and extrinsics, reconstructing the scene in 3D, and establishing image correspondences, to the prediction of a pair of viewpoint-invariant point maps, i.e., pixel-aligned point clouds defined in a common reference frame. This formulation is elegant and powerful, but unable to tackle dynamic scenes. To address this challenge, we introduce the concept of Dynamic Point Maps (DPM), extending standard point maps to support 4D tasks such as motion segmentation, scene flow estimation, 3D object tracking, and 2D correspondence. Our key intuition is that, when time is introduced, there are several possible spatial and time references that can be used to define the point maps. We identify a minimal subset of such combinations that can be regressed by a network to solve the sub tasks mentioned above. We train a DPM predictor on a mixture of synthetic and real data and evaluate it across diverse benchmarks for video depth prediction, dynamic point cloud reconstruction, 3D scene flow and object pose tracking, achieving state-of-the-art performance. Code, models and additional results are available at https://www.robots.ox.ac.uk/~vgg/research/dynamic-point-maps/.
Real-time Mapping of Physical Scene Properties with an Autonomous Robot Experimenter
Oct 31, 2022Neural fields can be trained from scratch to represent the shape and appearance of 3D scenes efficiently. It has also been shown that they can densely map correlated properties such as semantics, via sparse interactions from a human labeller. In this work, we show that a robot can densely annotate a scene with arbitrary discrete or continuous physical properties via its own fully-autonomous experimental interactions, as it simultaneously scans and maps it with an RGB-D camera. A variety of scene interactions are possible, including poking with force sensing to determine rigidity, measuring local material type with single-pixel spectroscopy or predicting force distributions by pushing. Sparse experimental interactions are guided by entropy to enable high efficiency, with tabletop scene properties densely mapped from scratch in a few minutes from a few tens of interactions.
Feature-Realistic Neural Fusion for Real-Time, Open Set Scene Understanding
Oct 06, 2022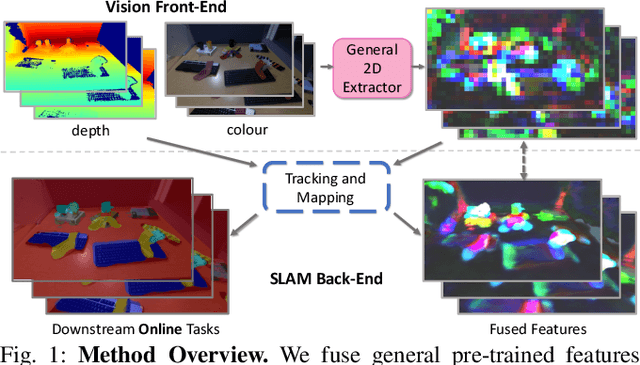


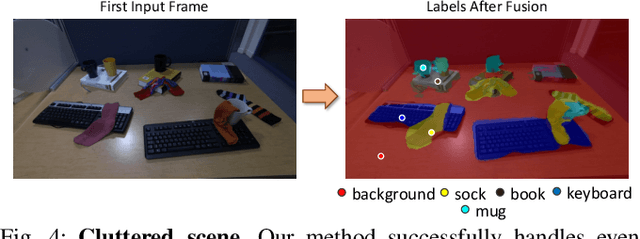
General scene understanding for robotics requires flexible semantic representation, so that novel objects and structures which may not have been known at training time can be identified, segmented and grouped. We present an algorithm which fuses general learned features from a standard pre-trained network into a highly efficient 3D geometric neural field representation during real-time SLAM. The fused 3D feature maps inherit the coherence of the neural field's geometry representation. This means that tiny amounts of human labelling interacting at runtime enable objects or even parts of objects to be robustly and accurately segmented in an open set manner.
iSDF: Real-Time Neural Signed Distance Fields for Robot Perception
Apr 05, 2022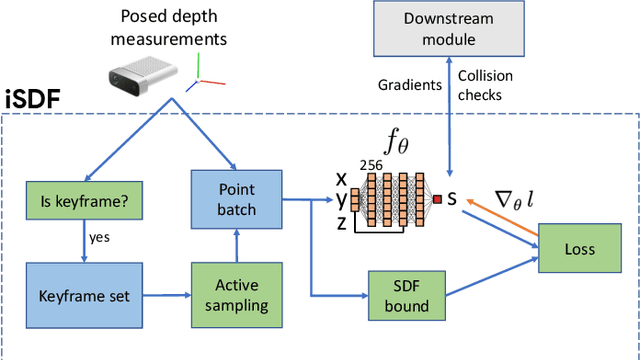
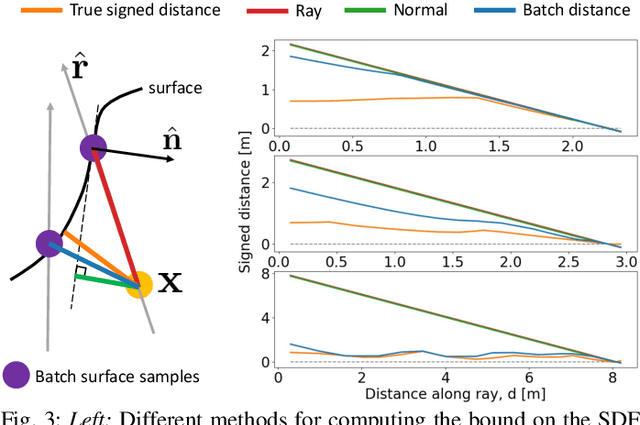
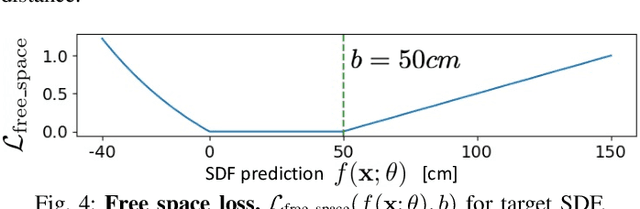
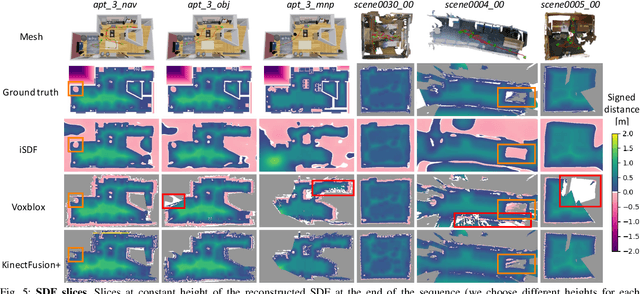
We present iSDF, a continual learning system for real-time signed distance field (SDF) reconstruction. Given a stream of posed depth images from a moving camera, it trains a randomly initialised neural network to map input 3D coordinate to approximate signed distance. The model is self-supervised by minimising a loss that bounds the predicted signed distance using the distance to the closest sampled point in a batch of query points that are actively sampled. In contrast to prior work based on voxel grids, our neural method is able to provide adaptive levels of detail with plausible filling in of partially observed regions and denoising of observations, all while having a more compact representation. In evaluations against alternative methods on real and synthetic datasets of indoor environments, we find that iSDF produces more accurate reconstructions, and better approximations of collision costs and gradients useful for downstream planners in domains from navigation to manipulation. Code and video results can be found at our project page: https://joeaortiz.github.io/iSDF/ .
ILabel: Interactive Neural Scene Labelling
Dec 03, 2021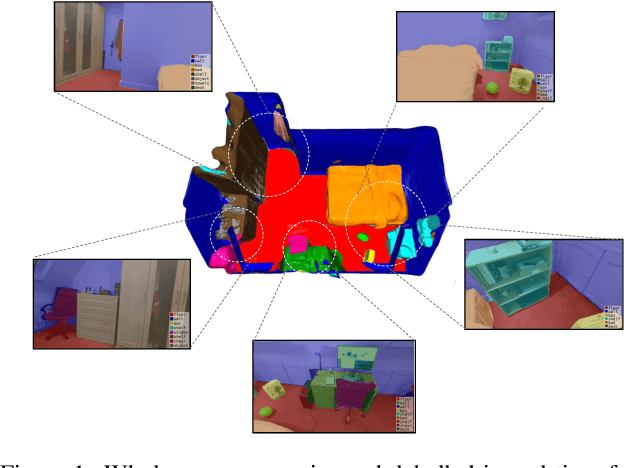
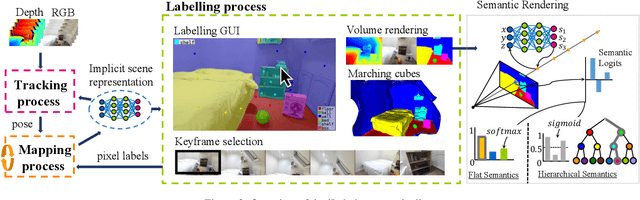
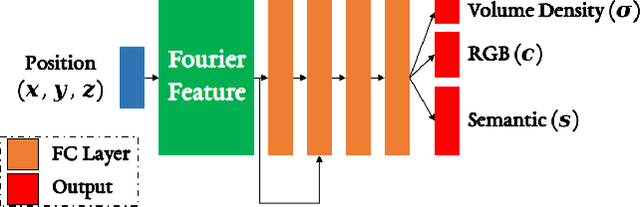
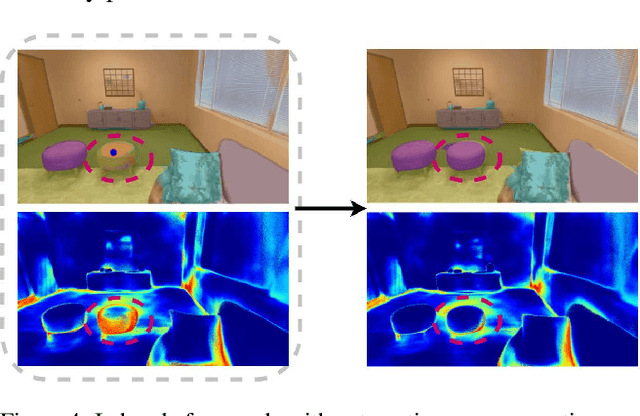
Joint representation of geometry, colour and semantics using a 3D neural field enables accurate dense labelling from ultra-sparse interactions as a user reconstructs a scene in real-time using a handheld RGB-D sensor. Our iLabel system requires no training data, yet can densely label scenes more accurately than standard methods trained on large, expensively labelled image datasets. Furthermore, it works in an 'open set' manner, with semantic classes defined on the fly by the user. ILabel's underlying model is a multilayer perceptron (MLP) trained from scratch in real-time to learn a joint neural scene representation. The scene model is updated and visualised in real-time, allowing the user to focus interactions to achieve efficient labelling. A room or similar scene can be accurately labelled into 10+ semantic categories with only a few tens of clicks. Quantitative labelling accuracy scales powerfully with the number of clicks, and rapidly surpasses standard pre-trained semantic segmentation methods. We also demonstrate a hierarchical labelling variant.
Incremental Abstraction in Distributed Probabilistic SLAM Graphs
Sep 13, 2021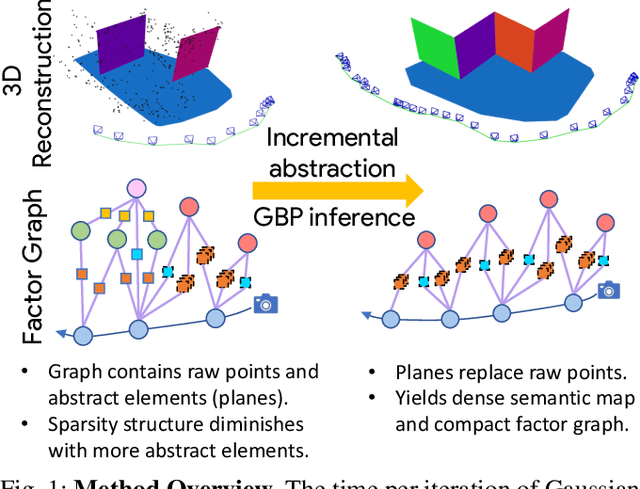
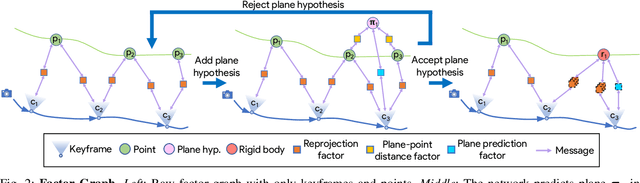
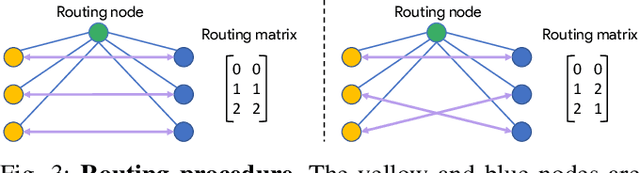
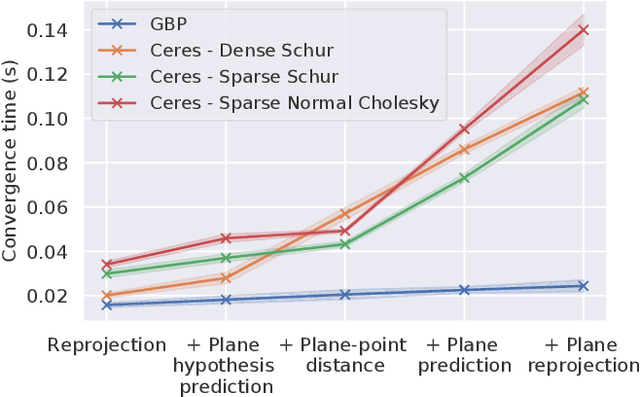
Scene graphs represent the key components of a scene in a compact and semantically rich way, but are difficult to build during incremental SLAM operation because of the challenges of robustly identifying abstract scene elements and optimising continually changing, complex graphs. We present a distributed, graph-based SLAM framework for incrementally building scene graphs based on two novel components. First, we propose an incremental abstraction framework in which a neural network proposes abstract scene elements that are incorporated into the factor graph of a feature-based monocular SLAM system. Scene elements are confirmed or rejected through optimisation and incrementally replace the points yielding a more dense, semantic and compact representation. Second, enabled by our novel routing procedure, we use Gaussian Belief Propagation (GBP) for distributed inference on a graph processor. The time per iteration of GBP is structure-agnostic and we demonstrate the speed advantages over direct methods for inference of heterogeneous factor graphs. We run our system on real indoor datasets using planar abstractions and recover the major planes with significant compression.
iMAP: Implicit Mapping and Positioning in Real-Time
Mar 23, 2021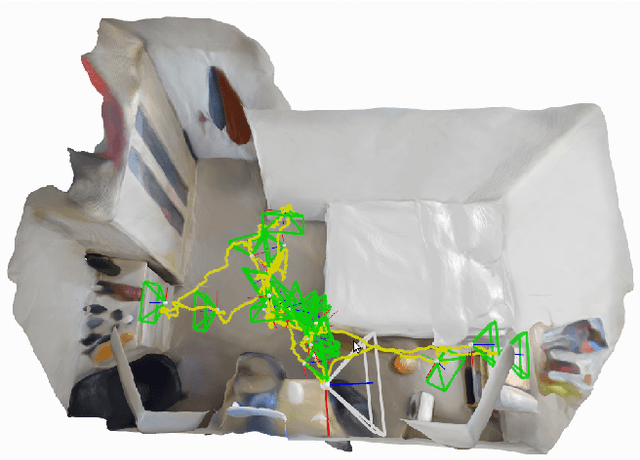

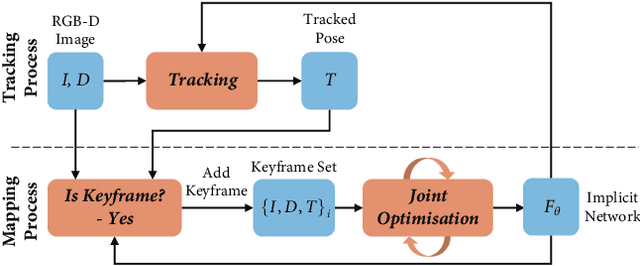

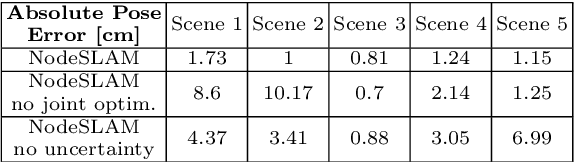
We show for the first time that a multilayer perceptron (MLP) can serve as the only scene representation in a real-time SLAM system for a handheld RGB-D camera. Our network is trained in live operation without prior data, building a dense, scene-specific implicit 3D model of occupancy and colour which is also immediately used for tracking. Achieving real-time SLAM via continual training of a neural network against a live image stream requires significant innovation. Our iMAP algorithm uses a keyframe structure and multi-processing computation flow, with dynamic information-guided pixel sampling for speed, with tracking at 10 Hz and global map updating at 2 Hz. The advantages of an implicit MLP over standard dense SLAM techniques include efficient geometry representation with automatic detail control and smooth, plausible filling-in of unobserved regions such as the back surfaces of objects.
Neural Object Descriptors for Multi-View Shape Reconstruction
Apr 09, 2020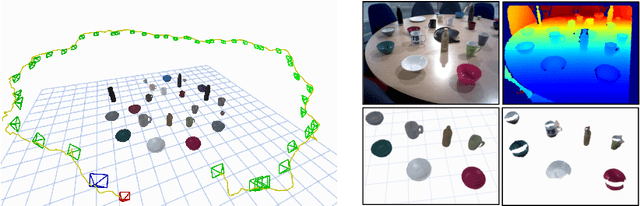
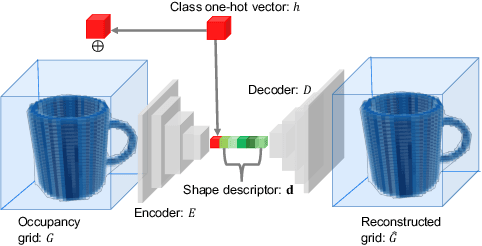
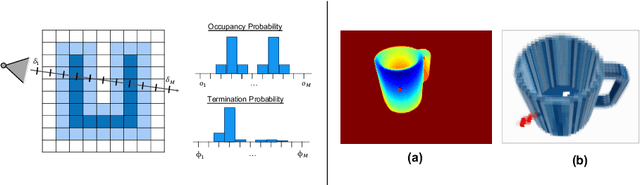
The choice of scene representation is crucial in both the shape inference algorithms it requires and the smart applications it enables. We present efficient and optimisable multi-class learned object descriptors together with a novel probabilistic and differential rendering engine, for principled full object shape inference from one or more RGB-D images. Our framework allows for accurate and robust 3D object reconstruction which enables multiple applications including robot grasping and placing, augmented reality, and the first object-level SLAM system capable of optimising object poses and shapes jointly with camera trajectory.