 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed Pre-Training on Prior Knowledge
Paper and Code
May 23, 2022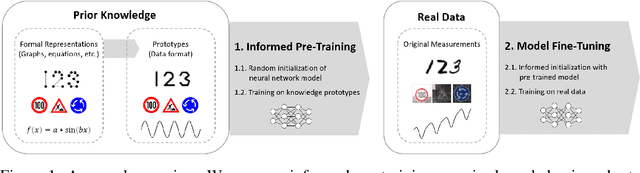



When training data is scarce, the incorporation of additional prior knowledge can assist the learning process. While it is common to initialize neural networks with weights that have been pre-trained on other large data sets, pre-training on more concise forms of knowledge has rather been overlooked. In this paper, we propose a novel informed machine learning approach and suggest to pre-train on prior knowledge. Formal knowledge representations, e.g. graphs or equations, are first transformed into a small and condensed data set of knowledge prototypes. We show that informed pre-training on such knowledge prototypes (i) speeds up the learning processes, (ii) improves generalization capabilities in the regime where not enough training data is available, and (iii) increases model robustness. Analyzing which parts of the model are affected most by the prototypes reveals that improvements come from deeper layers that typically represent high-level features. This confirms that informed pre-training can indeed transfer semantic knowledge. This is a novel effect, which shows that knowledge-based pre-training has additional and complementary strengths to existing approaches.