 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-$nσ$: Not All Logits Are You Need
Paper and Code
Nov 12, 2024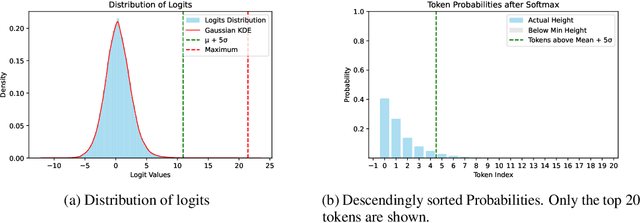

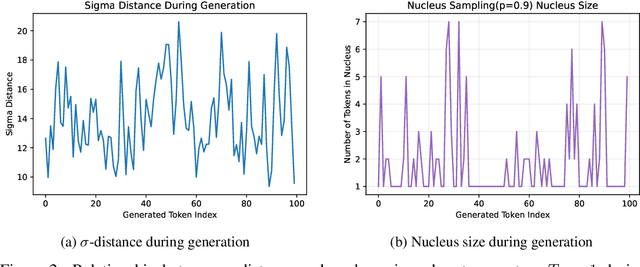
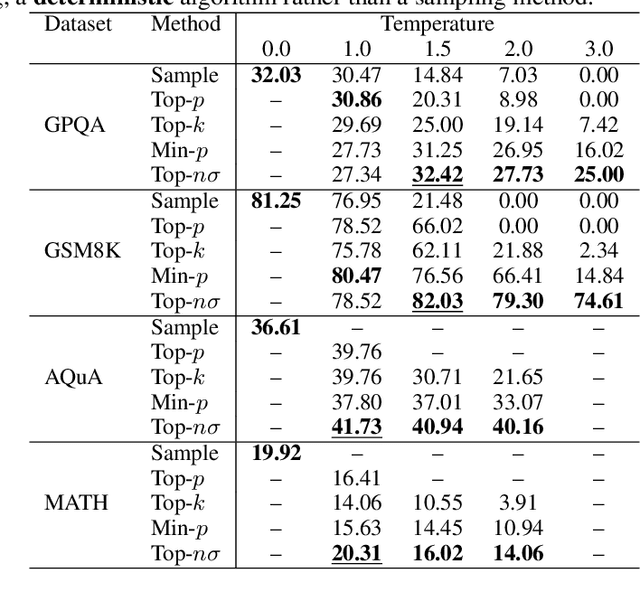
Large language models (LLMs) typically employ greedy decoding or low-temperature sampling for reasoning tasks, reflecting a perceived trade-off between diversity and accuracy. We challenge this convention by introducing top-$n\sigma$, a novel sampling method that operates directly on pre-softmax logits by leveraging a statistical threshold. Our key insight is that logits naturally separate into a Gaussian-distributed noisy region and a distinct informative region, enabling efficient token filtering without complex probability manipulations. Unlike existing methods (e.g., top-$p$, min-$p$) that inadvertently include more noise tokens at higher temperatures, top-$n\sigma$ maintains a stable sampling space regardless of temperature scaling. We also provide a theoretical analysis of top-$n\sigma$ to better understand its behavior. The extensive experimental results across four reasoning-focused datasets demonstrate that our method not only outperforms existing sampling approaches but also surpasses greedy decoding, while maintaining consistent performance even at high temperatures.