 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-$nσ$: Not All Logits Are You Need
Nov 12, 2024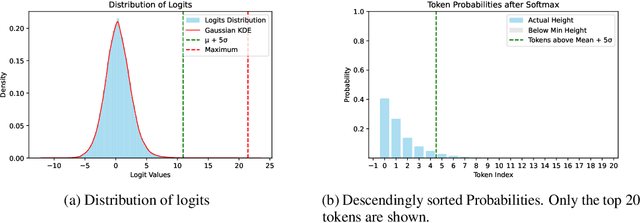

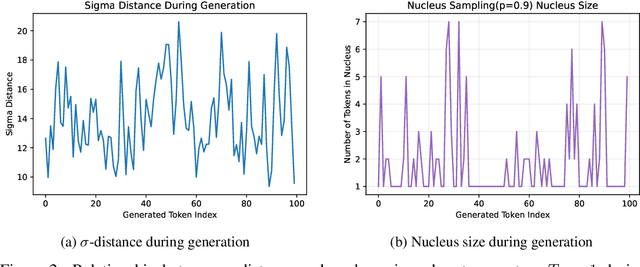
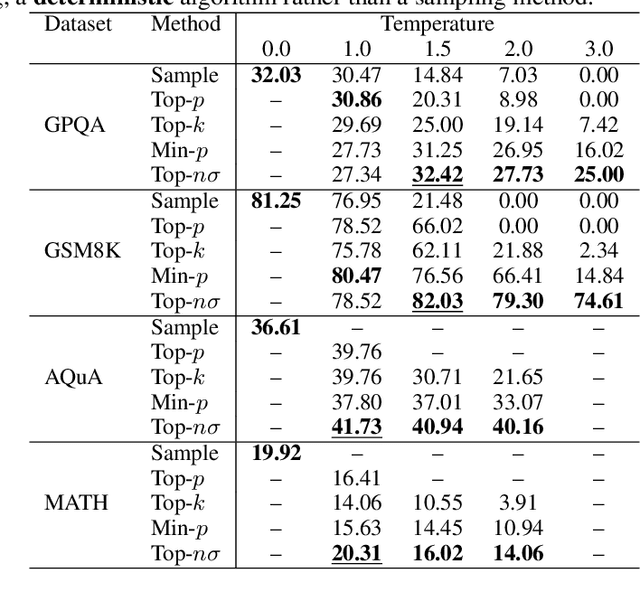
Large language models (LLMs) typically employ greedy decoding or low-temperature sampling for reasoning tasks, reflecting a perceived trade-off between diversity and accuracy. We challenge this convention by introducing top-$n\sigma$, a novel sampling method that operates directly on pre-softmax logits by leveraging a statistical threshold. Our key insight is that logits naturally separate into a Gaussian-distributed noisy region and a distinct informative region, enabling efficient token filtering without complex probability manipulations. Unlike existing methods (e.g., top-$p$, min-$p$) that inadvertently include more noise tokens at higher temperatures, top-$n\sigma$ maintains a stable sampling space regardless of temperature scaling. We also provide a theoretical analysis of top-$n\sigma$ to better understand its behavior. The extensive experimental results across four reasoning-focused datasets demonstrate that our method not only outperforms existing sampling approaches but also surpasses greedy decoding, while maintaining consistent performance even at high temperatures.
Heterogeneous Learning Rate Scheduling for Neural Architecture Search on Long-Tailed Datasets
Jun 11, 2024In this paper, we attempt to address the challenge of applying Neural Architecture Search (NAS) algorithms, specifically the Differentiable Architecture Search (DARTS), to long-tailed datasets where class distribution is highly imbalanced. We observe that traditional re-sampling and re-weighting techniques, which are effective in standard classification tasks, lead to performance degradation when combined with DARTS. To mitigate this, we propose a novel adaptive learning rate scheduling strategy tailored for the architecture parameters of DARTS when integrated with the Bilateral Branch Network (BBN) for handling imbalanced datasets. Our approach dynamically adjusts the learning rate of the architecture parameters based on the training epoch, preventing the disruption of well-trained representations in the later stages of training. Additionally, we explore the impact of branch mixing factors on the algorithm's performance. Through extensive experiments on the CIFAR-10 dataset with an artificially induced long-tailed distribution, we demonstrate that our method achieves comparable accuracy to using DARTS alone. And the experiment results suggest that re-sampling methods inherently harm the performance of the DARTS algorithm. Our findings highlight the importance of careful data augment when applying DNAS to imbalanced learning scenarios.