 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots in the Middle: Evaluating LLMs in Dispute Resolution
Oct 09, 2024



Mediation is a dispute resolution method featuring a neutral third-party (mediator) who intervenes to help the individuals resolve their dispute. In this paper, we investigate to which extent large language models (LLMs) are able to act as mediators. We investigate whether LLMs are able to analyze dispute conversations, select suitable intervention types, and generate appropriate intervention messages. Using a novel, manually created dataset of 50 dispute scenarios, we conduct a blind evaluation comparing LLMs with human annotators across several key metrics. Overall, the LLMs showed strong performance, even outperforming our human annotators across dimensions. Specifically, in 62% of the cases, the LLMs chose intervention types that were rated as better than or equivalent to those chosen by humans. Moreover, in 84% of the cases, the intervention messages generated by the LLMs were rated as better than or equal to the intervention messages written by humans. LLMs likewise performed favourably on metrics such as impartiality, understanding and contextualization. Our results demonstrate the potential of integrating AI in online dispute resolution (ODR) platforms.
Citation Data of Czech Apex Courts
Feb 06, 2020
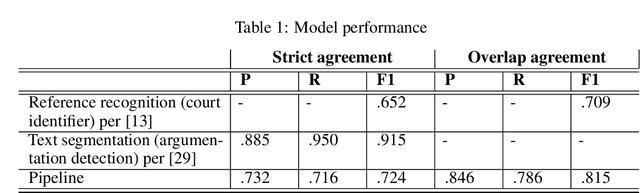


In this paper, we introduce the citation data of the Czech apex courts (Supreme Court, Supreme Administrative Court and Constitutional Court). This dataset was automatically extracted from the corpus of texts of Czech court decisions - CzCDC 1.0. We obtained the citation data by building the natural language processing pipeline for extraction of the court decision identifiers. The pipeline included the (i) document segmentation model and the (ii) reference recognition model. Furthermore, the dataset was manually processed to achieve high-quality citation data as a base for subsequent qualitative and quantitative analyses. The dataset will be made available to the general public.