Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering on the Edge: Learning Structure in Graphs
Paper and Code
May 05, 2016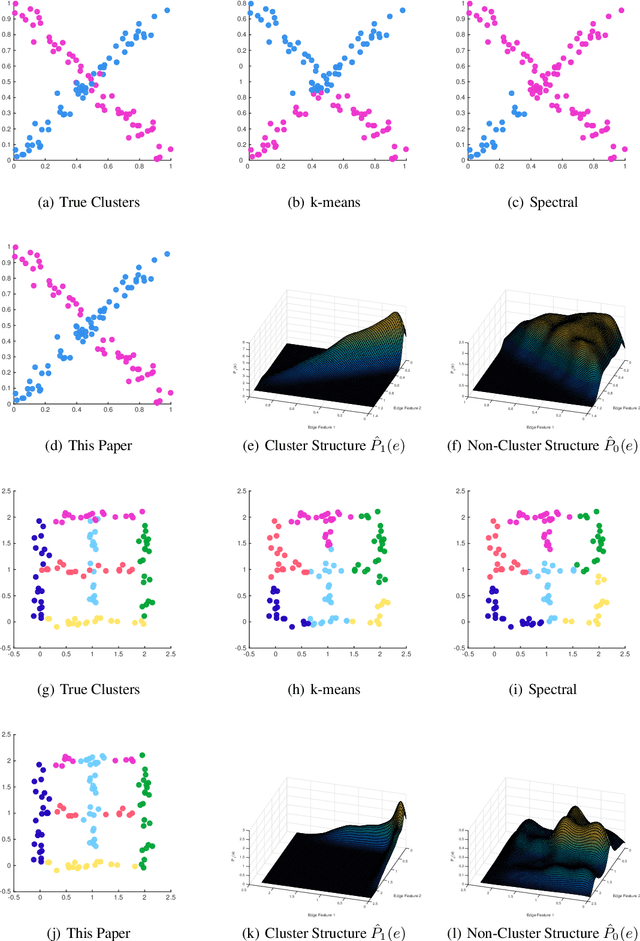
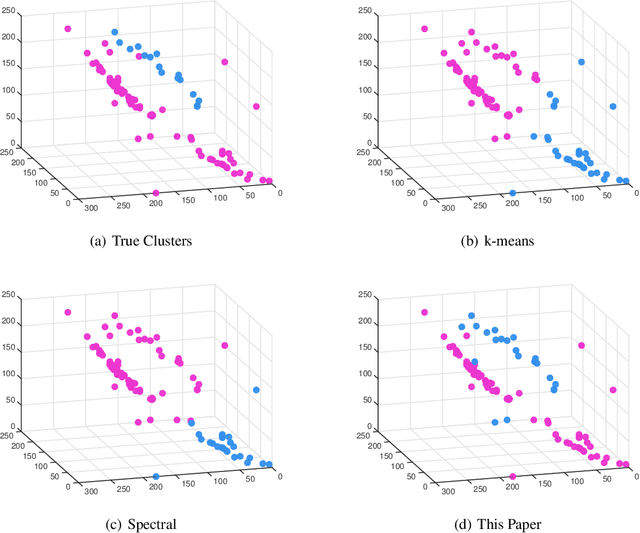
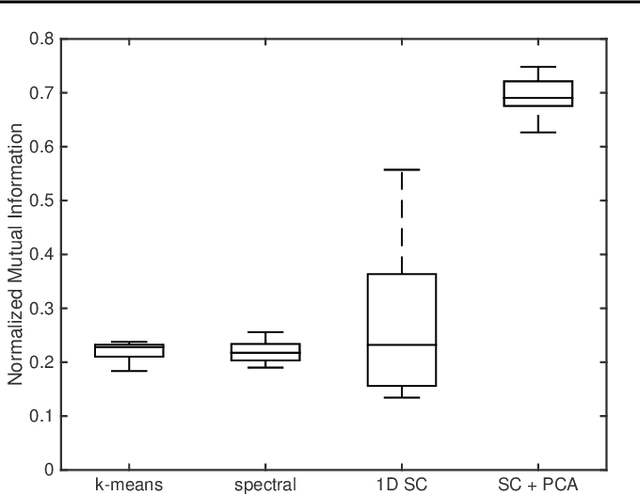
With the recent popularity of graphical clustering methods, there has been an increased focus on the information between samples. We show how learning cluster structure using edge features naturally and simultaneously determines the most likely number of clusters and addresses data scale issues. These results are particularly useful in instances where (a) there are a large number of clusters and (b) we have some labeled edges. Applications in this domain include image segmentation, community discovery and entity resolution. Our model is an extension of the planted partition model and our solution uses results of correlation clustering, which achieves a partition O(log(n))-close to the log-likelihood of the true clustering.
View paper on