 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Mixture-of-Expert Inference with Adaptive Expert Split Mechanism
Sep 10, 2025


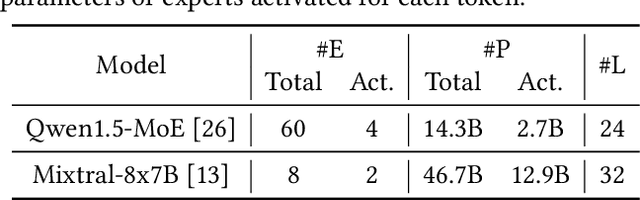
Mixture-of-Experts (MoE) has emerged as a promising architecture for modern large language models (LLMs). However, massive parameters impose heavy GPU memory (i.e., VRAM) demands, hindering the widespread adoption of MoE LLMs. Offloading the expert parameters to CPU RAM offers an effective way to alleviate the VRAM requirements for MoE inference. Existing approaches typically cache a small subset of experts in VRAM and dynamically prefetch experts from RAM during inference, leading to significant degradation in inference speed due to the poor cache hit rate and substantial expert loading latency. In this work, we propose MoEpic, an efficient MoE inference system with a novel expert split mechanism. Specifically, each expert is vertically divided into two segments: top and bottom. MoEpic caches the top segment of hot experts, so that more experts will be stored under the limited VRAM budget, thereby improving the cache hit rate. During each layer's inference, MoEpic predicts and prefetches the activated experts for the next layer. Since the top segments of cached experts are exempt from fetching, the loading time is reduced, which allows efficient transfer-computation overlap. Nevertheless, the performance of MoEpic critically depends on the cache configuration (i.e., each layer's VRAM budget and expert split ratio). To this end, we propose a divide-and-conquer algorithm based on fixed-point iteration for adaptive cache configuration. Extensive experiments on popular MoE LLMs demonstrate that MoEpic can save about half of the GPU cost, while lowering the inference latency by about 37.51%-65.73% compared to the baselines.
Efficient Federated Fine-Tuning of Large Language Models with Layer Dropout
Mar 13, 2025



Fine-tuning plays a crucial role in enabling pre-trained LLMs to evolve from general language comprehension to task-specific expertise. To preserve user data privacy, federated fine-tuning is often employed and has emerged as the de facto paradigm. However, federated fine-tuning is prohibitively inefficient due to the tension between LLM complexity and the resource constraint of end devices, incurring unaffordable fine-tuning overhead. Existing literature primarily utilizes parameter-efficient fine-tuning techniques to mitigate communication costs, yet computational and memory burdens continue to pose significant challenges for developers. This work proposes DropPEFT, an innovative federated PEFT framework that employs a novel stochastic transformer layer dropout method, enabling devices to deactivate a considerable fraction of LLMs layers during training, thereby eliminating the associated computational load and memory footprint. In DropPEFT, a key challenge is the proper configuration of dropout ratios for layers, as overhead and training performance are highly sensitive to this setting. To address this challenge, we adaptively assign optimal dropout-ratio configurations to devices through an exploration-exploitation strategy, achieving efficient and effective fine-tuning. Extensive experiments show that DropPEFT can achieve a 1.3-6.3\times speedup in model convergence and a 40%-67% reduction in memory footprint compared to state-of-the-art methods.
Caesar: A Low-deviation Compression Approach for Efficient Federated Learning
Dec 28, 2024Compression is an efficient way to relieve the tremendous communication overhead of federated learning (FL) systems. However, for the existing works, the information loss under compression will lead to unexpected model/gradient deviation for the FL training, significantly degrading the training performance, especially under the challenges of data heterogeneity and model obsolescence. To strike a delicate trade-off between model accuracy and traffic cost, we propose Caesar, a novel FL framework with a low-deviation compression approach. For the global model download, we design a greedy method to optimize the compression ratio for each device based on the staleness of the local model, ensuring a precise initial model for local training. Regarding the local gradient upload, we utilize the device's local data properties (\ie, sample volume and label distribution) to quantify its local gradient's importance, which then guides the determination of the gradient compression ratio. Besides, with the fine-grained batch size optimization, Caesar can significantly diminish the devices' idle waiting time under the synchronized barrier. We have implemented Caesar on two physical platforms with 40 smartphones and 80 NVIDIA Jetson devices. Extensive results show that Caesar can reduce the traffic costs by about 25.54%$\thicksim$37.88% compared to the compression-based baselines with the same target accuracy, while incurring only a 0.68% degradation in final test accuracy relative to the full-precision communication.
Fair Differentiable Neural Network Architecture Search for Long-Tailed Data with Self-Supervised Learning
Jun 19, 2024

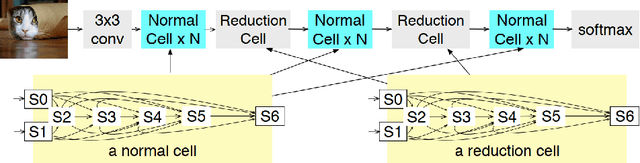

Recent advancements in artificial intelligence (AI) have positioned deep learning (DL) as a pivotal technology in fields like computer vision, data mining, and natural language processing. A critical factor in DL performance is the selection of neural network architecture. Traditional predefined architectures often fail to adapt to different data distributions, making it challenging to achieve optimal performance. Neural architecture search (NAS) offers a solution by automatically designing architectures tailored to specific datasets. However, the effectiveness of NAS diminishes on long-tailed datasets, where a few classes have abundant samples, and many have few, leading to biased models.In this paper, we explore to improve the searching and training performance of NAS on long-tailed datasets. Specifically, we first discuss the related works about NAS and the deep learning method for long-tailed datasets.Then, we focus on an existing work, called SSF-NAS, which integrates the self-supervised learning and fair differentiable NAS to making NAS achieve better performance on long-tailed datasets.An detailed description about the fundamental techniques for SSF-NAS is provided in this paper, including DARTS, FairDARTS, and Barlow Twins. Finally, we conducted a series of experiments on the CIFAR10-LT dataset for performance evaluation, where the results are align with our expectation.