 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward an Intelligent Tutoring System for Argument Mining in Legal Texts
Oct 24, 2022



We propose an adaptive environment (CABINET) to support caselaw analysis (identifying key argument elements) based on a novel cognitive computing framework that carefully matches various machine learning (ML) capabilities to the proficiency of a user. CABINET supports law students in their learning as well as professionals in their work. The results of our experiments focused on the feasibility of the proposed framework are promising. We show that the system is capable of identifying a potential error in the analysis with very low false positives rate (2.0-3.5%), as well as of predicting the key argument element type (e.g., an issue or a holding) with a reasonably high F1-score (0.74).
Data-Centric Machine Learning in the Legal Domain
Jan 17, 2022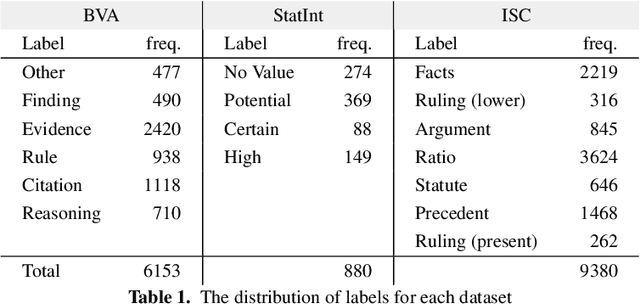
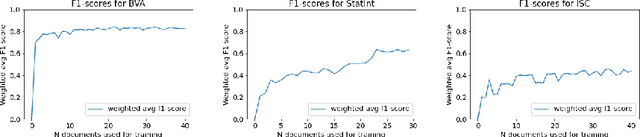
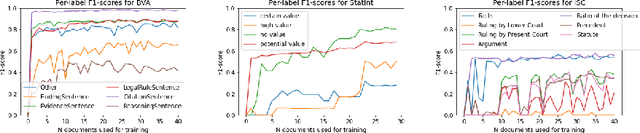

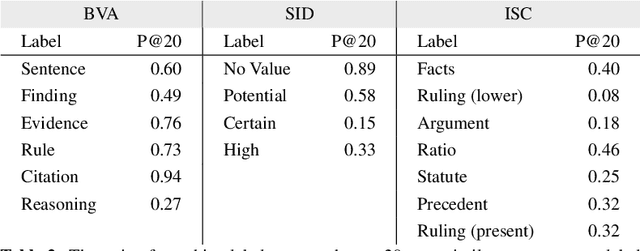
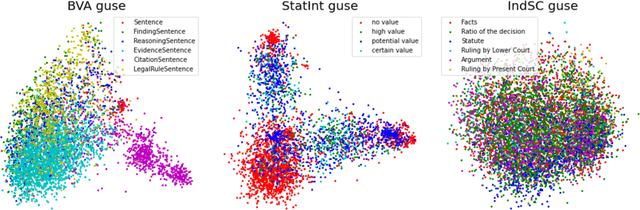
Machine learning research typically starts with a fixed data set created early in the process. The focus of the experiments is finding a model and training procedure that result in the best possible performance in terms of some selected evaluation metric. This paper explores how changes in a data set influence the measured performance of a model. Using three publicly available data sets from the legal domain, we investigate how changes to their size, the train/test splits, and the human labelling accuracy impact the performance of a trained deep learning classifier. We assess the overall performance (weighted average) as well as the per-class performance. The observed effects are surprisingly pronounced, especially when the per-class performance is considered. We investigate how "semantic homogeneity" of a class, i.e., the proximity of sentences in a semantic embedding space, influences the difficulty of its classification. The presented results have far reaching implications for efforts related to data collection and curation in the field of AI & Law. The results also indicate that enhancements to a data set could be considered, alongside the advancement of the ML models, as an additional path for increasing classification performance on various tasks in AI & Law. Finally, we discuss the need for an established methodology to assess the potential effects of data set properties.
Sentence Embeddings and High-speed Similarity Search for Fast Computer Assisted Annotation of Legal Documents
Dec 21, 2021
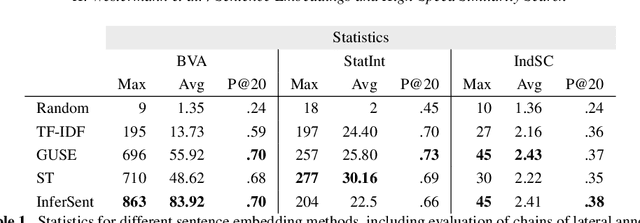
Human-performed annotation of sentences in legal documents is an important prerequisite to many machine learning based systems supporting legal tasks. Typically, the annotation is done sequentially, sentence by sentence, which is often time consuming and, hence, expensive. In this paper, we introduce a proof-of-concept system for annotating sentences "laterally." The approach is based on the observation that sentences that are similar in meaning often have the same label in terms of a particular type system. We use this observation in allowing annotators to quickly view and annotate sentences that are semantically similar to a given sentence, across an entire corpus of documents. Here, we present the interface of the system and empirically evaluate the approach. The experiments show that lateral annotation has the potential to make the annotation process quicker and more consistent.
Computer-Assisted Creation of Boolean Search Rules for Text Classification in the Legal Domain
Dec 10, 2021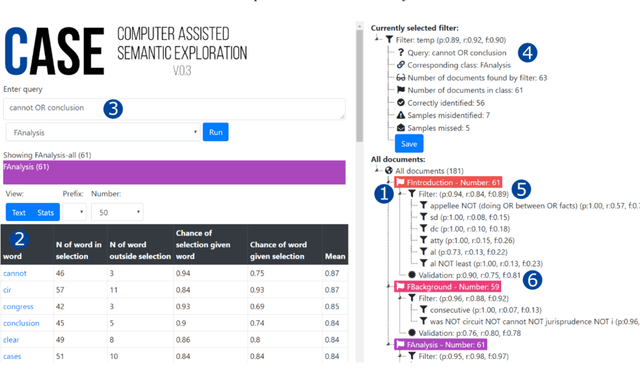
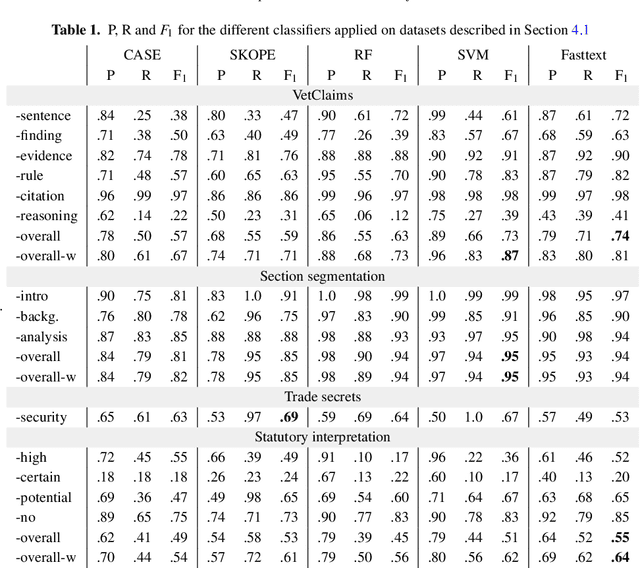

In this paper, we present a method of building strong, explainable classifiers in the form of Boolean search rules. We developed an interactive environment called CASE (Computer Assisted Semantic Exploration) which exploits word co-occurrence to guide human annotators in selection of relevant search terms. The system seamlessly facilitates iterative evaluation and improvement of the classification rules. The process enables the human annotators to leverage the benefits of statistical information while incorporating their expert intuition into the creation of such rules. We evaluate classifiers created with our CASE system on 4 datasets, and compare the results to machine learning methods, including SKOPE rules, Random forest, Support Vector Machine, and fastText classifiers. The results drive the discussion on trade-offs between superior compactness, simplicity, and intuitiveness of the Boolean search rules versus the better performance of state-of-the-art machine learning models for text classification.