 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotics of Network Embeddings Learned via Subsampling
Paper and Code
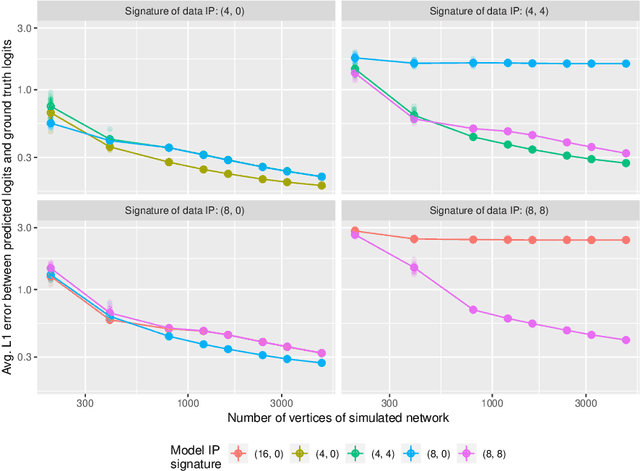
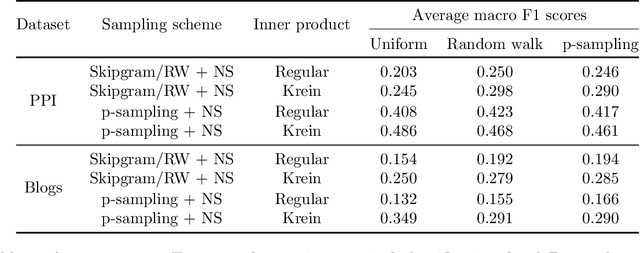
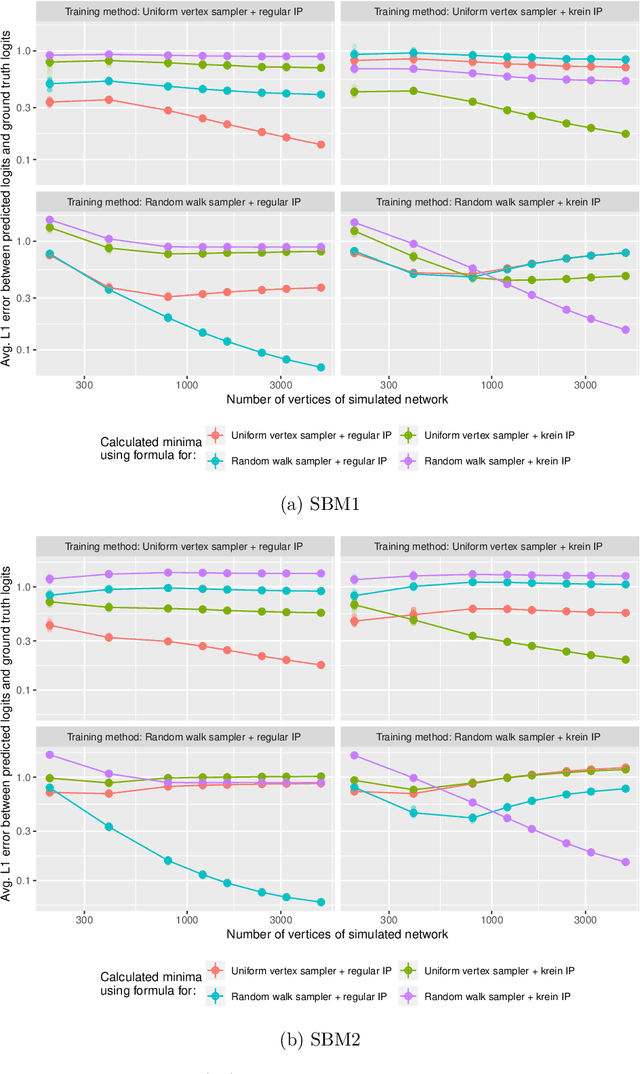
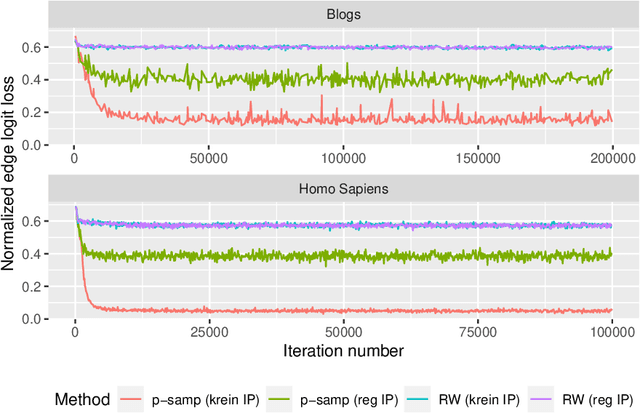
Network data are ubiquitous in modern machine learning, with tasks of interest including node classification, node clustering and link prediction. A frequent approach begins by learning an Euclidean embedding of the network, to which algorithms developed for vector-valued data are applied. For large networks, embeddings are learned using stochastic gradient methods where the sub-sampling scheme can be freely chosen. Despite the strong empirical performance of such methods, they are not well understood theoretically. Our work encapsulates representation methods using a subsampling approach, such as node2vec, into a single unifying framework. We prove, under the assumption that the graph is exchangeable, that the distribution of the learned embedding vectors asymptotically decouples. Moreover, we characterize the asymptotic distribution and provided rates of convergence, in terms of the latent parameters, which includes the choice of loss function and the embedding dimension. This provides a theoretical foundation to understand what the embedding vectors represent and how well these methods perform on downstream tasks. Notably, we observe that typically used loss functions may lead to shortcomings, such as a lack of Fisher consistency.