 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Mapping of Physical Scene Properties with an Autonomous Robot Experimenter
Oct 31, 2022Neural fields can be trained from scratch to represent the shape and appearance of 3D scenes efficiently. It has also been shown that they can densely map correlated properties such as semantics, via sparse interactions from a human labeller. In this work, we show that a robot can densely annotate a scene with arbitrary discrete or continuous physical properties via its own fully-autonomous experimental interactions, as it simultaneously scans and maps it with an RGB-D camera. A variety of scene interactions are possible, including poking with force sensing to determine rigidity, measuring local material type with single-pixel spectroscopy or predicting force distributions by pushing. Sparse experimental interactions are guided by entropy to enable high efficiency, with tabletop scene properties densely mapped from scratch in a few minutes from a few tens of interactions.
ILabel: Interactive Neural Scene Labelling
Dec 03, 2021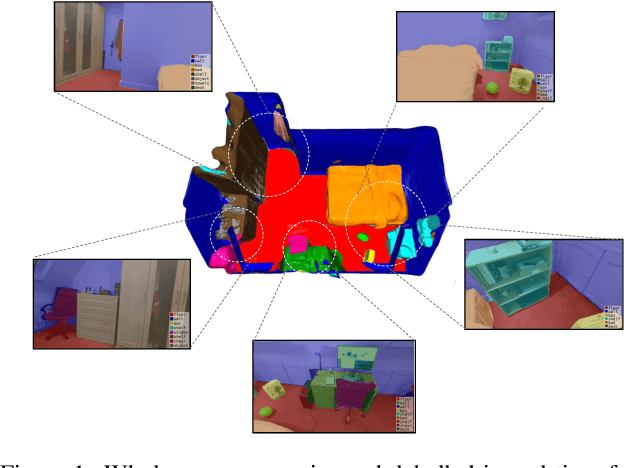
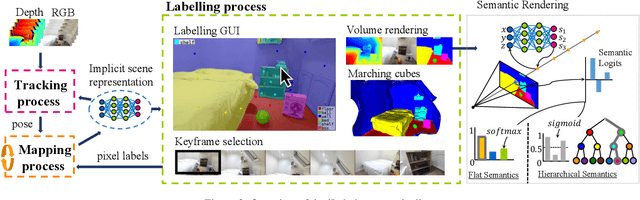
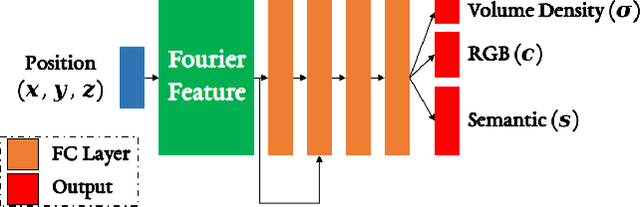
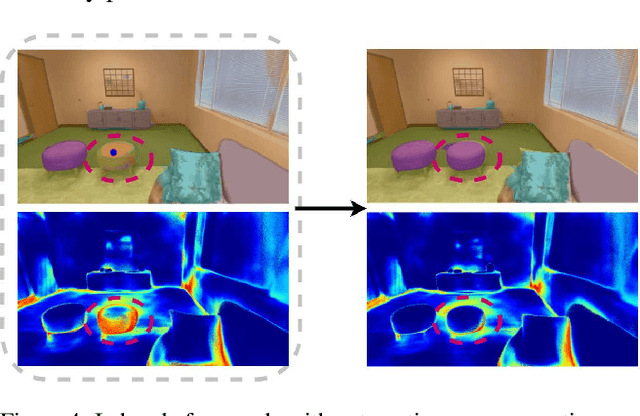
Joint representation of geometry, colour and semantics using a 3D neural field enables accurate dense labelling from ultra-sparse interactions as a user reconstructs a scene in real-time using a handheld RGB-D sensor. Our iLabel system requires no training data, yet can densely label scenes more accurately than standard methods trained on large, expensively labelled image datasets. Furthermore, it works in an 'open set' manner, with semantic classes defined on the fly by the user. ILabel's underlying model is a multilayer perceptron (MLP) trained from scratch in real-time to learn a joint neural scene representation. The scene model is updated and visualised in real-time, allowing the user to focus interactions to achieve efficient labelling. A room or similar scene can be accurately labelled into 10+ semantic categories with only a few tens of clicks. Quantitative labelling accuracy scales powerfully with the number of clicks, and rapidly surpasses standard pre-trained semantic segmentation methods. We also demonstrate a hierarchical labelling variant.