 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Mixture-of-Expert Inference with Adaptive Expert Split Mechanism
Sep 10, 2025


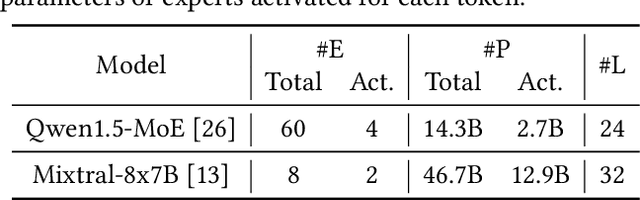
Mixture-of-Experts (MoE) has emerged as a promising architecture for modern large language models (LLMs). However, massive parameters impose heavy GPU memory (i.e., VRAM) demands, hindering the widespread adoption of MoE LLMs. Offloading the expert parameters to CPU RAM offers an effective way to alleviate the VRAM requirements for MoE inference. Existing approaches typically cache a small subset of experts in VRAM and dynamically prefetch experts from RAM during inference, leading to significant degradation in inference speed due to the poor cache hit rate and substantial expert loading latency. In this work, we propose MoEpic, an efficient MoE inference system with a novel expert split mechanism. Specifically, each expert is vertically divided into two segments: top and bottom. MoEpic caches the top segment of hot experts, so that more experts will be stored under the limited VRAM budget, thereby improving the cache hit rate. During each layer's inference, MoEpic predicts and prefetches the activated experts for the next layer. Since the top segments of cached experts are exempt from fetching, the loading time is reduced, which allows efficient transfer-computation overlap. Nevertheless, the performance of MoEpic critically depends on the cache configuration (i.e., each layer's VRAM budget and expert split ratio). To this end, we propose a divide-and-conquer algorithm based on fixed-point iteration for adaptive cache configuration. Extensive experiments on popular MoE LLMs demonstrate that MoEpic can save about half of the GPU cost, while lowering the inference latency by about 37.51%-65.73% compared to the baselines.
Mitigating Catastrophic Forgetting with Adaptive Transformer Block Expansion in Federated Fine-Tuning
Jun 06, 2025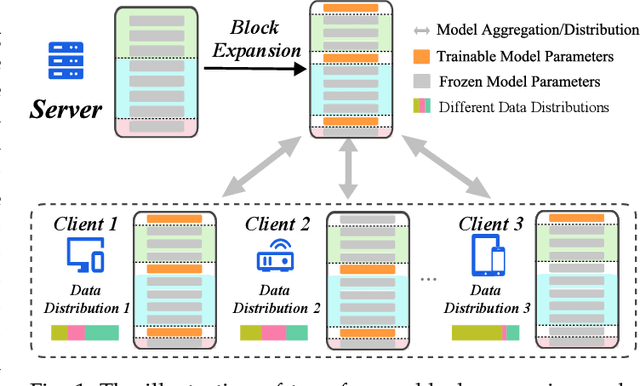
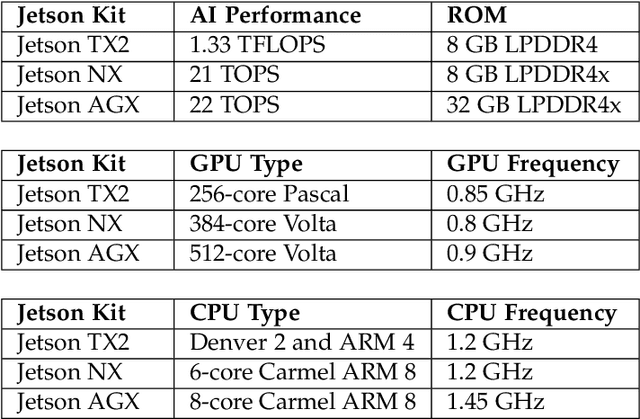
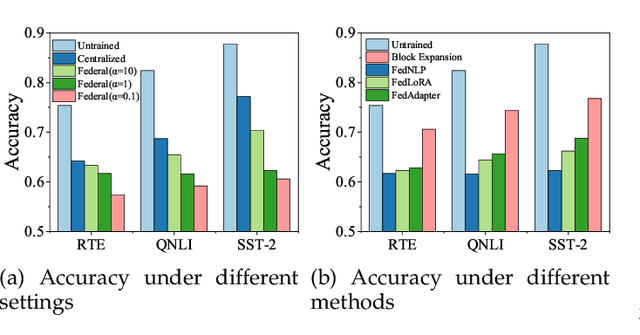
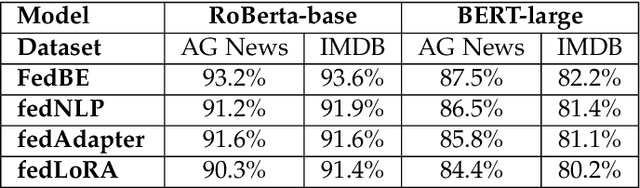
Federated fine-tuning (FedFT) of large language models (LLMs) has emerged as a promising solution for adapting models to distributed data environments while ensuring data privacy. Existing FedFT methods predominantly utilize parameter-efficient fine-tuning (PEFT) techniques to reduce communication and computation overhead. However, they often fail to adequately address the catastrophic forgetting, a critical challenge arising from continual adaptation in distributed environments. The traditional centralized fine-tuning methods, which are not designed for the heterogeneous and privacy-constrained nature of federated environments, struggle to mitigate this issue effectively. Moreover, the challenge is further exacerbated by significant variation in data distributions and device capabilities across clients, which leads to intensified forgetting and degraded model generalization. To tackle these issues, we propose FedBE, a novel FedFT framework that integrates an adaptive transformer block expansion mechanism with a dynamic trainable-block allocation strategy. Specifically, FedBE expands trainable blocks within the model architecture, structurally separating newly learned task-specific knowledge from the original pre-trained representations. Additionally, FedBE dynamically assigns these trainable blocks to clients based on their data distributions and computational capabilities. This enables the framework to better accommodate heterogeneous federated environments and enhances the generalization ability of the model.Extensive experiments show that compared with existing federated fine-tuning methods, FedBE achieves 12-74% higher accuracy retention on general tasks after fine-tuning and a model convergence acceleration ratio of 1.9-3.1x without degrading the accuracy of downstream tasks.
Collaborative Speculative Inference for Efficient LLM Inference Serving
Mar 13, 2025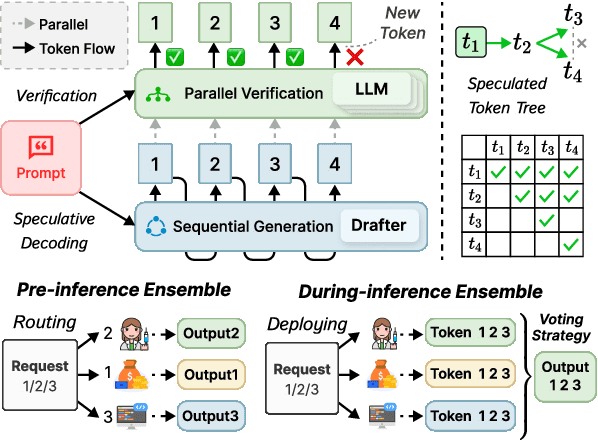
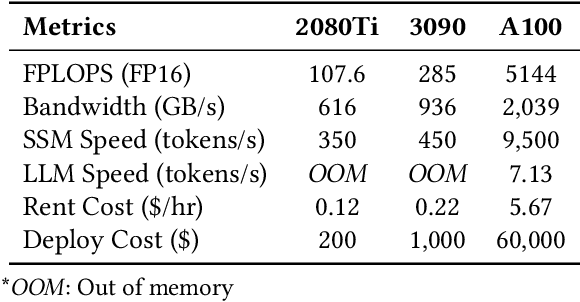
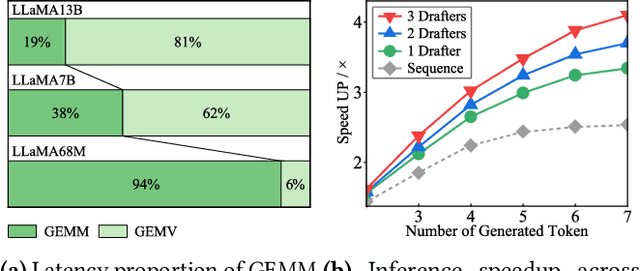
Speculative inference is a promising paradigm employing small speculative models (SSMs) as drafters to generate draft tokens, which are subsequently verified in parallel by the target large language model (LLM). This approach enhances the efficiency of inference serving by reducing LLM inference latency and costs while preserving generation quality. However, existing speculative methods face critical challenges, including inefficient resource utilization and limited draft acceptance, which constrain their scalability and overall effectiveness. To overcome these obstacles, we present CoSine, a novel speculative inference system that decouples sequential speculative decoding from parallel verification, enabling efficient collaboration among multiple nodes. Specifically, CoSine routes inference requests to specialized drafters based on their expertise and incorporates a confidence-based token fusion mechanism to synthesize outputs from cooperating drafters, ensuring high-quality draft generation. Additionally, CoSine dynamically orchestrates the execution of speculative decoding and verification in a pipelined manner, employing batch scheduling to selectively group requests and adaptive speculation control to minimize idle periods. By optimizing parallel workflows through heterogeneous node collaboration, CoSine balances draft generation and verification throughput in real-time, thereby maximizing resource utilization. Experimental results demonstrate that CoSine achieves superior performance compared to state-of-the-art speculative approaches. Notably, with equivalent resource costs, CoSine achieves up to a 23.2% decrease in latency and a 32.5% increase in throughput compared to baseline methods.
Caesar: A Low-deviation Compression Approach for Efficient Federated Learning
Dec 28, 2024Compression is an efficient way to relieve the tremendous communication overhead of federated learning (FL) systems. However, for the existing works, the information loss under compression will lead to unexpected model/gradient deviation for the FL training, significantly degrading the training performance, especially under the challenges of data heterogeneity and model obsolescence. To strike a delicate trade-off between model accuracy and traffic cost, we propose Caesar, a novel FL framework with a low-deviation compression approach. For the global model download, we design a greedy method to optimize the compression ratio for each device based on the staleness of the local model, ensuring a precise initial model for local training. Regarding the local gradient upload, we utilize the device's local data properties (\ie, sample volume and label distribution) to quantify its local gradient's importance, which then guides the determination of the gradient compression ratio. Besides, with the fine-grained batch size optimization, Caesar can significantly diminish the devices' idle waiting time under the synchronized barrier. We have implemented Caesar on two physical platforms with 40 smartphones and 80 NVIDIA Jetson devices. Extensive results show that Caesar can reduce the traffic costs by about 25.54%$\thicksim$37.88% compared to the compression-based baselines with the same target accuracy, while incurring only a 0.68% degradation in final test accuracy relative to the full-precision communication.
Enhancing Federated Graph Learning via Adaptive Fusion of Structural and Node Characteristics
Dec 25, 2024



Federated Graph Learning (FGL) has demonstrated the advantage of training a global Graph Neural Network (GNN) model across distributed clients using their local graph data. Unlike Euclidean data (\eg, images), graph data is composed of nodes and edges, where the overall node-edge connections determine the topological structure, and individual nodes along with their neighbors capture local node features. However, existing studies tend to prioritize one aspect over the other, leading to an incomplete understanding of the data and the potential misidentification of key characteristics across varying graph scenarios. Additionally, the non-independent and identically distributed (non-IID) nature of graph data makes the extraction of these two data characteristics even more challenging. To address the above issues, we propose a novel FGL framework, named FedGCF, which aims to simultaneously extract and fuse structural properties and node features to effectively handle diverse graph scenarios. FedGCF first clusters clients by structural similarity, performing model aggregation within each cluster to form the shared structural model. Next, FedGCF selects the clients with common node features and aggregates their models to generate a common node model. This model is then propagated to all clients, allowing common node features to be shared. By combining these two models with a proper ratio, FedGCF can achieve a comprehensive understanding of the graph data and deliver better performance, even under non-IID distributions. Experimental results show that FedGCF improves accuracy by 4.94%-7.24% under different data distributions and reduces communication cost by 64.18%-81.25% to reach the same accuracy compared to baselines.
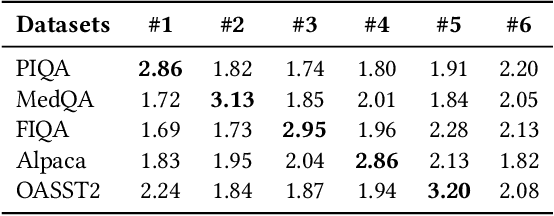
Top-$nσ$: Not All Logits Are You Need
Nov 12, 2024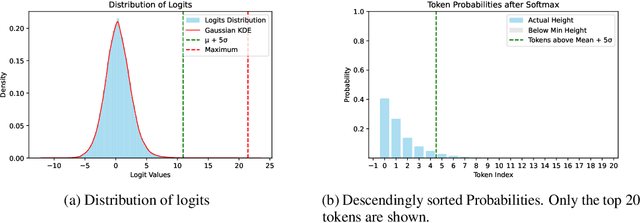

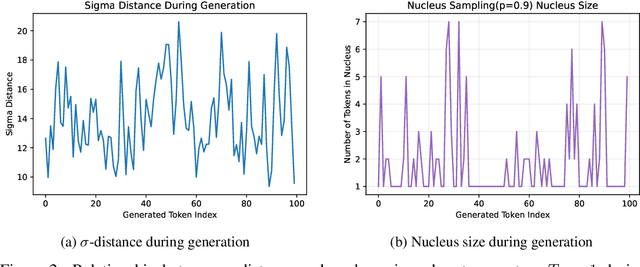
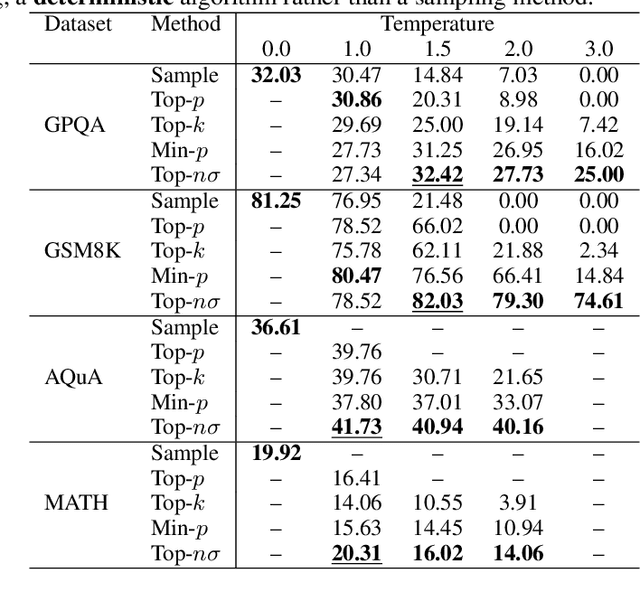
Large language models (LLMs) typically employ greedy decoding or low-temperature sampling for reasoning tasks, reflecting a perceived trade-off between diversity and accuracy. We challenge this convention by introducing top-$n\sigma$, a novel sampling method that operates directly on pre-softmax logits by leveraging a statistical threshold. Our key insight is that logits naturally separate into a Gaussian-distributed noisy region and a distinct informative region, enabling efficient token filtering without complex probability manipulations. Unlike existing methods (e.g., top-$p$, min-$p$) that inadvertently include more noise tokens at higher temperatures, top-$n\sigma$ maintains a stable sampling space regardless of temperature scaling. We also provide a theoretical analysis of top-$n\sigma$ to better understand its behavior. The extensive experimental results across four reasoning-focused datasets demonstrate that our method not only outperforms existing sampling approaches but also surpasses greedy decoding, while maintaining consistent performance even at high temperatures.
Segment as Points for Efficient Online Multi-Object Tracking and Segmentation
Jul 03, 2020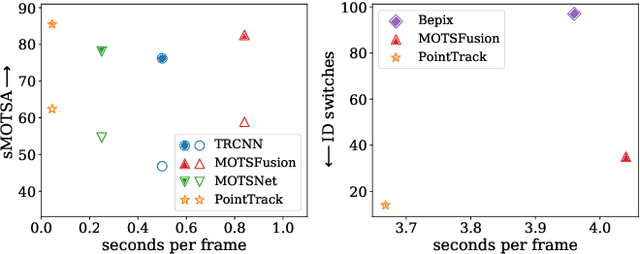

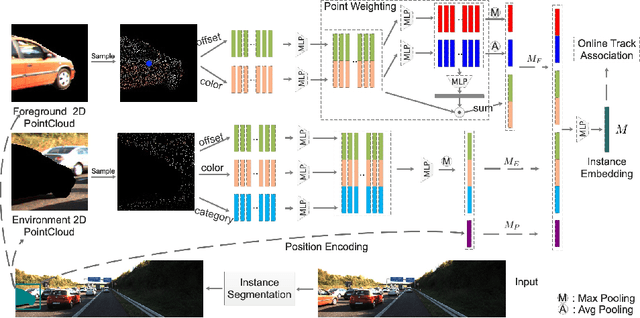
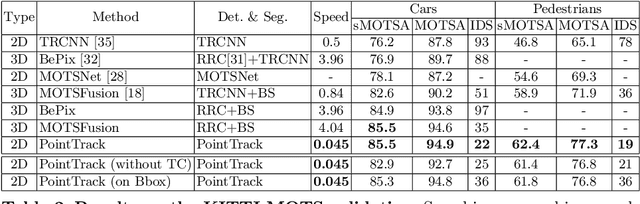
Current multi-object tracking and segmentation (MOTS) methods follow the tracking-by-detection paradigm and adopt convolutions for feature extraction. However, as affected by the inherent receptive field, convolution based feature extraction inevitably mixes up the foreground features and the background features, resulting in ambiguities in the subsequent instance association. In this paper, we propose a highly effective method for learning instance embeddings based on segments by converting the compact image representation to un-ordered 2D point cloud representation. Our method generates a new tracking-by-points paradigm where discriminative instance embeddings are learned from randomly selected points rather than images. Furthermore, multiple informative data modalities are converted into point-wise representations to enrich point-wise features. The resulting online MOTS framework, named PointTrack, surpasses all the state-of-the-art methods including 3D tracking methods by large margins (5.4% higher MOTSA and 18 times faster over MOTSFusion) with the near real-time speed (22 FPS). Evaluations across three datasets demonstrate both the effectiveness and efficiency of our method. Moreover, based on the observation that current MOTS datasets lack crowded scenes, we build a more challenging MOTS dataset named APOLLO MOTS with higher instance density. Both APOLLO MOTS and our codes are publicly available at https://github.com/detectRecog/PointTrack.
PointTrack++ for Effective Online Multi-Object Tracking and Segmentation
Jul 03, 2020
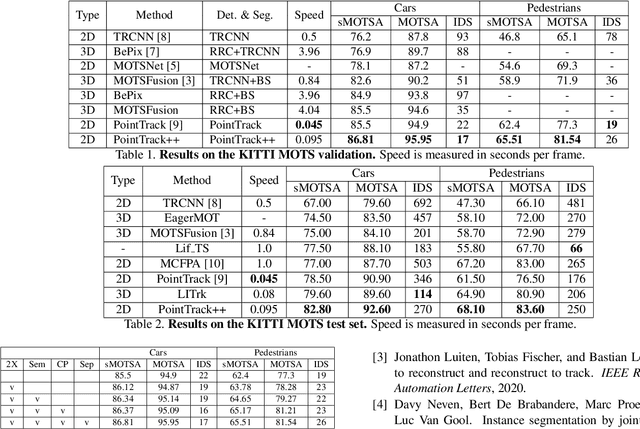
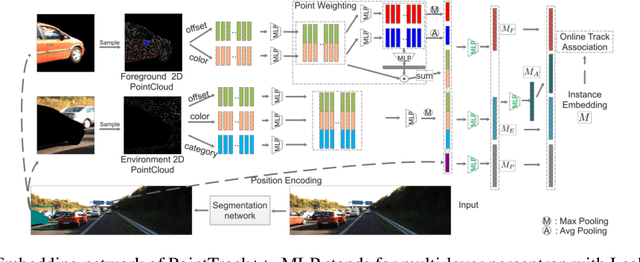
Multiple-object tracking and segmentation (MOTS) is a novel computer vision task that aims to jointly perform multiple object tracking (MOT) and instance segmentation. In this work, we present PointTrack++, an effective on-line framework for MOTS, which remarkably extends our recently proposed PointTrack framework. To begin with, PointTrack adopts an efficient one-stage framework for instance segmentation, and learns instance embeddings by converting compact image representations to un-ordered 2D point cloud. Compared with PointTrack, our proposed PointTrack++ offers three major improvements. Firstly, in the instance segmentation stage, we adopt a semantic segmentation decoder trained with focal loss to improve the instance selection quality. Secondly, to further boost the segmentation performance, we propose a data augmentation strategy by copy-and-paste instances into training images. Finally, we introduce a better training strategy in the instance association stage to improve the distinguishability of learned instance embeddings. The resulting framework achieves the state-of-the-art performance on the 5th BMTT MOTChallenge.
ZoomNet: Part-Aware Adaptive Zooming Neural Network for 3D Object Detection
Mar 01, 2020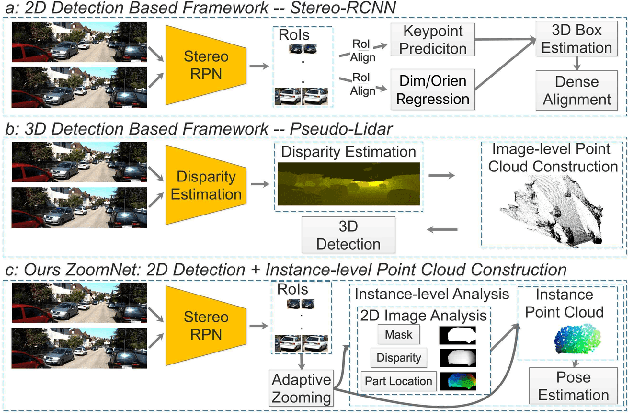
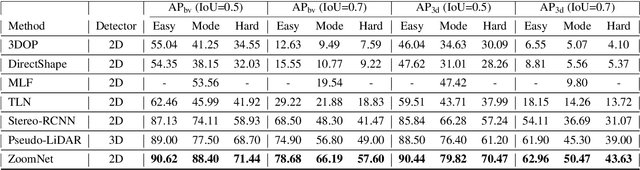
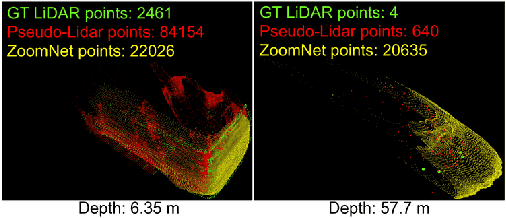
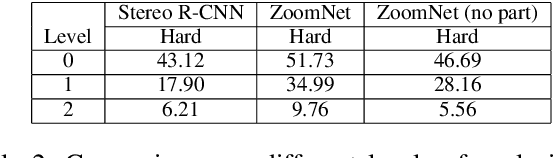
3D object detection is an essential task in autonomous driving and robotics. Though great progress has been made, challenges remain in estimating 3D pose for distant and occluded objects. In this paper, we present a novel framework named ZoomNet for stereo imagery-based 3D detection. The pipeline of ZoomNet begins with an ordinary 2D object detection model which is used to obtain pairs of left-right bounding boxes. To further exploit the abundant texture cues in RGB images for more accurate disparity estimation, we introduce a conceptually straight-forward module -- adaptive zooming, which simultaneously resizes 2D instance bounding boxes to a unified resolution and adjusts the camera intrinsic parameters accordingly. In this way, we are able to estimate higher-quality disparity maps from the resized box images then construct dense point clouds for both nearby and distant objects. Moreover, we introduce to learn part locations as complementary features to improve the resistance against occlusion and put forward the 3D fitting score to better estimate the 3D detection quality. Extensive experiments on the popular KITTI 3D detection dataset indicate ZoomNet surpasses all previous state-of-the-art methods by large margins (improved by 9.4% on APbv (IoU=0.7) over pseudo-LiDAR). Ablation study also demonstrates that our adaptive zooming strategy brings an improvement of over 10% on AP3d (IoU=0.7). In addition, since the official KITTI benchmark lacks fine-grained annotations like pixel-wise part locations, we also present our KFG dataset by augmenting KITTI with detailed instance-wise annotations including pixel-wise part location, pixel-wise disparity, etc.. Both the KFG dataset and our codes will be publicly available at https://github.com/detectRecog/ZoomNet.
Aggregating Votes with Local Differential Privacy: Usefulness, Soundness vs. Indistinguishability
Aug 14, 2019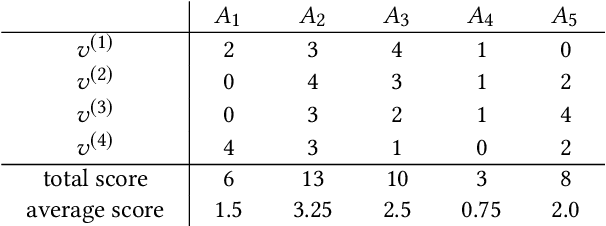
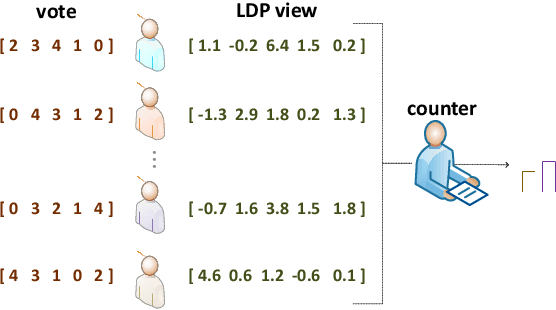

Voting plays a central role in bringing crowd wisdom to collective decision making, meanwhile data privacy has been a common ethical/legal issue in eliciting preferences from individuals. This work studies the problem of aggregating individual's voting data under the local differential privacy setting, where usefulness and soundness of the aggregated scores are of major concern. One naive approach to the problem is adding Laplace random noises, however, it makes aggregated scores extremely fragile to new types of strategic behaviors tailored to the local privacy setting: data amplification attack and view disguise attack. The data amplification attack means an attacker's manipulation power is amplified by the privacy-preserving procedure when contributing a fraud vote. The view disguise attack happens when an attacker could disguise malicious data as valid private views to manipulate the voting result. In this work, after theoretically quantifying the estimation error bound and the manipulating risk bound of the Laplace mechanism, we propose two mechanisms improving the usefulness and soundness simultaneously: the weighted sampling mechanism and the additive mechanism. The former one interprets the score vector as probabilistic data. Compared to the Laplace mechanism for Borda voting rule with $d$ candidates, it reduces the mean squared error bound by half and lowers the maximum magnitude risk bound from $+\infty$ to $O(\frac{d^3}{n\epsilon})$. The latter one randomly outputs a subset of candidates according to their total scores. Its mean squared error bound is optimized from $O(\frac{d^5}{n\epsilon^2})$ to $O(\frac{d^4}{n\epsilon^2})$, and its maximum magnitude risk bound is reduced to $O(\frac{d^2}{n\epsilon})$. Experimental results validate that our proposed approaches averagely reduce estimation error by $50\%$ and are more robust to adversarial attacks.