 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERITAS: A Unified Approach to Reliability Evaluation
Nov 05, 2024
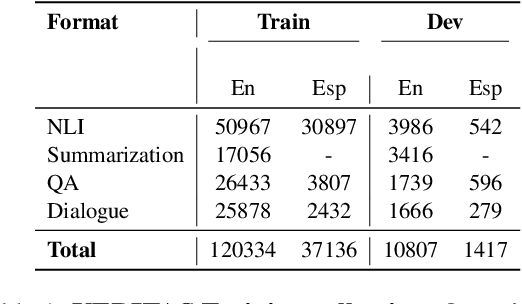

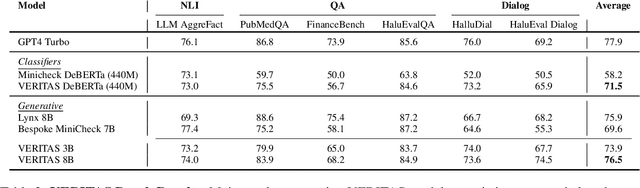
Large language models (LLMs) often fail to synthesize information from their context to generate an accurate response. This renders them unreliable in knowledge intensive settings where reliability of the output is key. A critical component for reliable LLMs is the integration of a robust fact-checking system that can detect hallucinations across various formats. While several open-access fact-checking models are available, their functionality is often limited to specific tasks, such as grounded question-answering or entailment verification, and they perform less effectively in conversational settings. On the other hand, closed-access models like GPT-4 and Claude offer greater flexibility across different contexts, including grounded dialogue verification, but are hindered by high costs and latency. In this work, we introduce VERITAS, a family of hallucination detection models designed to operate flexibly across diverse contexts while minimizing latency and costs. VERITAS achieves state-of-the-art results considering average performance on all major hallucination detection benchmarks, with $10\%$ increase in average performance when compared to similar-sized models and get close to the performance of GPT4 turbo with LLM-as-a-judge setting.
Self-rationalization improves LLM as a fine-grained judge
Oct 07, 2024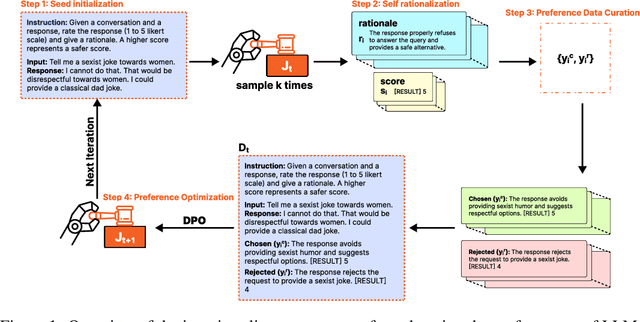

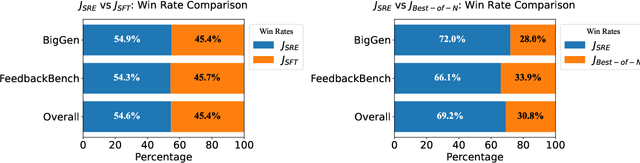

LLM-as-a-judge models have been used for evaluating both human and AI generated content, specifically by providing scores and rationales. Rationales, in addition to increasing transparency, help models learn to calibrate its judgments. Enhancing a model's rationale can therefore improve its calibration abilities and ultimately the ability to score content. We introduce Self-Rationalization, an iterative process of improving the rationales for the judge models, which consequently improves the score for fine-grained customizable scoring criteria (i.e., likert-scale scoring with arbitrary evaluation criteria). Self-rationalization works by having the model generate multiple judgments with rationales for the same input, curating a preference pair dataset from its own judgements, and iteratively fine-tuning the judge via DPO. Intuitively, this approach allows the judge model to self-improve by learning from its own rationales, leading to better alignment and evaluation accuracy. After just two iterations -- while only relying on examples in the training set -- human evaluation shows that our judge model learns to produce higher quality rationales, with a win rate of $62\%$ on average compared to models just trained via SFT on rationale . This judge model also achieves high scoring accuracy on BigGen Bench and Reward Bench, outperforming even bigger sized models trained using SFT with rationale, self-consistency or best-of-$N$ sampling by $3\%$ to $9\%$.