 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed Pre-Training on Prior Knowledge
May 23, 2022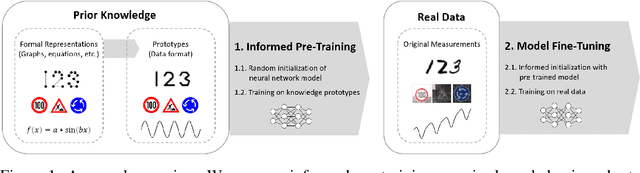



When training data is scarce, the incorporation of additional prior knowledge can assist the learning process. While it is common to initialize neural networks with weights that have been pre-trained on other large data sets, pre-training on more concise forms of knowledge has rather been overlooked. In this paper, we propose a novel informed machine learning approach and suggest to pre-train on prior knowledge. Formal knowledge representations, e.g. graphs or equations, are first transformed into a small and condensed data set of knowledge prototypes. We show that informed pre-training on such knowledge prototypes (i) speeds up the learning processes, (ii) improves generalization capabilities in the regime where not enough training data is available, and (iii) increases model robustness. Analyzing which parts of the model are affected most by the prototypes reveals that improvements come from deeper layers that typically represent high-level features. This confirms that informed pre-training can indeed transfer semantic knowledge. This is a novel effect, which shows that knowledge-based pre-training has additional and complementary strengths to existing approaches.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022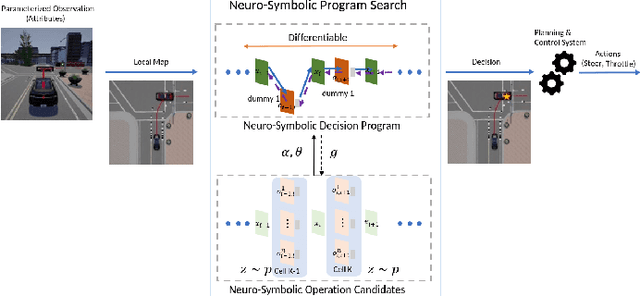
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Explainable Machine Learning with Prior Knowledge: An Overview
May 21, 2021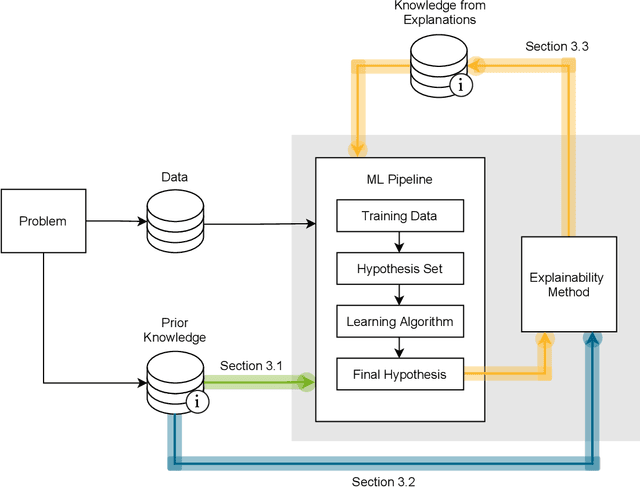

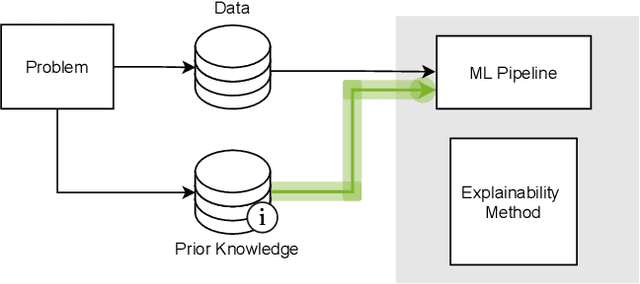
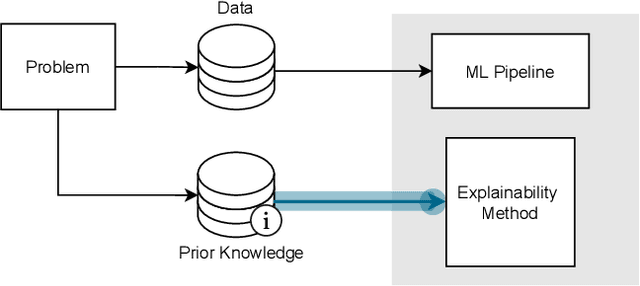
This survey presents an overview of integrating prior knowledge into machine learning systems in order to improve explainability. The complexity of machine learning models has elicited research to make them more explainable. However, most explainability methods cannot provide insight beyond the given data, requiring additional information about the context. We propose to harness prior knowledge to improve upon the explanation capabilities of machine learning models. In this paper, we present a categorization of current research into three main categories which either integrate knowledge into the machine learning pipeline, into the explainability method or derive knowledge from explanations. To classify the papers, we build upon the existing taxonomy of informed machine learning and extend it from the perspective of explainability. We conclude with open challenges and research directions.
Street-Map Based Validation of Semantic Segmentation in Autonomous Driving
Apr 15, 2021
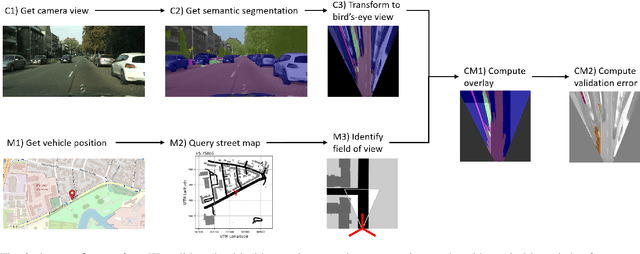
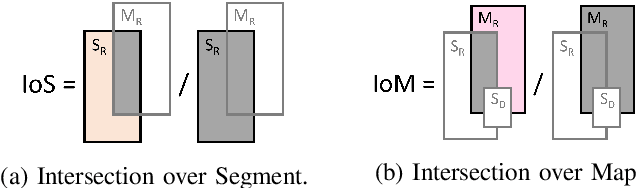

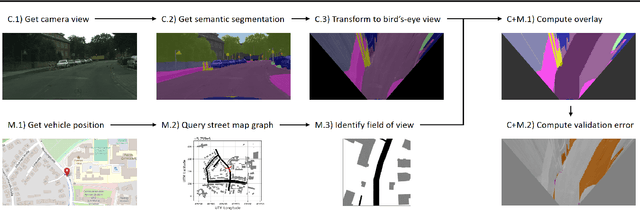
Artificial intelligence for autonomous driving must meet strict requirements on safety and robustness, which motivates the thorough validation of learned models. However, current validation approaches mostly require ground truth data and are thus both cost-intensive and limited in their applicability. We propose to overcome these limitations by a model agnostic validation using a-priori knowledge from street maps. In particular, we show how to validate semantic segmentation masks and demonstrate the potential of our approach using OpenStreetMap. We introduce validation metrics that indicate false positive or negative road segments. Besides the validation approach, we present a method to correct the vehicle's GPS position so that a more accurate localization can be used for the street-map based validation. Lastly, we present quantitative results on the Cityscapes dataset indicating that our validation approach can indeed uncover errors in semantic segmentation masks.
Towards Map-Based Validation of Semantic Segmentation Masks
Nov 03, 2020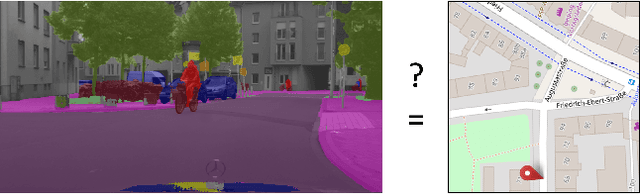
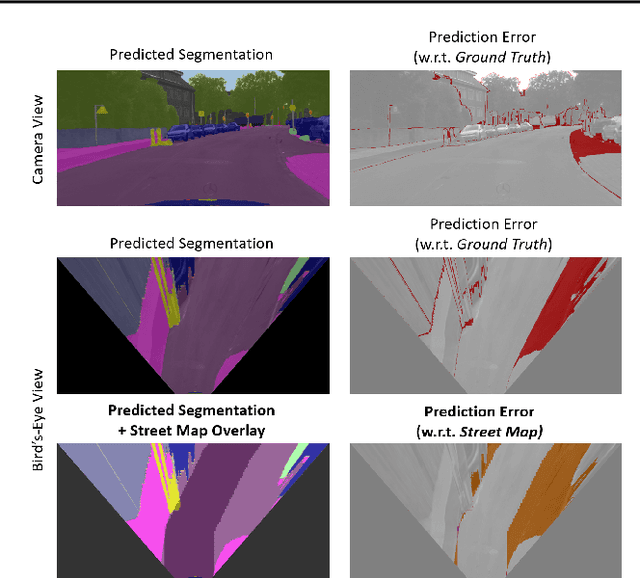
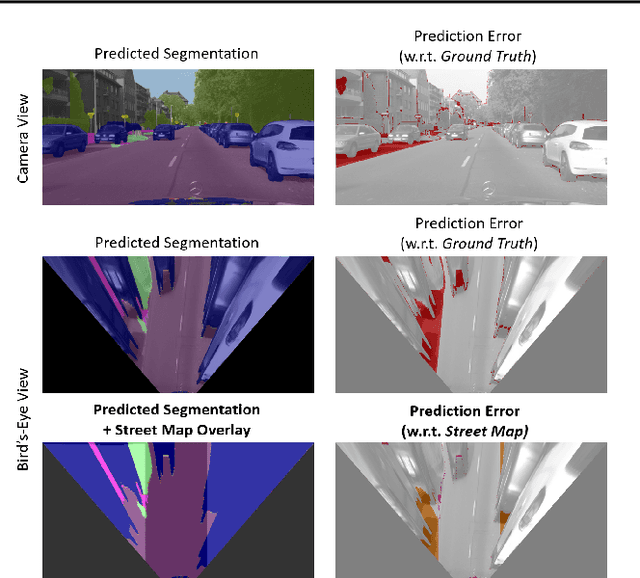
Artificial intelligence for autonomous driving must meet strict requirements on safety and robustness. We propose to validate machine learning models for self-driving vehicles not only with given ground truth labels, but also with additional a-priori knowledge. In particular, we suggest to validate the drivable area in semantic segmentation masks using given street map data. We present first results, which indicate that prediction errors can be uncovered by map-based validation.
Informed Machine Learning - Towards a Taxonomy of Explicit Integration of Knowledge into Machine Learning
Mar 29, 2019
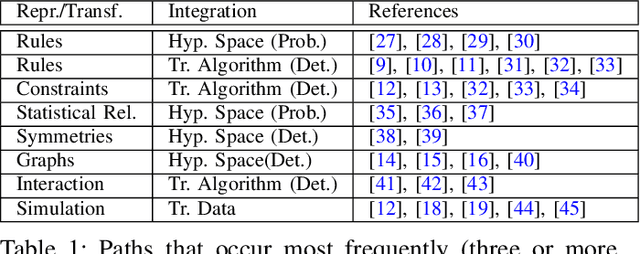


Despite the great successes of machine learning, it can have its limits when dealing with insufficient training data.A potential solution is to incorporate additional knowledge into the training process which leads to the idea of informed machine learning. We present a research survey and structured overview of various approaches in this field. We aim to establish a taxonomy which can serve as a classification framework that considers the kind of additional knowledge, its representation,and its integration into the machine learning pipeline. The evaluation of numerous papers on the bases of the taxonomy uncovers key methods in this field.