 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleash The Power of Pre-Trained Language Models for Irregularly Sampled Time Series
Paper and Code
Aug 12, 2024
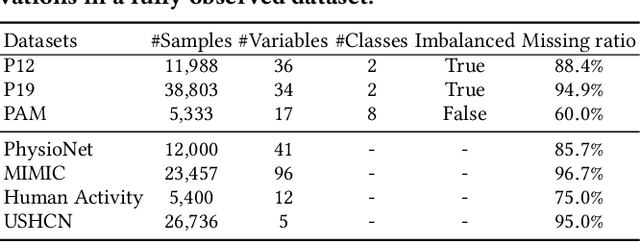


Pre-trained Language Models (PLMs), such as ChatGPT, have significantly advanced the field of natural language processing. This progress has inspired a series of innovative studies that explore the adaptation of PLMs to time series analysis, intending to create a unified foundation model that addresses various time series analytical tasks. However, these efforts predominantly focus on Regularly Sampled Time Series (RSTS), neglecting the unique challenges posed by Irregularly Sampled Time Series (ISTS), which are characterized by non-uniform sampling intervals and prevalent missing data. To bridge this gap, this work explores the potential of PLMs for ISTS analysis. We begin by investigating the effect of various methods for representing ISTS, aiming to maximize the efficacy of PLMs in this under-explored area. Furthermore, we present a unified PLM-based framework, ISTS-PLM, which integrates time-aware and variable-aware PLMs tailored for comprehensive intra and inter-time series modeling and includes a learnable input embedding layer and a task-specific output layer to tackle diverse ISTS analytical tasks. Extensive experiments on a comprehensive benchmark demonstrate that the ISTS-PLM, utilizing a simple yet effective series-based representation for ISTS, consistently achieves state-of-the-art performance across various analytical tasks, such as classification, interpolation, and extrapolation, as well as few-shot and zero-shot learning scenarios, spanning scientific domains like healthcare and biomechanics.