 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains
Dec 15, 2021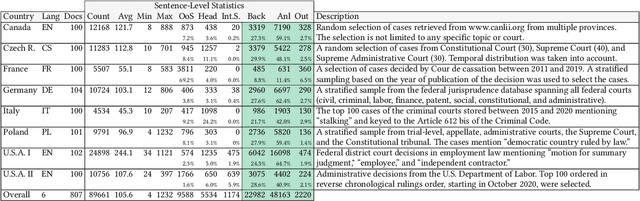
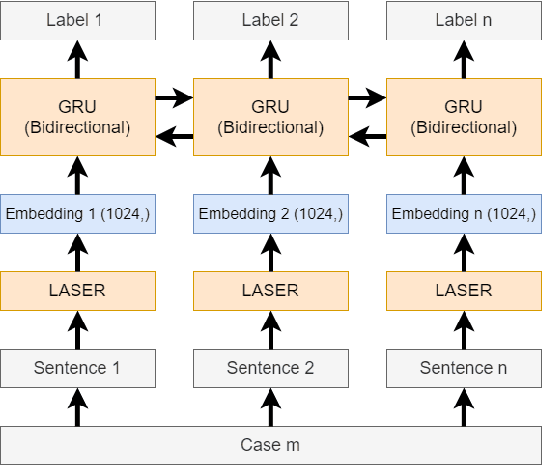
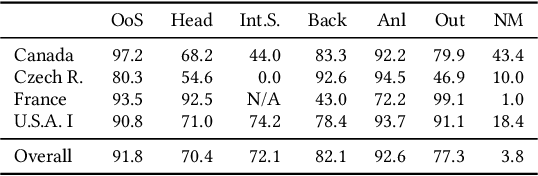
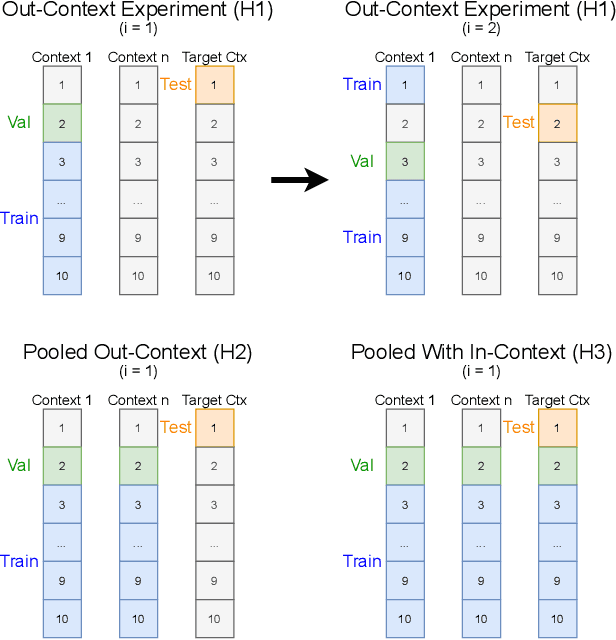
In this paper, we examine the use of multi-lingual sentence embeddings to transfer predictive models for functional segmentation of adjudicatory decisions across jurisdictions, legal systems (common and civil law), languages, and domains (i.e. contexts). Mechanisms for utilizing linguistic resources outside of their original context have significant potential benefits in AI & Law because differences between legal systems, languages, or traditions often block wider adoption of research outcomes. We analyze the use of Language-Agnostic Sentence Representations in sequence labeling models using Gated Recurrent Units (GRUs) that are transferable across languages. To investigate transfer between different contexts we developed an annotation scheme for functional segmentation of adjudicatory decisions. We found that models generalize beyond the contexts on which they were trained (e.g., a model trained on administrative decisions from the US can be applied to criminal law decisions from Italy). Further, we found that training the models on multiple contexts increases robustness and improves overall performance when evaluating on previously unseen contexts. Finally, we found that pooling the training data from all the contexts enhances the models' in-context performance.
* 10 pages
Citation Data of Czech Apex Courts
Feb 06, 2020
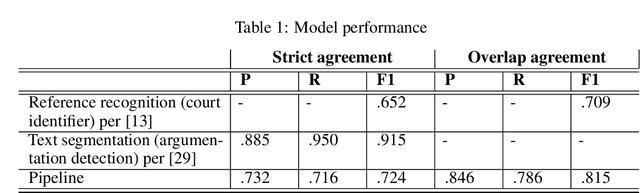


In this paper, we introduce the citation data of the Czech apex courts (Supreme Court, Supreme Administrative Court and Constitutional Court). This dataset was automatically extracted from the corpus of texts of Czech court decisions - CzCDC 1.0. We obtained the citation data by building the natural language processing pipeline for extraction of the court decision identifiers. The pipeline included the (i) document segmentation model and the (ii) reference recognition model. Furthermore, the dataset was manually processed to achieve high-quality citation data as a base for subsequent qualitative and quantitative analyses. The dataset will be made available to the general public.
The Czech Court Decisions Corpus (CzCDC): Availability as the First Step
Oct 21, 2019In this paper, we describe the Czech Court Decision Corpus (CzCDC). CzCDC is a dataset of 237,723 decisions published by the Czech apex (or top-tier) courts, namely the Supreme Court, the Supreme Administrative Court and the Constitutional Court. All the decisions were published between 1st January 1993 and 30th September 2018. Court decisions are available on the webpages of the respective courts or via commercial databases of legal information. This often leads researchers interested in these decisions to reach either to respective court or to commercial provider. This leads to delays and additional costs. These are further exacerbated by a lack of inter-court standard in the terms of the data format in which courts provide their decisions. Additionally, courts' databases often lack proper documentation. Our goal is to make the dataset of court decisions freely available online in consistent (plain) format to lower the cost associated with obtaining data for future research. We believe that simplified access to court decisions through the CzCDC could benefit other researchers. In this paper, we describe the processing of decisions before their inclusion into CzCDC and basic statistics of the dataset. This dataset contains plain texts of court decisions and these texts are not annotated for any grammatical or syntactical features.