 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Abstention for Noise-Robust Learning in Medical Image Segmentation
Jan 20, 2026Label noise is a critical problem in medical image segmentation, often arising from the inherent difficulty of manual annotation. Models trained on noisy data are prone to overfitting, which degrades their generalization performance. While a number of methods and strategies have been proposed to mitigate noisy labels in the segmentation domain, this area remains largely under-explored. The abstention mechanism has proven effective in classification tasks by enhancing the capabilities of Cross Entropy, yet its potential in segmentation remains unverified. In this paper, we address this gap by introducing a universal and modular abstention framework capable of enhancing the noise-robustness of a diverse range of loss functions. Our framework improves upon prior work with two key components: an informed regularization term to guide abstention behaviour, and a more flexible power-law-based auto-tuning algorithm for the abstention penalty. We demonstrate the framework's versatility by systematically integrating it with three distinct loss functions to create three novel, noise-robust variants: GAC, SAC, and ADS. Experiments on the CaDIS and DSAD medical datasets show our methods consistently and significantly outperform their non-abstaining baselines, especially under high noise levels. This work establishes that enabling models to selectively ignore corrupted samples is a powerful and generalizable strategy for building more reliable segmentation models. Our code is publicly available at https://github.com/wemous/abstention-for-segmentation.
Benchmark Success, Clinical Failure: When Reinforcement Learning Optimizes for Benchmarks, Not Patients
Dec 28, 2025Recent Reinforcement Learning (RL) advances for Large Language Models (LLMs) have improved reasoning tasks, yet their resource-constrained application to medical imaging remains underexplored. We introduce ChexReason, a vision-language model trained via R1-style methodology (SFT followed by GRPO) using only 2,000 SFT samples, 1,000 RL samples, and a single A100 GPU. Evaluations on CheXpert and NIH benchmarks reveal a fundamental tension: GRPO recovers in-distribution performance (23% improvement on CheXpert, macro-F1 = 0.346) but degrades cross-dataset transferability (19% drop on NIH). This mirrors high-resource models like NV-Reason-CXR-3B, suggesting the issue stems from the RL paradigm rather than scale. We identify a generalization paradox where the SFT checkpoint uniquely improves on NIH before optimization, indicating teacher-guided reasoning captures more institution-agnostic features. Furthermore, cross-model comparisons show structured reasoning scaffolds benefit general-purpose VLMs but offer minimal gain for medically pre-trained models. Consequently, curated supervised fine-tuning may outperform aggressive RL for clinical deployment requiring robustness across diverse populations.
DEAP DIVE: Dataset Investigation with Vision transformers for EEG evaluation
Oct 01, 2025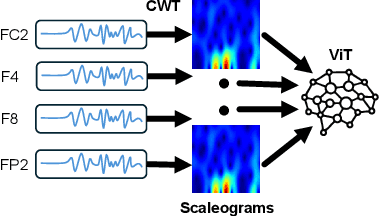
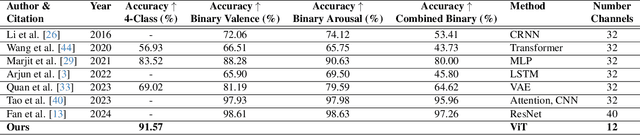


Accurately predicting emotions from brain signals has the potential to achieve goals such as improving mental health, human-computer interaction, and affective computing. Emotion prediction through neural signals offers a promising alternative to traditional methods, such as self-assessment and facial expression analysis, which can be subjective or ambiguous. Measurements of the brain activity via electroencephalogram (EEG) provides a more direct and unbiased data source. However, conducting a full EEG is a complex, resource-intensive process, leading to the rise of low-cost EEG devices with simplified measurement capabilities. This work examines how subsets of EEG channels from the DEAP dataset can be used for sufficiently accurate emotion prediction with low-cost EEG devices, rather than fully equipped EEG-measurements. Using Continuous Wavelet Transformation to convert EEG data into scaleograms, we trained a vision transformer (ViT) model for emotion classification. The model achieved over 91,57% accuracy in predicting 4 quadrants (high/low per arousal and valence) with only 12 measuring points (also referred to as channels). Our work shows clearly, that a significant reduction of input channels yields high results compared to state-of-the-art results of 96,9% with 32 channels. Training scripts to reproduce our code can be found here: https://gitlab.kit.edu/kit/aifb/ATKS/public/AutoSMiLeS/DEAP-DIVE.
Informed Deep Abstaining Classifier: Investigating noise-robust training for diagnostic decision support systems
Oct 28, 2024



Image-based diagnostic decision support systems (DDSS) utilizing deep learning have the potential to optimize clinical workflows. However, developing DDSS requires extensive datasets with expert annotations and is therefore costly. Leveraging report contents from radiological data bases with Natural Language Processing to annotate the corresponding image data promises to replace labor-intensive manual annotation. As mining "real world" databases can introduce label noise, noise-robust training losses are of great interest. However, current noise-robust losses do not consider noise estimations that can for example be derived based on the performance of the automatic label generator used. In this study, we expand the noise-robust Deep Abstaining Classifier (DAC) loss to an Informed Deep Abstaining Classifier (IDAC) loss by incorporating noise level estimations during training. Our findings demonstrate that IDAC enhances the noise robustness compared to DAC and several state-of-the-art loss functions. The results are obtained on various simulated noise levels using a public chest X-ray data set. These findings are reproduced on an in-house noisy data set, where labels were extracted from the clinical systems of the University Hospital Bonn by a text-based transformer. The IDAC can therefore be a valuable tool for researchers, companies or clinics aiming to develop accurate and reliable DDSS from routine clinical data.
CAGE: Circumplex Affect Guided Expression Inference
Apr 23, 2024



Understanding emotions and expressions is a task of interest across multiple disciplines, especially for improving user experiences. Contrary to the common perception, it has been shown that emotions are not discrete entities but instead exist along a continuum. People understand discrete emotions differently due to a variety of factors, including cultural background, individual experiences, and cognitive biases. Therefore, most approaches to expression understanding, particularly those relying on discrete categories, are inherently biased. In this paper, we present a comparative in-depth analysis of two common datasets (AffectNet and EMOTIC) equipped with the components of the circumplex model of affect. Further, we propose a model for the prediction of facial expressions tailored for lightweight applications. Using a small-scaled MaxViT-based model architecture, we evaluate the impact of discrete expression category labels in training with the continuous valence and arousal labels. We show that considering valence and arousal in addition to discrete category labels helps to significantly improve expression inference. The proposed model outperforms the current state-of-the-art models on AffectNet, establishing it as the best-performing model for inferring valence and arousal achieving a 7% lower RMSE. Training scripts and trained weights to reproduce our results can be found here: https://github.com/wagner-niklas/CAGE_expression_inference.
One Stack to Rule them All: To Drive Automated Vehicles, and Reach for the 4th level
Apr 03, 2024



Most automated driving functions are designed for a specific task or vehicle. Most often, the underlying architecture is fixed to specific algorithms to increase performance. Therefore, it is not possible to deploy new modules and algorithms easily. In this paper, we present our automated driving stack which combines both scalability and adaptability. Due to the modular design, our stack allows for a fast integration and testing of novel and state-of-the-art research approaches. Furthermore, it is flexible to be used for our different testing vehicles, including modified EasyMile EZ10 shuttles and different passenger cars. These vehicles differ in multiple ways, e.g. sensor setups, control systems, maximum speed, or steering angle limitations. Finally, our stack is deployed in real world environments, including passenger transport in urban areas. Our stack includes all components needed for operating an autonomous vehicle, including localization, perception, planning, controller, and additional safety modules. Our stack is developed, tested, and evaluated in real world traffic in multiple test sites, including the Test Area Autonomous Driving Baden-W\"urttemberg.
Improving Chest X-Ray Classification by RNN-based Patient Monitoring
Oct 28, 2022Chest X-Ray imaging is one of the most common radiological tools for detection of various pathologies related to the chest area and lung function. In a clinical setting, automated assessment of chest radiographs has the potential of assisting physicians in their decision making process and optimize clinical workflows, for example by prioritizing emergency patients. Most work analyzing the potential of machine learning models to classify chest X-ray images focuses on vision methods processing and predicting pathologies for one image at a time. However, many patients undergo such a procedure multiple times during course of a treatment or during a single hospital stay. The patient history, that is previous images and especially the corresponding diagnosis contain useful information that can aid a classification system in its prediction. In this study, we analyze how information about diagnosis can improve CNN-based image classification models by constructing a novel dataset from the well studied CheXpert dataset of chest X-rays. We show that a model trained on additional patient history information outperforms a model trained without the information by a significant margin. We provide code to replicate the dataset creation and model training.
Gradient Flows for L2 Support Vector Machine Training
Aug 08, 2022
We explore the merits of training of support vector machines for binary classification by means of solving systems of ordinary differential equations. We thus assume a continuous time perspective on a machine learning problem which may be of interest for implementations on (re)emerging hardware platforms such as analog- or quantum computers.