 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassic GNNs are Strong Baselines: Reassessing GNNs for Node Classification
Paper and Code
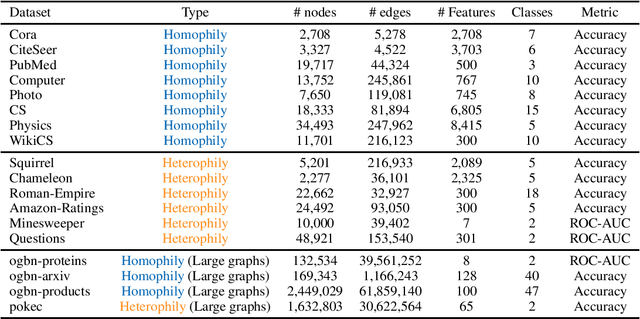
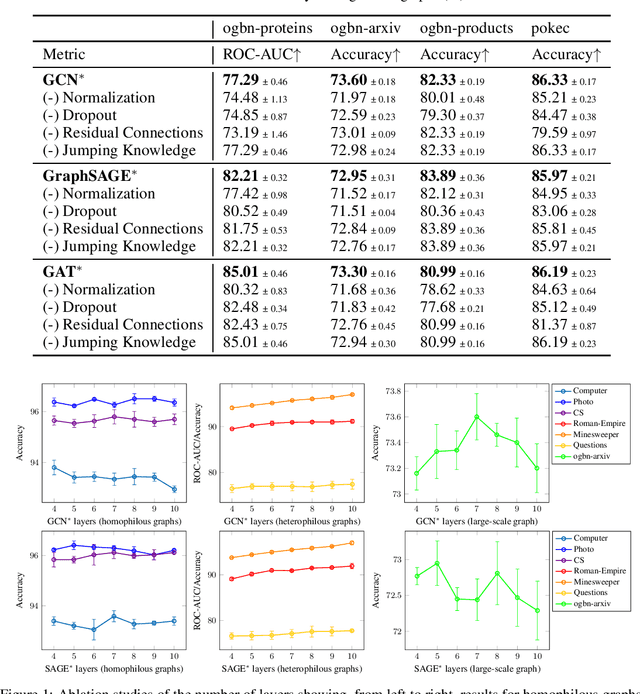
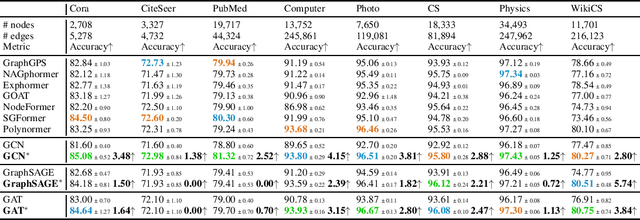
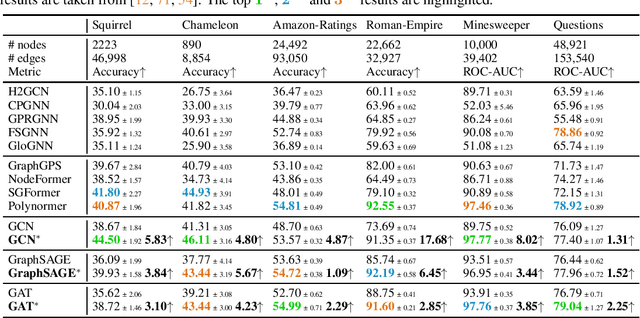
Graph Transformers (GTs) have recently emerged as popular alternatives to traditional message-passing Graph Neural Networks (GNNs), due to their theoretically superior expressiveness and impressive performance reported on standard node classification benchmarks, often significantly outperforming GNNs. In this paper, we conduct a thorough empirical analysis to reevaluate the performance of three classic GNN models (GCN, GAT, and GraphSAGE) against GTs. Our findings suggest that the previously reported superiority of GTs may have been overstated due to suboptimal hyperparameter configurations in GNNs. Remarkably, with slight hyperparameter tuning, these classic GNN models achieve state-of-the-art performance, matching or even exceeding that of recent GTs across 17 out of the 18 diverse datasets examined. Additionally, we conduct detailed ablation studies to investigate the influence of various GNN configurations, such as normalization, dropout, residual connections, network depth, and jumping knowledge mode, on node classification performance. Our study aims to promote a higher standard of empirical rigor in the field of graph machine learning, encouraging more accurate comparisons and evaluations of model capabilities.