 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Votes with Local Differential Privacy: Usefulness, Soundness vs. Indistinguishability
Paper and Code
Aug 14, 2019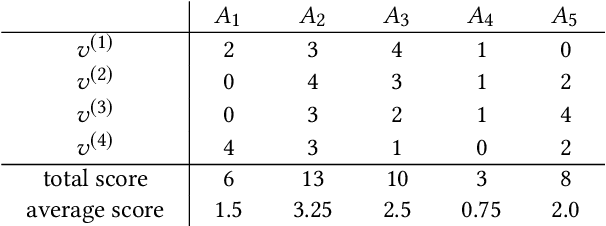
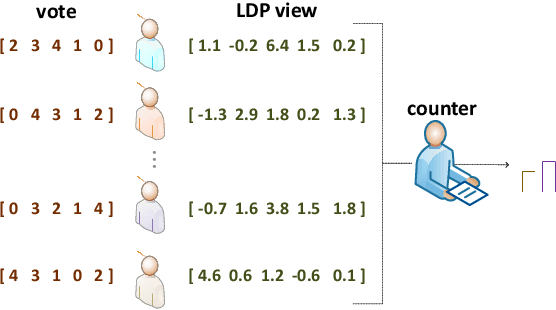

Voting plays a central role in bringing crowd wisdom to collective decision making, meanwhile data privacy has been a common ethical/legal issue in eliciting preferences from individuals. This work studies the problem of aggregating individual's voting data under the local differential privacy setting, where usefulness and soundness of the aggregated scores are of major concern. One naive approach to the problem is adding Laplace random noises, however, it makes aggregated scores extremely fragile to new types of strategic behaviors tailored to the local privacy setting: data amplification attack and view disguise attack. The data amplification attack means an attacker's manipulation power is amplified by the privacy-preserving procedure when contributing a fraud vote. The view disguise attack happens when an attacker could disguise malicious data as valid private views to manipulate the voting result. In this work, after theoretically quantifying the estimation error bound and the manipulating risk bound of the Laplace mechanism, we propose two mechanisms improving the usefulness and soundness simultaneously: the weighted sampling mechanism and the additive mechanism. The former one interprets the score vector as probabilistic data. Compared to the Laplace mechanism for Borda voting rule with $d$ candidates, it reduces the mean squared error bound by half and lowers the maximum magnitude risk bound from $+\infty$ to $O(\frac{d^3}{n\epsilon})$. The latter one randomly outputs a subset of candidates according to their total scores. Its mean squared error bound is optimized from $O(\frac{d^5}{n\epsilon^2})$ to $O(\frac{d^4}{n\epsilon^2})$, and its maximum magnitude risk bound is reduced to $O(\frac{d^2}{n\epsilon})$. Experimental results validate that our proposed approaches averagely reduce estimation error by $50\%$ and are more robust to adversarial attacks.