 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Training Data in Generative Music Models via Black-Box Membership Inference
May 28, 2026Recent advances in text-to-music generation enable high-fidelity synthesis of structured musical audio, raising growing concerns about data provenance, consent, and training transparency. These models are typically trained on large-scale corpora with little disclosure, leaving no practical mechanism to verify whether a particular audio sample was included in training. In this paper, we investigate black-box membership inference for generative music models, aiming to determine whether a candidate music sample was used during training, given only query access to the deployed system. Our key insight is that training membership induces systematically stronger semantic and structural alignment between a candidate sample and the model's generation conditioned on its caption. We query the target model with the associated caption and measure the relationship between the candidate audio and the generated output in a learned feature space. To capture features that separate members from non-members, we construct paired examples consisting of each track and its caption-conditioned generation from shadow models, and train a music auditor to classify membership. The auditor captures alignment patterns characteristic of training membership and generalizes to unseen target models in a fully black-box setting without access to model parameters or training metadata. Across multiple state-of-the-art music generators, our method achieves up to 98.6% accuracy, with false-positive and false-negative rates as low as 1.9% and 1.0%, demonstrating that reliable training-data auditing is feasible in realistic deployment scenarios.
FedSpy-LLM: Towards Scalable and Generalizable Data Reconstruction Attacks from Gradients on LLMs
Apr 07, 2026Given the growing reliance on private data in training Large Language Models (LLMs), Federated Learning (FL) combined with Parameter-Efficient Fine-Tuning (PEFT) has garnered significant attention for enhancing privacy and efficiency. Despite FL's privacy benefits, prior studies have shown that private data can still be extracted from shared gradients. However, these studies, mainly on full-parameter model training, are limited to reconstructing small batches, short input sequences, and specific model architectures, such as encoder-based or decoder-based models. The reconstruction quality becomes even worse when dealing with gradients from PEFT methods. To fully understand the practical attack surface of federated LLMs, this paper proposes FedSpy-LLM, a scalable and generalizable data reconstruction attack designed to reconstruct training data with larger batch sizes and longer sequences while generalizing across diverse model architectures, even when PEFT methods are deployed for training. At the core of FedSpy-LLM is a novel gradient decomposition strategy that exploits the rank deficiency and subspace structure of gradients, enabling efficient token extraction while preserving key signal components at scale. This approach further mitigates the reconstruction challenges introduced by PEFT's substantial null space, ensuring robustness across encoder-based, decoder-based, and encoder-decoder model architectures. Additionally, by iteratively aligning each token's partial-sequence gradient with the full-sequence gradient, FedSpy-LLM ensures accurate token ordering in reconstructed sequences.
EAB-FL: Exacerbating Algorithmic Bias through Model Poisoning Attacks in Federated Learning
Oct 02, 2024



Federated Learning (FL) is a technique that allows multiple parties to train a shared model collaboratively without disclosing their private data. It has become increasingly popular due to its distinct privacy advantages. However, FL models can suffer from biases against certain demographic groups (e.g., racial and gender groups) due to the heterogeneity of data and party selection. Researchers have proposed various strategies for characterizing the group fairness of FL algorithms to address this issue. However, the effectiveness of these strategies in the face of deliberate adversarial attacks has not been fully explored. Although existing studies have revealed various threats (e.g., model poisoning attacks) against FL systems caused by malicious participants, their primary aim is to decrease model accuracy, while the potential of leveraging poisonous model updates to exacerbate model unfairness remains unexplored. In this paper, we propose a new type of model poisoning attack, EAB-FL, with a focus on exacerbating group unfairness while maintaining a good level of model utility. Extensive experiments on three datasets demonstrate the effectiveness and efficiency of our attack, even with state-of-the-art fairness optimization algorithms and secure aggregation rules employed.
GLOCALFAIR: Jointly Improving Global and Local Group Fairness in Federated Learning
Jan 07, 2024



Federated learning (FL) has emerged as a prospective solution for collaboratively learning a shared model across clients without sacrificing their data privacy. However, the federated learned model tends to be biased against certain demographic groups (e.g., racial and gender groups) due to the inherent FL properties, such as data heterogeneity and party selection. Unlike centralized learning, mitigating bias in FL is particularly challenging as private training datasets and their sensitive attributes are typically not directly accessible. Most prior research in this field only focuses on global fairness while overlooking the local fairness of individual clients. Moreover, existing methods often require sensitive information about the client's local datasets to be shared, which is not desirable. To address these issues, we propose GLOCALFAIR, a client-server co-design fairness framework that can jointly improve global and local group fairness in FL without the need for sensitive statistics about the client's private datasets. Specifically, we utilize constrained optimization to enforce local fairness on the client side and adopt a fairness-aware clustering-based aggregation on the server to further ensure the global model fairness across different sensitive groups while maintaining high utility. Experiments on two image datasets and one tabular dataset with various state-of-the-art fairness baselines show that GLOCALFAIR can achieve enhanced fairness under both global and local data distributions while maintaining a good level of utility and client fairness.
RecUP-FL: Reconciling Utility and Privacy in Federated Learning via User-configurable Privacy Defense
Apr 11, 2023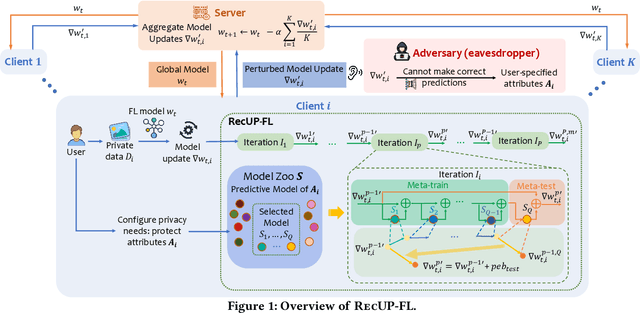



Federated learning (FL) provides a variety of privacy advantages by allowing clients to collaboratively train a model without sharing their private data. However, recent studies have shown that private information can still be leaked through shared gradients. To further minimize the risk of privacy leakage, existing defenses usually require clients to locally modify their gradients (e.g., differential privacy) prior to sharing with the server. While these approaches are effective in certain cases, they regard the entire data as a single entity to protect, which usually comes at a large cost in model utility. In this paper, we seek to reconcile utility and privacy in FL by proposing a user-configurable privacy defense, RecUP-FL, that can better focus on the user-specified sensitive attributes while obtaining significant improvements in utility over traditional defenses. Moreover, we observe that existing inference attacks often rely on a machine learning model to extract the private information (e.g., attributes). We thus formulate such a privacy defense as an adversarial learning problem, where RecUP-FL generates slight perturbations that can be added to the gradients before sharing to fool adversary models. To improve the transferability to un-queryable black-box adversary models, inspired by the idea of meta-learning, RecUP-FL forms a model zoo containing a set of substitute models and iteratively alternates between simulations of the white-box and the black-box adversarial attack scenarios to generate perturbations. Extensive experiments on four datasets under various adversarial settings (both attribute inference attack and data reconstruction attack) show that RecUP-FL can meet user-specified privacy constraints over the sensitive attributes while significantly improving the model utility compared with state-of-the-art privacy defenses.