 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Supporting Legal Argumentation with NLP: Is More Data Really All You Need?
Jun 16, 2024Modeling legal reasoning and argumentation justifying decisions in cases has always been central to AI & Law, yet contemporary developments in legal NLP have increasingly focused on statistically classifying legal conclusions from text. While conceptually simpler, these approaches often fall short in providing usable justifications connecting to appropriate legal concepts. This paper reviews both traditional symbolic works in AI & Law and recent advances in legal NLP, and distills possibilities of integrating expert-informed knowledge to strike a balance between scalability and explanation in symbolic vs. data-driven approaches. We identify open challenges and discuss the potential of modern NLP models and methods that integrate
Can GPT-4 Support Analysis of Textual Data in Tasks Requiring Highly Specialized Domain Expertise?
Jun 24, 2023



We evaluated the capability of generative pre-trained transformers~(GPT-4) in analysis of textual data in tasks that require highly specialized domain expertise. Specifically, we focused on the task of analyzing court opinions to interpret legal concepts. We found that GPT-4, prompted with annotation guidelines, performs on par with well-trained law student annotators. We observed that, with a relatively minor decrease in performance, GPT-4 can perform batch predictions leading to significant cost reductions. However, employing chain-of-thought prompting did not lead to noticeably improved performance on this task. Further, we demonstrated how to analyze GPT-4's predictions to identify and mitigate deficiencies in annotation guidelines, and subsequently improve the performance of the model. Finally, we observed that the model is quite brittle, as small formatting related changes in the prompt had a high impact on the predictions. These findings can be leveraged by researchers and practitioners who engage in semantic/pragmatic annotations of texts in the context of the tasks requiring highly specialized domain expertise.
Explaining Legal Concepts with Augmented Large Language Models (GPT-4)
Jun 22, 2023


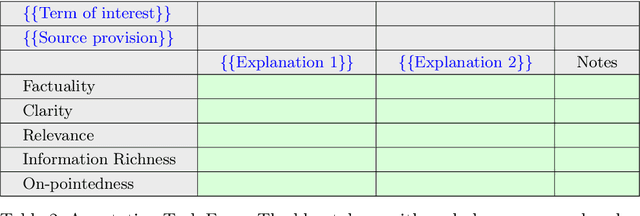
Interpreting the meaning of legal open-textured terms is a key task of legal professionals. An important source for this interpretation is how the term was applied in previous court cases. In this paper, we evaluate the performance of GPT-4 in generating factually accurate, clear and relevant explanations of terms in legislation. We compare the performance of a baseline setup, where GPT-4 is directly asked to explain a legal term, to an augmented approach, where a legal information retrieval module is used to provide relevant context to the model, in the form of sentences from case law. We found that the direct application of GPT-4 yields explanations that appear to be of very high quality on their surface. However, detailed analysis uncovered limitations in terms of the factual accuracy of the explanations. Further, we found that the augmentation leads to improved quality, and appears to eliminate the issue of hallucination, where models invent incorrect statements. These findings open the door to the building of systems that can autonomously retrieve relevant sentences from case law and condense them into a useful explanation for legal scholars, educators or practicing lawyers alike.
Toward an Intelligent Tutoring System for Argument Mining in Legal Texts
Oct 24, 2022



We propose an adaptive environment (CABINET) to support caselaw analysis (identifying key argument elements) based on a novel cognitive computing framework that carefully matches various machine learning (ML) capabilities to the proficiency of a user. CABINET supports law students in their learning as well as professionals in their work. The results of our experiments focused on the feasibility of the proposed framework are promising. We show that the system is capable of identifying a potential error in the analysis with very low false positives rate (2.0-3.5%), as well as of predicting the key argument element type (e.g., an issue or a holding) with a reasonably high F1-score (0.74).
Data-Centric Machine Learning in the Legal Domain
Jan 17, 2022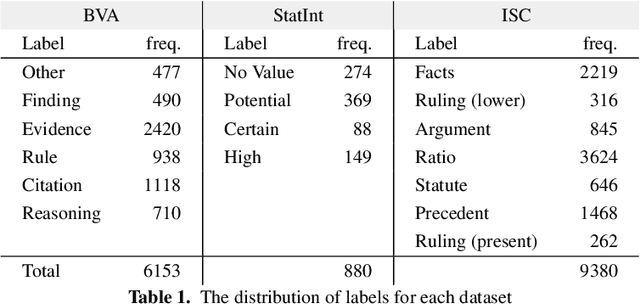
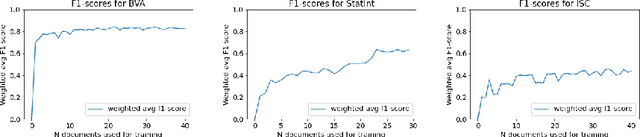
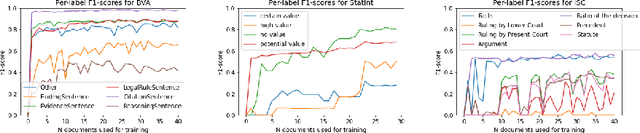

Machine learning research typically starts with a fixed data set created early in the process. The focus of the experiments is finding a model and training procedure that result in the best possible performance in terms of some selected evaluation metric. This paper explores how changes in a data set influence the measured performance of a model. Using three publicly available data sets from the legal domain, we investigate how changes to their size, the train/test splits, and the human labelling accuracy impact the performance of a trained deep learning classifier. We assess the overall performance (weighted average) as well as the per-class performance. The observed effects are surprisingly pronounced, especially when the per-class performance is considered. We investigate how "semantic homogeneity" of a class, i.e., the proximity of sentences in a semantic embedding space, influences the difficulty of its classification. The presented results have far reaching implications for efforts related to data collection and curation in the field of AI & Law. The results also indicate that enhancements to a data set could be considered, alongside the advancement of the ML models, as an additional path for increasing classification performance on various tasks in AI & Law. Finally, we discuss the need for an established methodology to assess the potential effects of data set properties.
Sentence Embeddings and High-speed Similarity Search for Fast Computer Assisted Annotation of Legal Documents
Dec 21, 2021
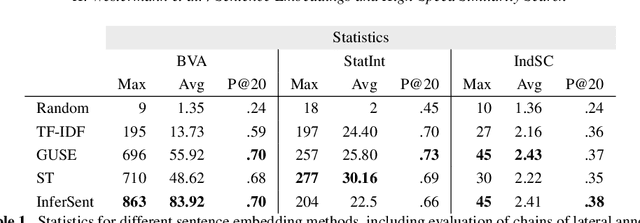
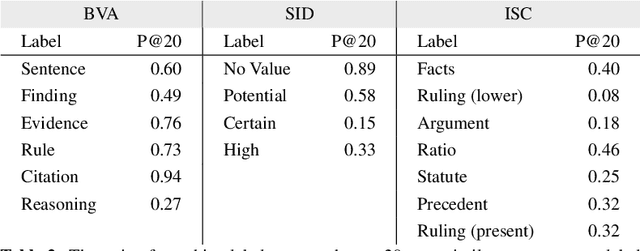
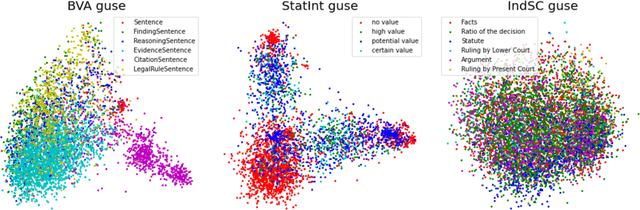
Human-performed annotation of sentences in legal documents is an important prerequisite to many machine learning based systems supporting legal tasks. Typically, the annotation is done sequentially, sentence by sentence, which is often time consuming and, hence, expensive. In this paper, we introduce a proof-of-concept system for annotating sentences "laterally." The approach is based on the observation that sentences that are similar in meaning often have the same label in terms of a particular type system. We use this observation in allowing annotators to quickly view and annotate sentences that are semantically similar to a given sentence, across an entire corpus of documents. Here, we present the interface of the system and empirically evaluate the approach. The experiments show that lateral annotation has the potential to make the annotation process quicker and more consistent.
Lex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains
Dec 15, 2021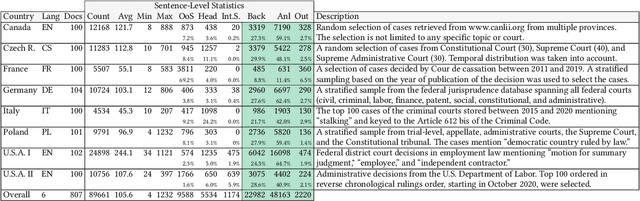
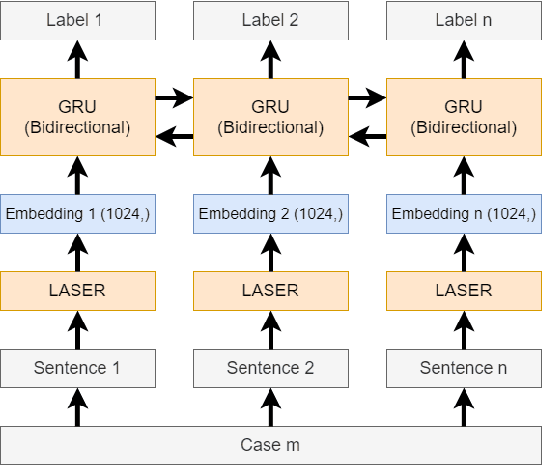
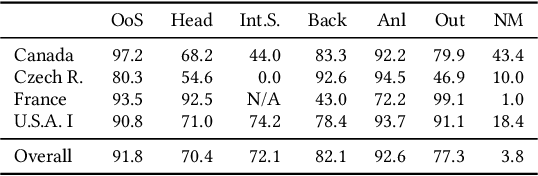
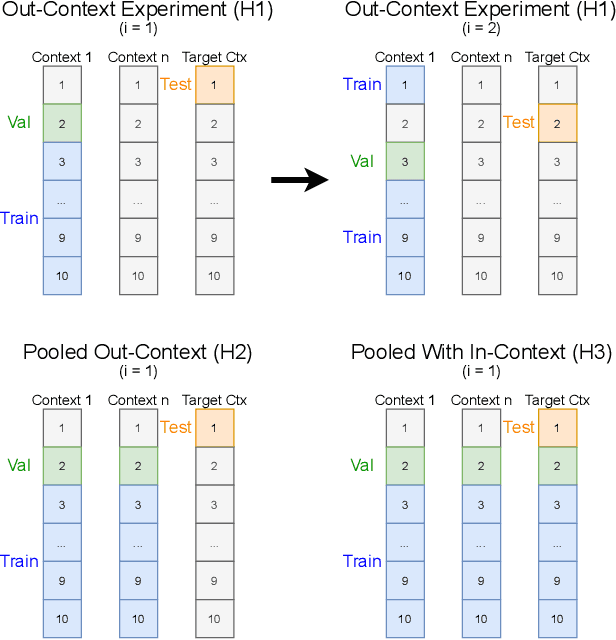
In this paper, we examine the use of multi-lingual sentence embeddings to transfer predictive models for functional segmentation of adjudicatory decisions across jurisdictions, legal systems (common and civil law), languages, and domains (i.e. contexts). Mechanisms for utilizing linguistic resources outside of their original context have significant potential benefits in AI & Law because differences between legal systems, languages, or traditions often block wider adoption of research outcomes. We analyze the use of Language-Agnostic Sentence Representations in sequence labeling models using Gated Recurrent Units (GRUs) that are transferable across languages. To investigate transfer between different contexts we developed an annotation scheme for functional segmentation of adjudicatory decisions. We found that models generalize beyond the contexts on which they were trained (e.g., a model trained on administrative decisions from the US can be applied to criminal law decisions from Italy). Further, we found that training the models on multiple contexts increases robustness and improves overall performance when evaluating on previously unseen contexts. Finally, we found that pooling the training data from all the contexts enhances the models' in-context performance.
* 10 pages
Discovering Explanatory Sentences in Legal Case Decisions Using Pre-trained Language Models
Dec 14, 2021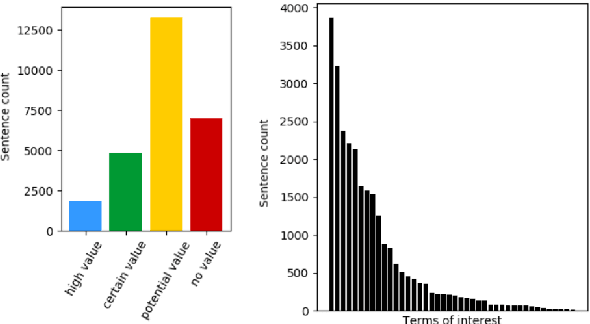
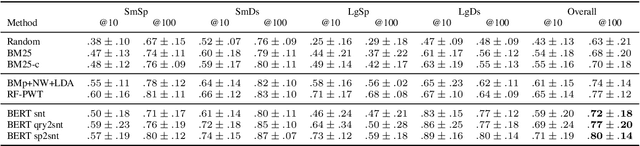

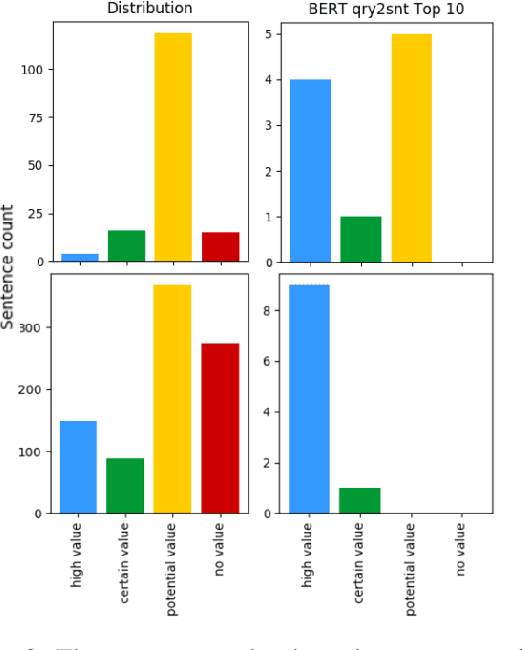
Legal texts routinely use concepts that are difficult to understand. Lawyers elaborate on the meaning of such concepts by, among other things, carefully investigating how have they been used in past. Finding text snippets that mention a particular concept in a useful way is tedious, time-consuming, and, hence, expensive. We assembled a data set of 26,959 sentences, coming from legal case decisions, and labeled them in terms of their usefulness for explaining selected legal concepts. Using the dataset we study the effectiveness of transformer-based models pre-trained on large language corpora to detect which of the sentences are useful. In light of models' predictions, we analyze various linguistic properties of the explanatory sentences as well as their relationship to the legal concept that needs to be explained. We show that the transformer-based models are capable of learning surprisingly sophisticated features and outperform the prior approaches to the task.
* 11 pages
Computer-Assisted Creation of Boolean Search Rules for Text Classification in the Legal Domain
Dec 10, 2021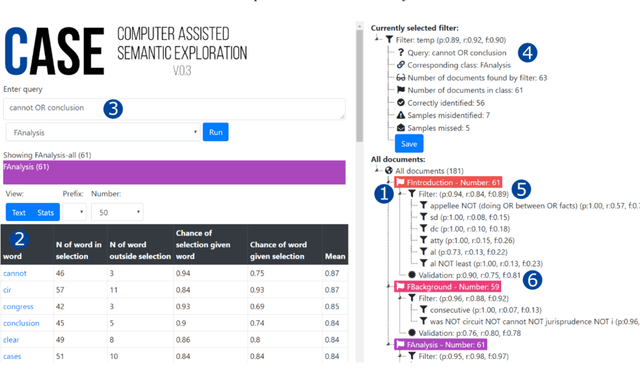
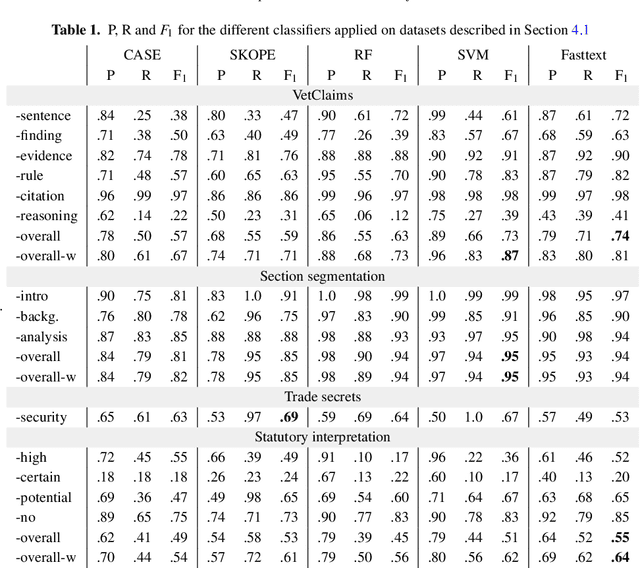

In this paper, we present a method of building strong, explainable classifiers in the form of Boolean search rules. We developed an interactive environment called CASE (Computer Assisted Semantic Exploration) which exploits word co-occurrence to guide human annotators in selection of relevant search terms. The system seamlessly facilitates iterative evaluation and improvement of the classification rules. The process enables the human annotators to leverage the benefits of statistical information while incorporating their expert intuition into the creation of such rules. We evaluate classifiers created with our CASE system on 4 datasets, and compare the results to machine learning methods, including SKOPE rules, Random forest, Support Vector Machine, and fastText classifiers. The results drive the discussion on trade-offs between superior compactness, simplicity, and intuitiveness of the Boolean search rules versus the better performance of state-of-the-art machine learning models for text classification.