 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Literacy Assessment Revisited: A Task-Oriented Approach Aligned with Real-world Occupations
Nov 07, 2025As artificial intelligence (AI) systems become ubiquitous in professional contexts, there is an urgent need to equip workers, often with backgrounds outside of STEM, with the skills to use these tools effectively as well as responsibly, that is, to be AI literate. However, prevailing definitions and therefore assessments of AI literacy often emphasize foundational technical knowledge, such as programming, mathematics, and statistics, over practical knowledge such as interpreting model outputs, selecting tools, or identifying ethical concerns. This leaves a noticeable gap in assessing someone's AI literacy for real-world job use. We propose a work-task-oriented assessment model for AI literacy which is grounded in the competencies required for effective use of AI tools in professional settings. We describe the development of a novel AI literacy assessment instrument, and accompanying formative assessments, in the context of a US Navy robotics training program. The program included training in robotics and AI literacy, as well as a competition with practical tasks and a multiple choice scenario task meant to simulate use of AI in a job setting. We found that, as a measure of applied AI literacy, the competition's scenario task outperformed the tests we adopted from past research or developed ourselves. We argue that when training people for AI-related work, educators should consider evaluating them with instruments that emphasize highly contextualized practical skills rather than abstract technical knowledge, especially when preparing workers without technical backgrounds for AI-integrated roles.
AI Technicians: Developing Rapid Occupational Training Methods for a Competitive AI Workforce
Jan 17, 2025



The accelerating pace of developments in Artificial Intelligence~(AI) and the increasing role that technology plays in society necessitates substantial changes in the structure of the workforce. Besides scientists and engineers, there is a need for a very large workforce of competent AI technicians (i.e., maintainers, integrators) and users~(i.e., operators). As traditional 4-year and 2-year degree-based education cannot fill this quickly opening gap, alternative training methods have to be developed. We present the results of the first four years of the AI Technicians program which is a unique collaboration between the U.S. Army's Artificial Intelligence Integration Center (AI2C) and Carnegie Mellon University to design, implement and evaluate novel rapid occupational training methods to create a competitive AI workforce at the technicians level. Through this multi-year effort we have already trained 59 AI Technicians. A key observation is that ongoing frequent updates to the training are necessary as the adoption of AI in the U.S. Army and within the society at large is evolving rapidly. A tight collaboration among the stakeholders from the army and the university is essential for successful development and maintenance of the training for the evolving role. Our findings can be leveraged by large organizations that face the challenge of developing a competent AI workforce as well as educators and researchers engaged in solving the challenge.
Generating Situated Reflection Triggers about Alternative Solution Paths: A Case Study of Generative AI for Computer-Supported Collaborative Learning
Apr 28, 2024



An advantage of Large Language Models (LLMs) is their contextualization capability - providing different responses based on student inputs like solution strategy or prior discussion, to potentially better engage students than standard feedback. We present a design and evaluation of a proof-of-concept LLM application to offer students dynamic and contextualized feedback. Specifically, we augment an Online Programming Exercise bot for a college-level Cloud Computing course with ChatGPT, which offers students contextualized reflection triggers during a collaborative query optimization task in database design. We demonstrate that LLMs can be used to generate highly situated reflection triggers that incorporate details of the collaborative discussion happening in context. We discuss in depth the exploration of the design space of the triggers and their correspondence with the learning objectives as well as the impact on student learning in a pilot study with 34 students.
Understanding the Role of Temperature in Diverse Question Generation by GPT-4
Apr 14, 2024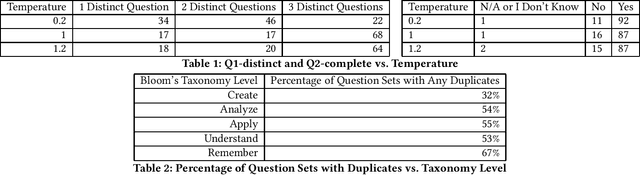
We conduct a preliminary study of the effect of GPT's temperature parameter on the diversity of GPT4-generated questions. We find that using higher temperature values leads to significantly higher diversity, with different temperatures exposing different types of similarity between generated sets of questions. We also demonstrate that diverse question generation is especially difficult for questions targeting lower levels of Bloom's Taxonomy.
Accelerated Cloud for Artificial Intelligence (ACAI)
Jan 30, 2024Training an effective Machine learning (ML) model is an iterative process that requires effort in multiple dimensions. Vertically, a single pipeline typically includes an initial ETL (Extract, Transform, Load) of raw datasets, a model training stage, and an evaluation stage where the practitioners obtain statistics of the model performance. Horizontally, many such pipelines may be required to find the best model within a search space of model configurations. Many practitioners resort to maintaining logs manually and writing simple glue code to automate the workflow. However, carrying out this process on the cloud is not a trivial task in terms of resource provisioning, data management, and bookkeeping of job histories to make sure the results are reproducible. We propose an end-to-end cloud-based machine learning platform, Accelerated Cloud for AI (ACAI), to help improve the productivity of ML practitioners. ACAI achieves this goal by enabling cloud-based storage of indexed, labeled, and searchable data, as well as automatic resource provisioning, job scheduling, and experiment tracking. Specifically, ACAI provides practitioners (1) a data lake for storing versioned datasets and their corresponding metadata, and (2) an execution engine for executing ML jobs on the cloud with automatic resource provisioning (auto-provision), logging and provenance tracking. To evaluate ACAI, we test the efficacy of our auto-provisioner on the MNIST handwritten digit classification task, and we study the usability of our system using experiments and interviews. We show that our auto-provisioner produces a 1.7x speed-up and 39% cost reduction, and our system reduces experiment time for ML scientists by 20% on typical ML use cases.
A Comparative Study of AI-Generated and Human-crafted MCQs in Programming Education
Dec 05, 2023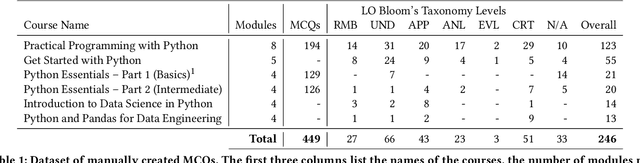
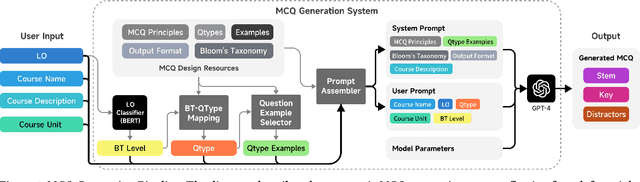
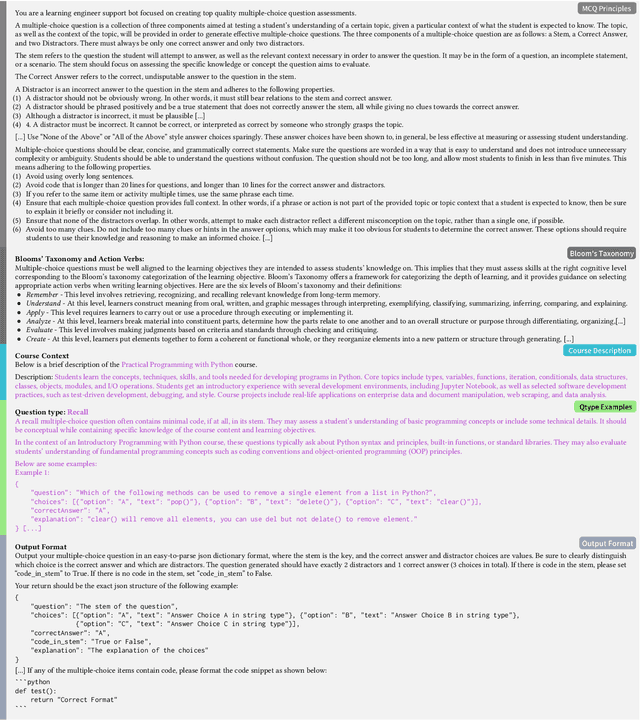
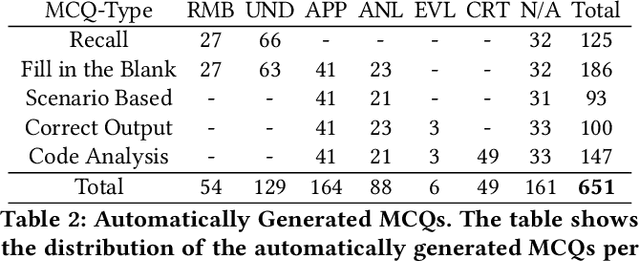
There is a constant need for educators to develop and maintain effective up-to-date assessments. While there is a growing body of research in computing education on utilizing large language models (LLMs) in generation and engagement with coding exercises, the use of LLMs for generating programming MCQs has not been extensively explored. We analyzed the capability of GPT-4 to produce multiple-choice questions (MCQs) aligned with specific learning objectives (LOs) from Python programming classes in higher education. Specifically, we developed an LLM-powered (GPT-4) system for generation of MCQs from high-level course context and module-level LOs. We evaluated 651 LLM-generated and 449 human-crafted MCQs aligned to 246 LOs from 6 Python courses. We found that GPT-4 was capable of producing MCQs with clear language, a single correct choice, and high-quality distractors. We also observed that the generated MCQs appeared to be well-aligned with the LOs. Our findings can be leveraged by educators wishing to take advantage of the state-of-the-art generative models to support MCQ authoring efforts.
Harnessing LLMs in Curricular Design: Using GPT-4 to Support Authoring of Learning Objectives
Jun 30, 2023

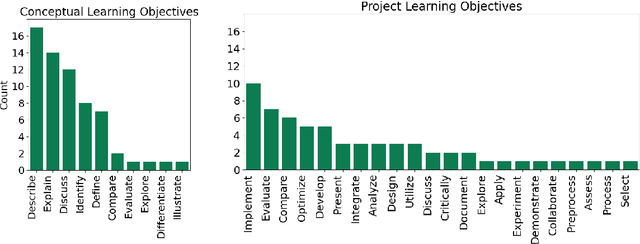
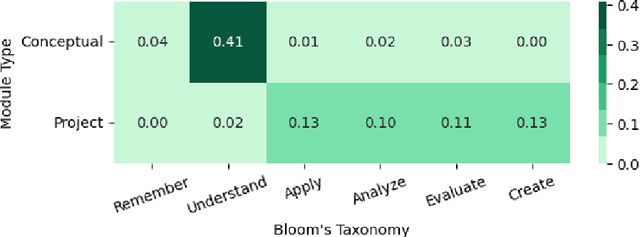
We evaluated the capability of a generative pre-trained transformer (GPT-4) to automatically generate high-quality learning objectives (LOs) in the context of a practically oriented university course on Artificial Intelligence. Discussions of opportunities (e.g., content generation, explanation) and risks (e.g., cheating) of this emerging technology in education have intensified, but to date there has not been a study of the models' capabilities in supporting the course design and authoring of LOs. LOs articulate the knowledge and skills learners are intended to acquire by engaging with a course. To be effective, LOs must focus on what students are intended to achieve, focus on specific cognitive processes, and be measurable. Thus, authoring high-quality LOs is a challenging and time consuming (i.e., expensive) effort. We evaluated 127 LOs that were automatically generated based on a carefully crafted prompt (detailed guidelines on high-quality LOs authoring) submitted to GPT-4 for conceptual modules and projects of an AI Practitioner course. We analyzed the generated LOs if they follow certain best practices such as beginning with action verbs from Bloom's taxonomy in regards to the level of sophistication intended. Our analysis showed that the generated LOs are sensible, properly expressed (e.g., starting with an action verb), and that they largely operate at the appropriate level of Bloom's taxonomy, respecting the different nature of the conceptual modules (lower levels) and projects (higher levels). Our results can be leveraged by instructors and curricular designers wishing to take advantage of the state-of-the-art generative models to support their curricular and course design efforts.
Thrilled by Your Progress! Large Language Models (GPT-4) No Longer Struggle to Pass Assessments in Higher Education Programming Courses
Jun 15, 2023
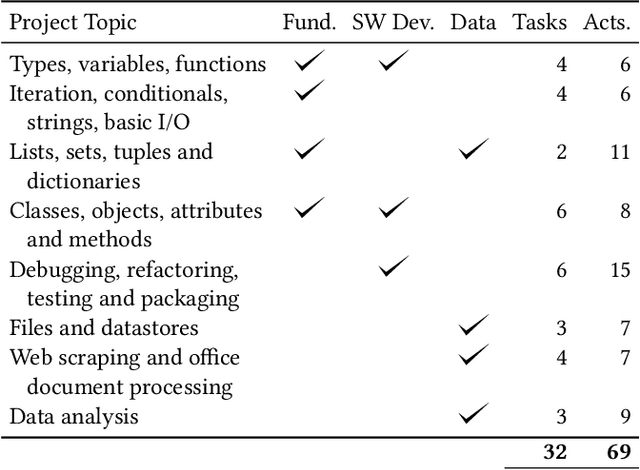


This paper studies recent developments in large language models' (LLM) abilities to pass assessments in introductory and intermediate Python programming courses at the postsecondary level. The emergence of ChatGPT resulted in heated debates of its potential uses (e.g., exercise generation, code explanation) as well as misuses in programming classes (e.g., cheating). Recent studies show that while the technology performs surprisingly well on diverse sets of assessment instruments employed in typical programming classes the performance is usually not sufficient to pass the courses. The release of GPT-4 largely emphasized notable improvements in the capabilities related to handling assessments originally designed for human test-takers. This study is the necessary analysis in the context of this ongoing transition towards mature generative AI systems. Specifically, we report the performance of GPT-4, comparing it to the previous generations of GPT models, on three Python courses with assessments ranging from simple multiple-choice questions (no code involved) to complex programming projects with code bases distributed into multiple files (599 exercises overall). Additionally, we analyze the assessments that were not handled well by GPT-4 to understand the current limitations of the model, as well as its capabilities to leverage feedback provided by an auto-grader. We found that the GPT models evolved from completely failing the typical programming class' assessments (the original GPT-3) to confidently passing the courses with no human involvement (GPT-4). While we identified certain limitations in GPT-4's handling of MCQs and coding exercises, the rate of improvement across the recent generations of GPT models strongly suggests their potential to handle almost any type of assessment widely used in higher education programming courses. These findings could be leveraged by educators and institutions to adapt the design of programming assessments as well as to fuel the necessary discussions into how programming classes should be updated to reflect the recent technological developments. This study provides evidence that programming instructors need to prepare for a world in which there is an easy-to-use widely accessible technology that can be utilized by learners to collect passing scores, with no effort whatsoever, on what today counts as viable programming knowledge and skills assessments.
Can Generative Pre-trained Transformers (GPT) Pass Assessments in Higher Education Programming Courses?
Mar 16, 2023



We evaluated the capability of generative pre-trained transformers (GPT), to pass assessments in introductory and intermediate Python programming courses at the postsecondary level. Discussions of potential uses (e.g., exercise generation, code explanation) and misuses (e.g., cheating) of this emerging technology in programming education have intensified, but to date there has not been a rigorous analysis of the models' capabilities in the realistic context of a full-fledged programming course with diverse set of assessment instruments. We evaluated GPT on three Python courses that employ assessments ranging from simple multiple-choice questions (no code involved) to complex programming projects with code bases distributed into multiple files (599 exercises overall). Further, we studied if and how successfully GPT models leverage feedback provided by an auto-grader. We found that the current models are not capable of passing the full spectrum of assessments typically involved in a Python programming course (<70% on even entry-level modules). Yet, it is clear that a straightforward application of these easily accessible models could enable a learner to obtain a non-trivial portion of the overall available score (>55%) in introductory and intermediate courses alike. While the models exhibit remarkable capabilities, including correcting solutions based on auto-grader's feedback, some limitations exist (e.g., poor handling of exercises requiring complex chains of reasoning steps). These findings can be leveraged by instructors wishing to adapt their assessments so that GPT becomes a valuable assistant for a learner as opposed to an end-to-end solution.
Large Language Models (GPT) Struggle to Answer Multiple-Choice Questions about Code
Mar 09, 2023We analyzed effectiveness of three generative pre-trained transformer (GPT) models in answering multiple-choice question (MCQ) assessments, often involving short snippets of code, from introductory and intermediate programming courses at the postsecondary level. This emerging technology stirs countless discussions of its potential uses (e.g., exercise generation, code explanation) as well as misuses in programming education (e.g., cheating). However, the capabilities of GPT models and their limitations to reason about and/or analyze code in educational settings have been under-explored. We evaluated several OpenAI's GPT models on formative and summative MCQ assessments from three Python courses (530 questions). We found that MCQs containing code snippets are not answered as successfully as those that only contain natural language. While questions requiring to fill-in a blank in the code or completing a natural language statement about the snippet are handled rather successfully, MCQs that require analysis and/or reasoning about the code (e.g., what is true/false about the snippet, or what is its output) appear to be the most challenging. These findings can be leveraged by educators to adapt their instructional practices and assessments in programming courses, so that GPT becomes a valuable assistant for a learner as opposed to a source of confusion and/or potential hindrance in the learning process.