 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphable Detector for Object Detection on Demand
Oct 10, 2021
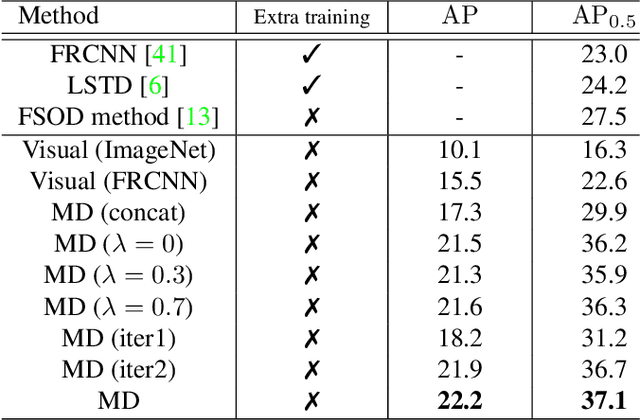
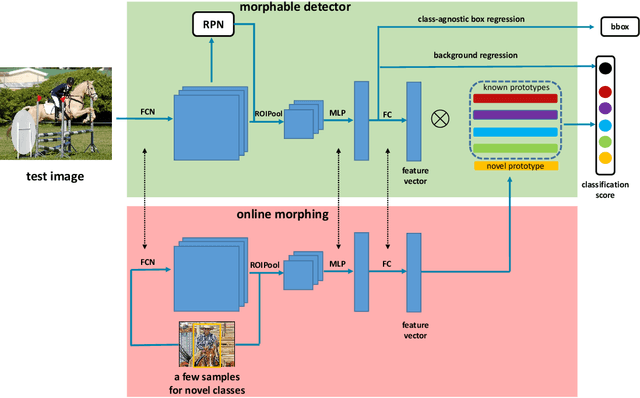
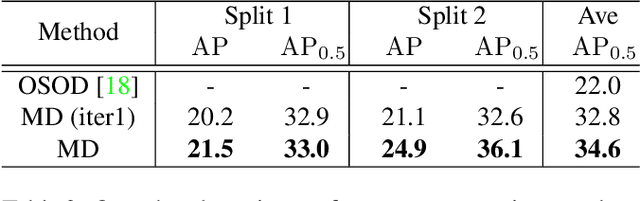
Many emerging applications of intelligent robots need to explore and understand new environments, where it is desirable to detect objects of novel classes on the fly with minimum online efforts. This is an object detection on demand (ODOD) task. It is challenging, because it is impossible to annotate a large number of data on the fly, and the embedded systems are usually unable to perform back-propagation which is essential for training. Most existing few-shot detection methods are confronted here as they need extra training. We propose a novel morphable detector (MD), that simply "morphs" some of its changeable parameters online estimated from the few samples, so as to detect novel classes without any extra training. The MD has two sets of parameters, one for the feature embedding and the other for class representation (called "prototypes"). Each class is associated with a hidden prototype to be learned by integrating the visual and semantic embeddings. The learning of the MD is based on the alternate learning of the feature embedding and the prototypes in an EM-like approach which allows the recovery of an unknown prototype from a few samples of a novel class. Once an MD is learned, it is able to use a few samples of a novel class to directly compute its prototype to fulfill the online morphing process. We have shown the superiority of the MD in Pascal, COCO and FSOD datasets. The code is available https://github.com/Zhaoxiangyun/Morphable-Detector.
Contrastive Learning for Label-Efficient Semantic Segmentation
Dec 23, 2020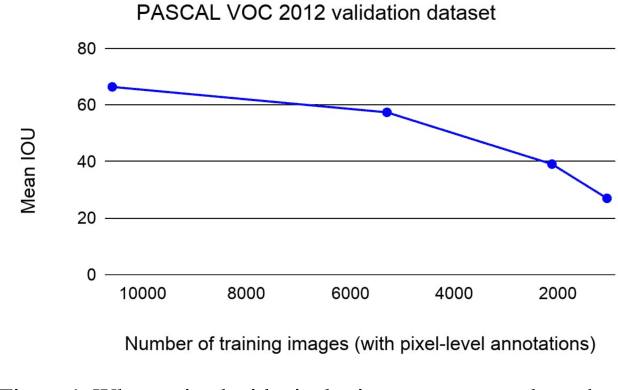

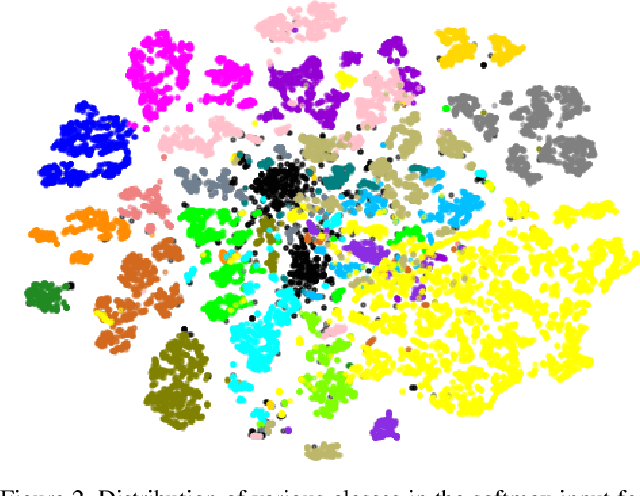

Collecting labeled data for the task of semantic segmentation is expensive and time-consuming, as it requires dense pixel-level annotations. While recent Convolutional Neural Network (CNN) based semantic segmentation approaches have achieved impressive results by using large amounts of labeled training data, their performance drops significantly as the amount of labeled data decreases. This happens because deep CNNs trained with the de facto cross-entropy loss can easily overfit to small amounts of labeled data. To address this issue, we propose a simple and effective contrastive learning-based training strategy in which we first pretrain the network using a pixel-wise class label-based contrastive loss, and then fine-tune it using the cross-entropy loss. This approach increases intra-class compactness and inter-class separability thereby resulting in a better pixel classifier. We demonstrate the effectiveness of the proposed training strategy in both fully-supervised and semi-supervised settings using the Cityscapes and PASCAL VOC 2012 segmentation datasets. Our results show that pretraining with label-based contrastive loss results in large performance gains (more than 20% absolute improvement in some settings) when the amount of labeled data is limited.
Object Detection with a Unified Label Space from Multiple Datasets
Aug 15, 2020


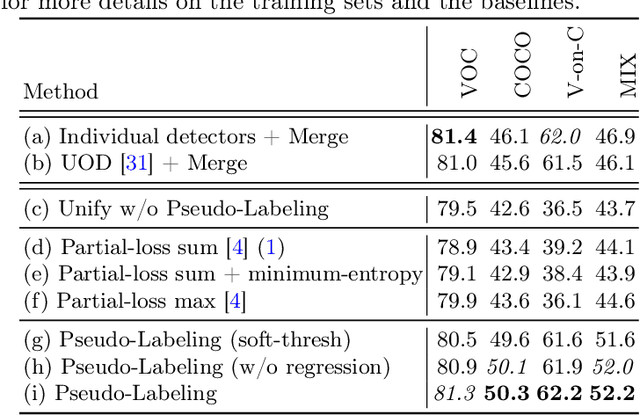
Given multiple datasets with different label spaces, the goal of this work is to train a single object detector predicting over the union of all the label spaces. The practical benefits of such an object detector are obvious and significant application-relevant categories can be picked and merged form arbitrary existing datasets. However, naive merging of datasets is not possible in this case, due to inconsistent object annotations. Consider an object category like faces that is annotated in one dataset, but is not annotated in another dataset, although the object itself appears in the latter images. Some categories, like face here, would thus be considered foreground in one dataset, but background in another. To address this challenge, we design a framework which works with such partial annotations, and we exploit a pseudo labeling approach that we adapt for our specific case. We propose loss functions that carefully integrate partial but correct annotations with complementary but noisy pseudo labels. Evaluation in the proposed novel setting requires full annotation on the test set. We collect the required annotations and define a new challenging experimental setup for this task based one existing public datasets. We show improved performances compared to competitive baselines and appropriate adaptations of existing work.
Recognizing Part Attributes with Insufficient Data
Aug 13, 2019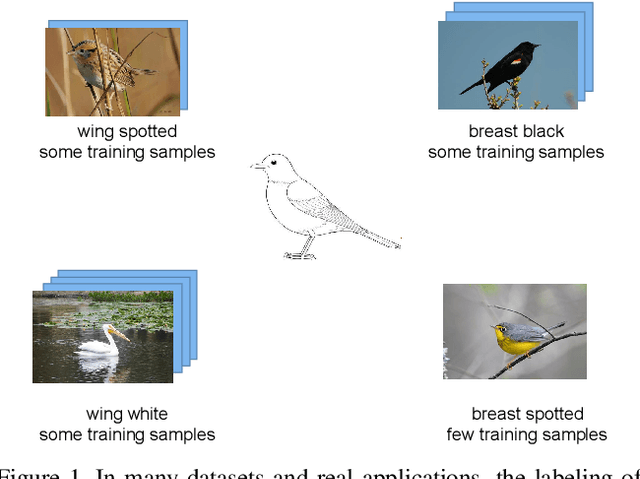

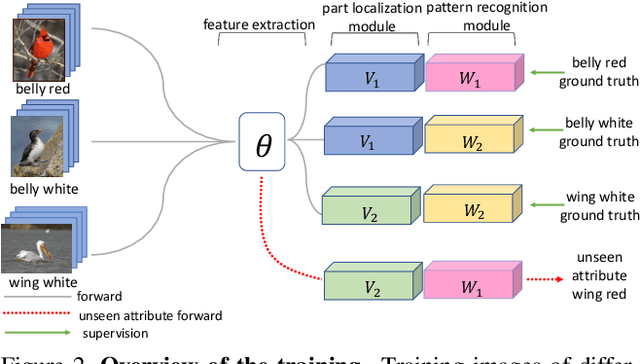

Recognizing attributes of objects and their parts is important to many computer vision applications. Although great progress has been made to apply object-level recognition, recognizing the attributes of parts remains less applicable since the training data for part attributes recognition is usually scarce especially for internet-scale applications. Furthermore, most existing part attribute recognition methods rely on the part annotation which is more expensive to obtain. To solve the data insufficiency problem and get rid of dependence on the part annotation, we introduce a novel Concept Sharing Network (CSN) for part attribute recognition. A great advantage of CSN is its capability of recognizing the part attribute (a combination of part location and appearance pattern) that has insufficient or zero training data, by learning the part location and appearance pattern respectively from the training data that usually mix them in a single label. Extensive experiments on CUB-200-2011 [51], CelebA [35] and a newly proposed human attribute dataset demonstrate the effectiveness of CSN and its advantages over other methods, especially for the attributes with few training samples. Further experiments show that CSN can also perform zero-shot part attribute recognition. The code will be made available at https://github.com/Zhaoxiangyun/Concept-Sharing-Network.
A Modulation Module for Multi-task Learning with Applications in Image Retrieval
Sep 05, 2018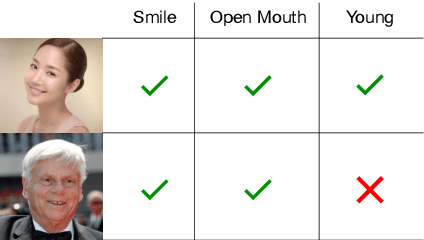
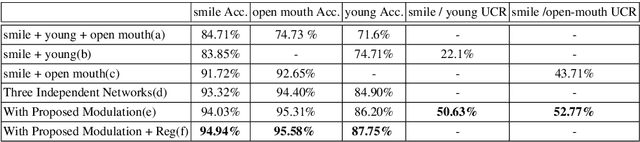

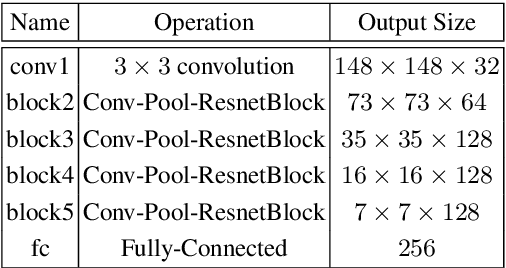
Multi-task learning has been widely adopted in many computer vision tasks to improve overall computation efficiency or boost the performance of individual tasks, under the assumption that those tasks are correlated and complementary to each other. However, the relationships between the tasks are complicated in practice, especially when the number of involved tasks scales up. When two tasks are of weak relevance, they may compete or even distract each other during joint training of shared parameters, and as a consequence undermine the learning of all the tasks. This will raise destructive interference which decreases learning efficiency of shared parameters and lead to low quality loss local optimum w.r.t. shared parameters. To address the this problem, we propose a general modulation module, which can be inserted into any convolutional neural network architecture, to encourage the coupling and feature sharing of relevant tasks while disentangling the learning of irrelevant tasks with minor parameters addition. Equipped with this module, gradient directions from different tasks can be enforced to be consistent for those shared parameters, which benefits multi-task joint training. The module is end-to-end learnable without ad-hoc design for specific tasks, and can naturally handle many tasks at the same time. We apply our approach on two retrieval tasks, face retrieval on the CelebA dataset [1] and product retrieval on the UT-Zappos50K dataset [2, 3], and demonstrate its advantage over other multi-task learning methods in both accuracy and storage efficiency.
Pseudo Mask Augmented Object Detection
Mar 27, 2018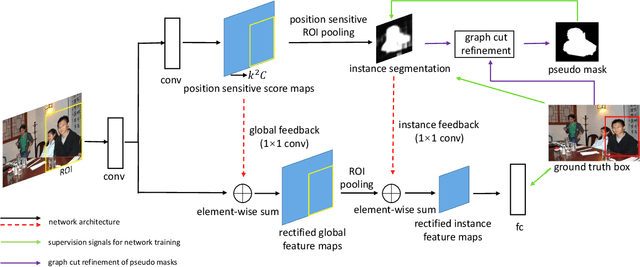


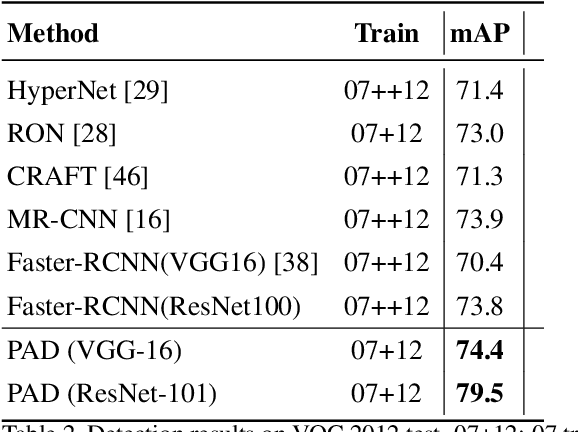
In this work, we present a novel and effective framework to facilitate object detection with the instance-level segmentation information that is only supervised by bounding box annotation. Starting from the joint object detection and instance segmentation network, we propose to recursively estimate the pseudo ground-truth object masks from the instance-level object segmentation network training, and then enhance the detection network with top-down segmentation feedbacks. The pseudo ground truth mask and network parameters are optimized alternatively to mutually benefit each other. To obtain the promising pseudo masks in each iteration, we embed a graphical inference that incorporates the low-level image appearance consistency and the bounding box annotations to refine the segmentation masks predicted by the segmentation network. Our approach progressively improves the object detection performance by incorporating the detailed pixel-wise information learned from the weakly-supervised segmentation network. Extensive evaluation on the detection task in PASCAL VOC 2007 and 2012 [12] verifies that the proposed approach is effective.
Peak-Piloted Deep Network for Facial Expression Recognition
Jan 03, 2017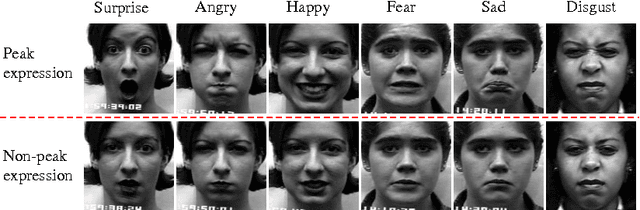
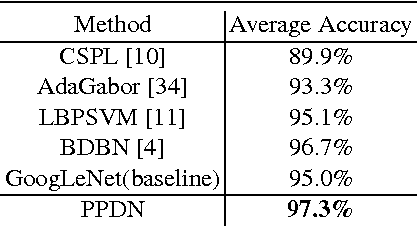


Objective functions for training of deep networks for face-related recognition tasks, such as facial expression recognition (FER), usually consider each sample independently. In this work, we present a novel peak-piloted deep network (PPDN) that uses a sample with peak expression (easy sample) to supervise the intermediate feature responses for a sample of non-peak expression (hard sample) of the same type and from the same subject. The expression evolving process from non-peak expression to peak expression can thus be implicitly embedded in the network to achieve the invariance to expression intensities. A special purpose back-propagation procedure, peak gradient suppression (PGS), is proposed for network training. It drives the intermediate-layer feature responses of non-peak expression samples towards those of the corresponding peak expression samples, while avoiding the inverse. This avoids degrading the recognition capability for samples of peak expression due to interference from their non-peak expression counterparts. Extensive comparisons on two popular FER datasets, Oulu-CASIA and CK+, demonstrate the superiority of the PPDN over state-ofthe-art FER methods, as well as the advantages of both the network structure and the optimization strategy. Moreover, it is shown that PPDN is a general architecture, extensible to other tasks by proper definition of peak and non-peak samples. This is validated by experiments that show state-of-the-art performance on pose-invariant face recognition, using the Multi-PIE dataset.