 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeak-Piloted Deep Network for Facial Expression Recognition
Jan 03, 2017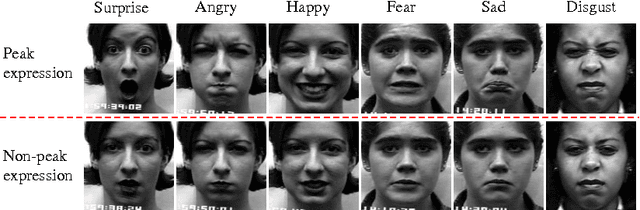
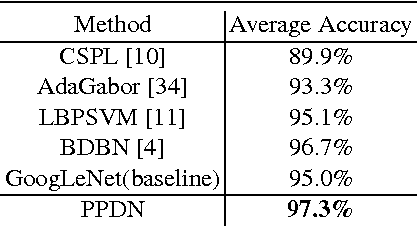


Objective functions for training of deep networks for face-related recognition tasks, such as facial expression recognition (FER), usually consider each sample independently. In this work, we present a novel peak-piloted deep network (PPDN) that uses a sample with peak expression (easy sample) to supervise the intermediate feature responses for a sample of non-peak expression (hard sample) of the same type and from the same subject. The expression evolving process from non-peak expression to peak expression can thus be implicitly embedded in the network to achieve the invariance to expression intensities. A special purpose back-propagation procedure, peak gradient suppression (PGS), is proposed for network training. It drives the intermediate-layer feature responses of non-peak expression samples towards those of the corresponding peak expression samples, while avoiding the inverse. This avoids degrading the recognition capability for samples of peak expression due to interference from their non-peak expression counterparts. Extensive comparisons on two popular FER datasets, Oulu-CASIA and CK+, demonstrate the superiority of the PPDN over state-ofthe-art FER methods, as well as the advantages of both the network structure and the optimization strategy. Moreover, it is shown that PPDN is a general architecture, extensible to other tasks by proper definition of peak and non-peak samples. This is validated by experiments that show state-of-the-art performance on pose-invariant face recognition, using the Multi-PIE dataset.