 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERITAS: A Unified Approach to Reliability Evaluation
Paper and Code
Nov 05, 2024
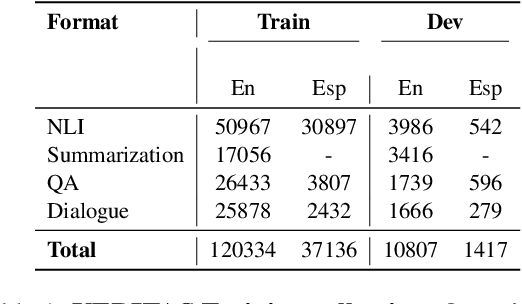

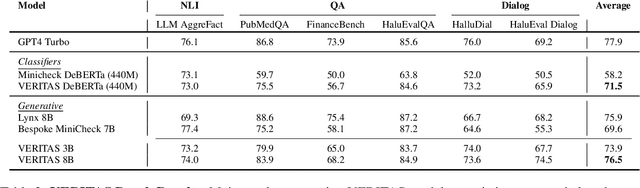
Large language models (LLMs) often fail to synthesize information from their context to generate an accurate response. This renders them unreliable in knowledge intensive settings where reliability of the output is key. A critical component for reliable LLMs is the integration of a robust fact-checking system that can detect hallucinations across various formats. While several open-access fact-checking models are available, their functionality is often limited to specific tasks, such as grounded question-answering or entailment verification, and they perform less effectively in conversational settings. On the other hand, closed-access models like GPT-4 and Claude offer greater flexibility across different contexts, including grounded dialogue verification, but are hindered by high costs and latency. In this work, we introduce VERITAS, a family of hallucination detection models designed to operate flexibly across diverse contexts while minimizing latency and costs. VERITAS achieves state-of-the-art results considering average performance on all major hallucination detection benchmarks, with $10\%$ increase in average performance when compared to similar-sized models and get close to the performance of GPT4 turbo with LLM-as-a-judge setting.