 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantization for Recommender Systems: A Review and Outlook
May 06, 2024Vector quantization, renowned for its unparalleled feature compression capabilities, has been a prominent topic in signal processing and machine learning research for several decades and remains widely utilized today. With the emergence of large models and generative AI, vector quantization has gained popularity in recommender systems, establishing itself as a preferred solution. This paper starts with a comprehensive review of vector quantization techniques. It then explores systematic taxonomies of vector quantization methods for recommender systems (VQ4Rec), examining their applications from multiple perspectives. Further, it provides a thorough introduction to research efforts in diverse recommendation scenarios, including efficiency-oriented approaches and quality-oriented approaches. Finally, the survey analyzes the remaining challenges and anticipates future trends in VQ4Rec, including the challenges associated with the training of vector quantization, the opportunities presented by large language models, and emerging trends in multimodal recommender systems. We hope this survey can pave the way for future researchers in the recommendation community and accelerate their exploration in this promising field.
Semi-supervised Domain Adaptation on Graphs with Contrastive Learning and Minimax Entropy
Sep 14, 2023



Label scarcity in a graph is frequently encountered in real-world applications due to the high cost of data labeling. To this end, semi-supervised domain adaptation (SSDA) on graphs aims to leverage the knowledge of a labeled source graph to aid in node classification on a target graph with limited labels. SSDA tasks need to overcome the domain gap between the source and target graphs. However, to date, this challenging research problem has yet to be formally considered by the existing approaches designed for cross-graph node classification. To tackle the SSDA problem on graphs, a novel method called SemiGCL is proposed, which benefits from graph contrastive learning and minimax entropy training. SemiGCL generates informative node representations by contrasting the representations learned from a graph's local and global views. Additionally, SemiGCL is adversarially optimized with the entropy loss of unlabeled target nodes to reduce domain divergence. Experimental results on benchmark datasets demonstrate that SemiGCL outperforms the state-of-the-art baselines on the SSDA tasks.
Co-evolving Vector Quantization for ID-based Recommendation
Sep 02, 2023Category information plays a crucial role in enhancing the quality and personalization of recommendations. Nevertheless, the availability of item category information is not consistently present, particularly in the context of ID-based recommendations. In this work, we propose an alternative approach to automatically learn and generate entity (i.e., user and item) categorical information at different levels of granularity, specifically for ID-based recommendation. Specifically, we devise a co-evolving vector quantization framework, namely COVE, which enables the simultaneous learning and refinement of code representation and entity embedding in an end-to-end manner, starting from the randomly initialized states. With its high adaptability, COVE can be easily integrated into existing recommendation models. We validate the effectiveness of COVE on various recommendation tasks including list completion, collaborative filtering, and click-through rate prediction, across different recommendation models. We will publish the code and data for other researchers to reproduce our work.
Adversarially Regularized Graph Attention Networks for Inductive Learning on Partially Labeled Graphs
Jun 07, 2021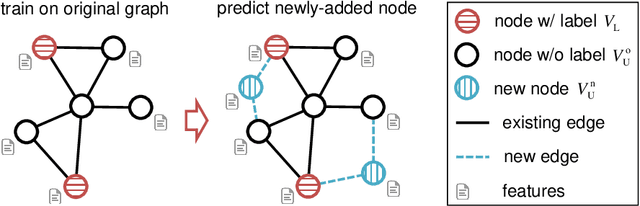

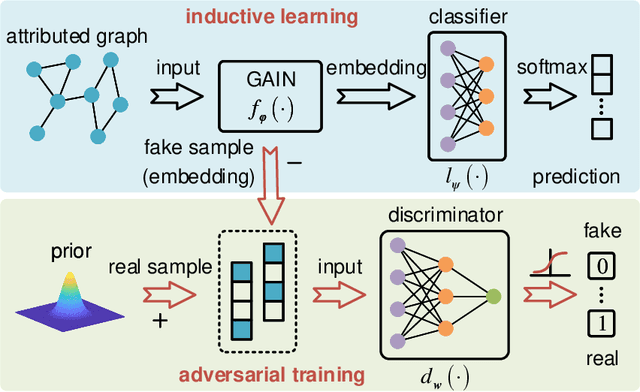
Graph embedding is a general approach to tackling graph-analytic problems by encoding nodes into low-dimensional representations. Most existing embedding methods are transductive since the information of all nodes is required in training, including those to be predicted. In this paper, we propose a novel inductive embedding method for semi-supervised learning on graphs. This method generates node representations by learning a parametric function to aggregate information from the neighborhood using an attention mechanism, and hence naturally generalizes to previously unseen nodes. Furthermore, adversarial training serves as an external regularization enforcing the learned representations to match a prior distribution for improving robustness and generalization ability. Experiments on real-world clean or noisy graphs are used to demonstrate the effectiveness of this approach.