 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Sampling for Anytime Motion Planning on Graphs with Expensive-to-Evaluate Edges
Mar 20, 2020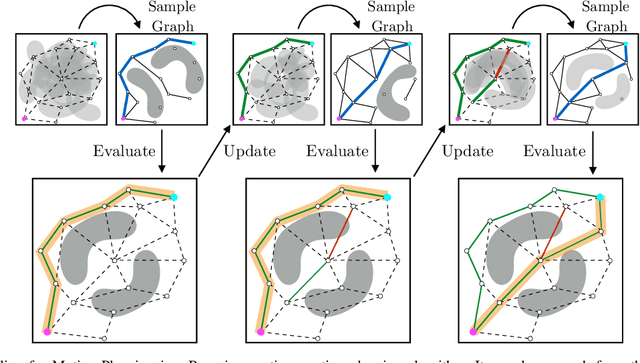

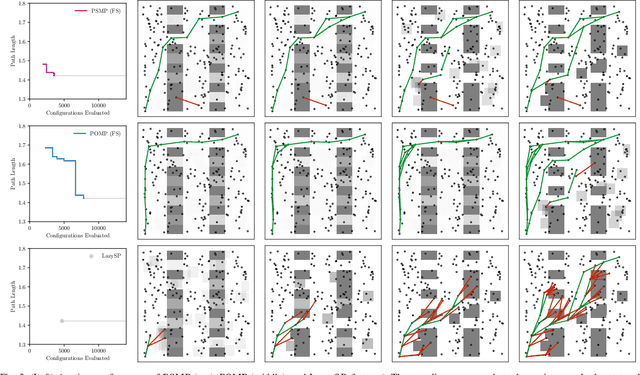
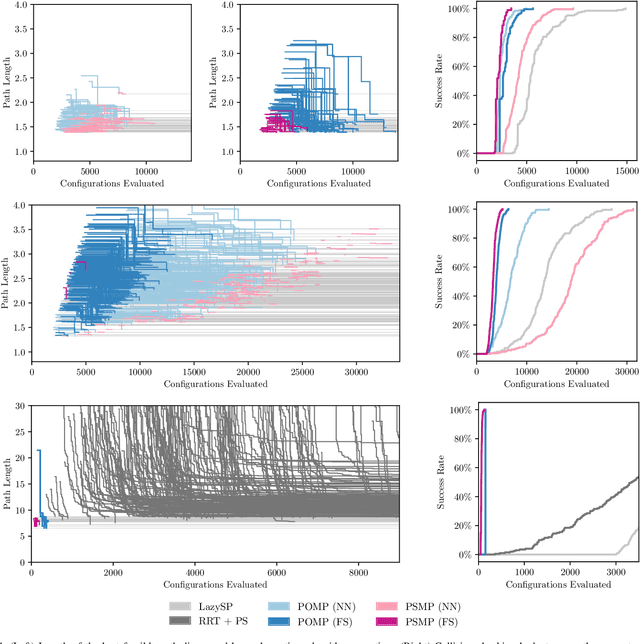
Collision checking is a computational bottleneck in motion planning, requiring lazy algorithms that explicitly reason about when to perform this computation. Optimism in the face of collision uncertainty minimizes the number of checks before finding the shortest path. However, this may take a prohibitively long time to compute, with no other feasible paths discovered during this period. For many real-time applications, we instead demand strong anytime performance, defined as minimizing the cumulative lengths of the feasible paths yielded over time. We introduce Posterior Sampling for Motion Planning (PSMP), an anytime lazy motion planning algorithm that leverages learned posteriors on edge collisions to quickly discover an initial feasible path and progressively yield shorter paths. PSMP obtains an expected regret bound of $\tilde{O}(\sqrt{\mathcal{S} \mathcal{A} T})$ and outperforms comparative baselines on a set of 2D and 7D planning problems.
Bayesian Residual Policy Optimization: Scalable Bayesian Reinforcement Learning with Clairvoyant Experts
Feb 07, 2020
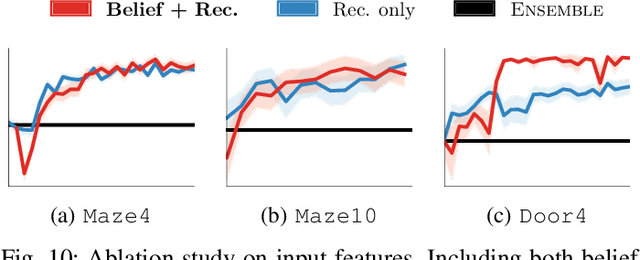
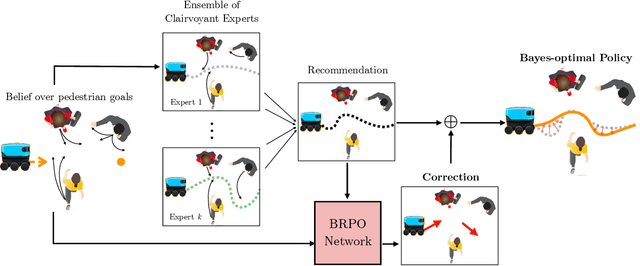
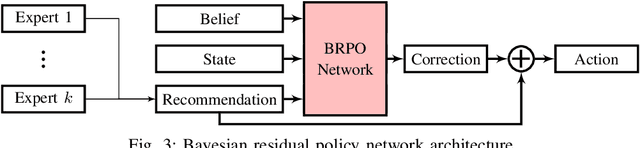
Informed and robust decision making in the face of uncertainty is critical for robots that perform physical tasks alongside people. We formulate this as Bayesian Reinforcement Learning over latent Markov Decision Processes (MDPs). While Bayes-optimality is theoretically the gold standard, existing algorithms do not scale well to continuous state and action spaces. Our proposal builds on the following insight: in the absence of uncertainty, each latent MDP is easier to solve. We first obtain an ensemble of experts, one for each latent MDP, and fuse their advice to compute a baseline policy. Next, we train a Bayesian residual policy to improve upon the ensemble's recommendation and learn to reduce uncertainty. Our algorithm, Bayesian Residual Policy Optimization (BRPO), imports the scalability of policy gradient methods and task-specific expert skills. BRPO significantly improves the ensemble of experts and drastically outperforms existing adaptive RL methods.
Towards Effective Human-AI Teams: The Case of Collaborative Packing
Sep 20, 2019

We focus on the problem of designing an artificial agent, capable of assisting a human user to complete a task. Our goal is to guide human users towards optimal task performance while keeping their cognitive load as low as possible. Our insight is that in order to do so, we should develop an understanding of human decision making for the task domain. In this work, we consider the domain of collaborative packing, and as a first step, we explore the mechanisms underlying human packing strategies. Specifically, we conducted a user study in which 100 human participants completed a series of packing tasks in a virtual environment. We analyzed their packing strategies and discovered that they exhibit specific spatial and temporal patterns (e.g., humans tend to place larger items into corners first). We expect that imbuing an artificial agent with an understanding of such a spatiotemporal structure will enable improved assistance, which will be reflected in the task performance and human perception of the artificial agent. Ongoing work involves the development of a framework that incorporates the extracted insights to predict and manipulate human decision making towards an efficient trajectory of low cognitive load. A follow-up study will evaluate our framework against a set of baselines featuring distinct strategies of assistance. Our eventual goal is the deployment and evaluation of our framework on an autonomous robotic manipulator, actively assisting users on a packing task.
Robot-Assisted Feeding: Generalizing Skewering Strategies across Food Items on a Realistic Plate
Jun 05, 2019
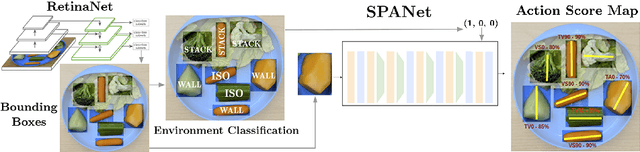


A robot-assisted feeding system must successfully acquire many different food items and transfer them to a user. A key challenge is the wide variation in the physical properties of food, demanding diverse acquisition strategies that are also capable of adapting to previously unseen items. Our key insight is that items with similar physical properties will exhibit similar success rates across an action space, allowing us to generalize to previously unseen items. To better understand which acquisition strategies work best for varied food items, we collected a large, rich dataset of 2450 robot bite acquisition trials for 16 food items with varying properties. Analyzing the dataset provided insights into how the food items' surrounding environment, fork pitch, and fork roll angles affect bite acquisition success. We then developed a bite acquisition framework that takes the image of a full plate as an input, uses RetinaNet to create bounding boxes around food items in the image, and then applies our skewering-position-action network (SPANet) to choose a target food item and a corresponding action so that the bite acquisition success rate is maximized. SPANet also uses the surrounding environment features of food items to predict action success rates. We used this framework to perform multiple experiments on uncluttered and cluttered plates with in-class and out-of-class food items. Results indicate that SPANet can successfully generalize skewering strategies to previously unseen food items.
Imitation Learning as $f$-Divergence Minimization
May 30, 2019

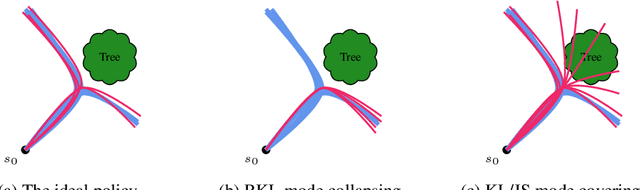
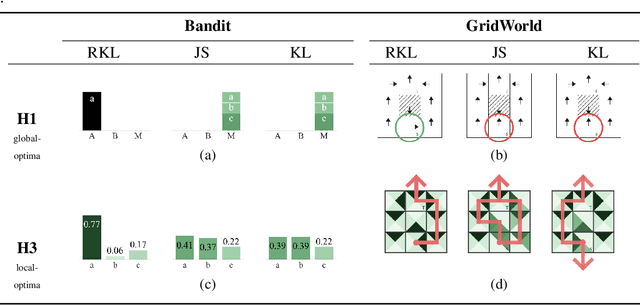
We address the problem of imitation learning with multi-modal demonstrations. Instead of attempting to learn all modes, we argue that in many tasks it is sufficient to imitate any one of them. We show that the state-of-the-art methods such as GAIL and behavior cloning, due to their choice of loss function, often incorrectly interpolate between such modes. Our key insight is to minimize the right divergence between the learner and the expert state-action distributions, namely the reverse KL divergence or I-projection. We propose a general imitation learning framework for estimating and minimizing any f-Divergence. By plugging in different divergences, we are able to recover existing algorithms such as Behavior Cloning (Kullback-Leibler), GAIL (Jensen Shannon) and Dagger (Total Variation). Empirical results show that our approximate I-projection technique is able to imitate multi-modal behaviors more reliably than GAIL and behavior cloning.
Towards Robotic Feeding: Role of Haptics in Fork-based Food Manipulation
Feb 24, 2019

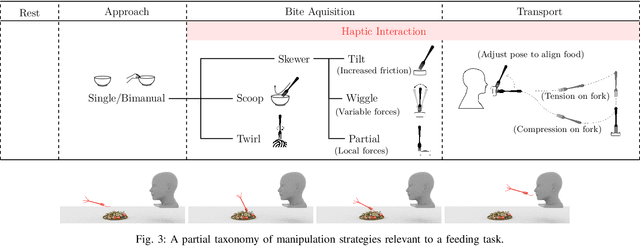

Autonomous feeding is challenging because it requires manipulation of food items with various compliance, sizes, and shapes. To understand how humans manipulate food items during feeding and to explore ways to adapt their strategies to robots, we collected a rich dataset of human trajectories by asking them to pick up food and feed it to a mannequin. From the analysis of the collected haptic and motion signals, we demonstrate that humans adapt their control policies to accommodate to the compliance and shape of the food item being acquired. We propose a taxonomy of manipulation strategies for feeding to highlight such policies. As a first step to generate compliance-dependent policies, we propose a set of classifiers for compliance-based food categorization from haptic and motion signals. We compare these human manipulation strategies with fixed position-control policies via a robot. Our analysis of success and failure cases of human and robot policies further highlights the importance of adapting the policy to the compliance of a food item.
* 8 pages
Bayes-CPACE: PAC Optimal Exploration in Continuous Space Bayes-Adaptive Markov Decision Processes
Oct 06, 2018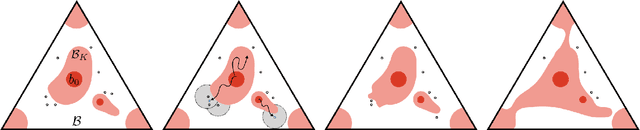
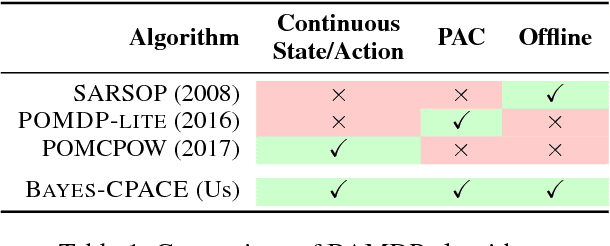

We present the first PAC optimal algorithm for Bayes-Adaptive Markov Decision Processes (BAMDPs) in continuous state and action spaces, to the best of our knowledge. The BAMDP framework elegantly addresses model uncertainty by incorporating Bayesian belief updates into long-term expected return. However, computing an exact optimal Bayesian policy is intractable. Our key insight is to compute a near-optimal value function by covering the continuous state-belief-action space with a finite set of representative samples and exploiting the Lipschitz continuity of the value function. We prove the near-optimality of our algorithm and analyze a number of schemes that boost the algorithm's efficiency. Finally, we empirically validate our approach on a number of discrete and continuous BAMDPs and show that the learned policy has consistently competitive performance against baseline approaches.
Bayesian Policy Optimization for Model Uncertainty
Oct 01, 2018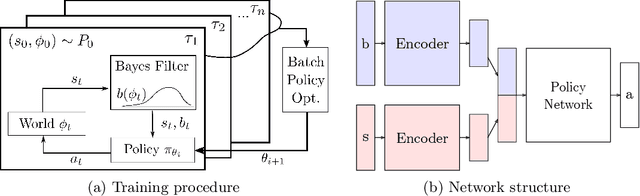

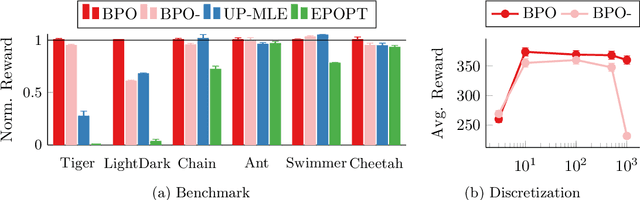
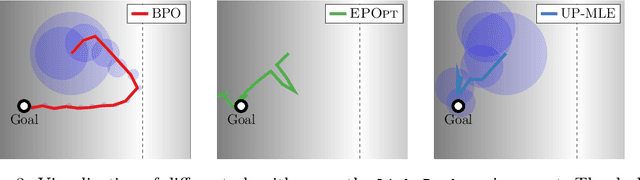
Addressing uncertainty is critical for autonomous systems to robustly adapt to the real world. We formulate the problem of model uncertainty as a continuous Bayes-Adaptive Markov Decision Process (BAMDP), where an agent maintains a posterior distribution over the latent model parameters given a history of observations and maximizes its expected long-term reward with respect to this belief distribution. Our algorithm, Bayesian Policy Optimization, builds on recent policy optimization algorithms to learn a universal policy that navigates the exploration-exploitation trade-off to maximize the Bayesian value function. To address challenges from discretizing the continuous latent parameter space, we propose a policy network architecture that independently encodes the belief distribution from the observable state. Our method significantly outperforms algorithms that address model uncertainty without explicitly reasoning about belief distributions, and is competitive with state-of-the-art Partially Observable Markov Decision Process solvers.
Hybrid DDP in Clutter (CHDDP): Trajectory Optimization for Hybrid Dynamical System in Cluttered Environments
Oct 14, 2017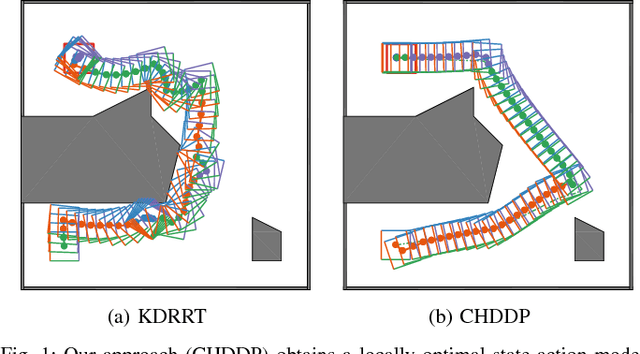
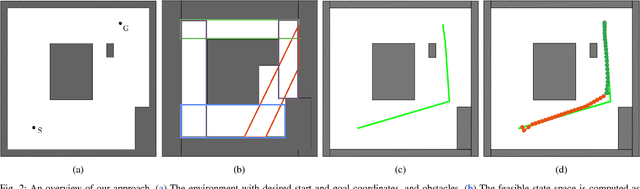
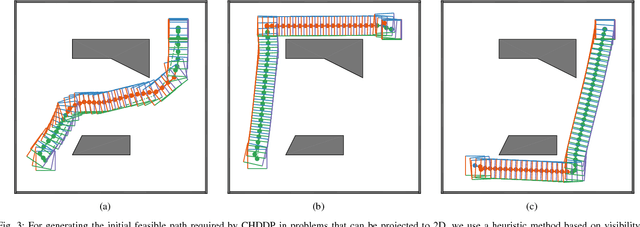
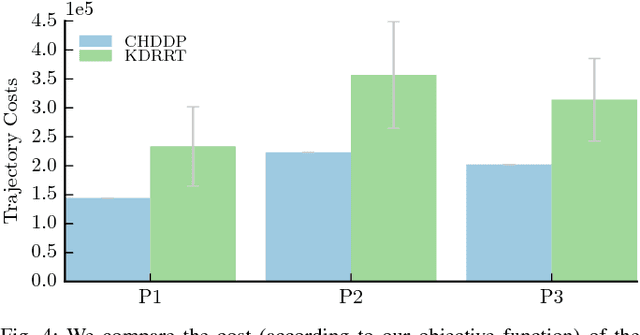
We present an algorithm for obtaining an optimal control policy for hybrid dynamical systems in cluttered environments. To the best of our knowledge, this is the first attempt to have a locally optimal solution for this specific problem setting. Our approach extends an optimal control algorithm for hybrid dynamical systems in the obstacle-free case to environments with obstacles. Our method does not require any preset mode sequence or heuristics to prune the exponential search of mode sequences. By first solving the relaxed problem of getting an obstacle-free, dynamically feasible trajectory and then solving for both obstacle-avoidance and optimality, we can generate smooth, locally optimal control policies. We demonstrate the performance of our algorithm on a box-pushing example in a number of environments against the baseline of randomly sampling modes and actions with a Kinodynamic RRT.
Unsupervised Learning for Nonlinear PieceWise Smooth Hybrid Systems
Oct 02, 2017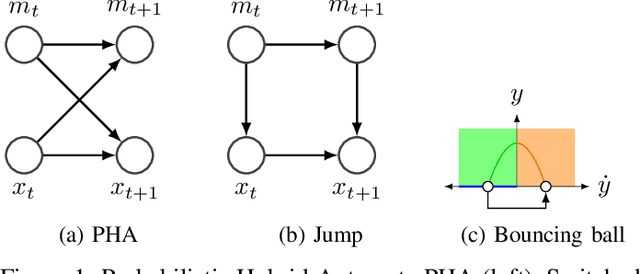
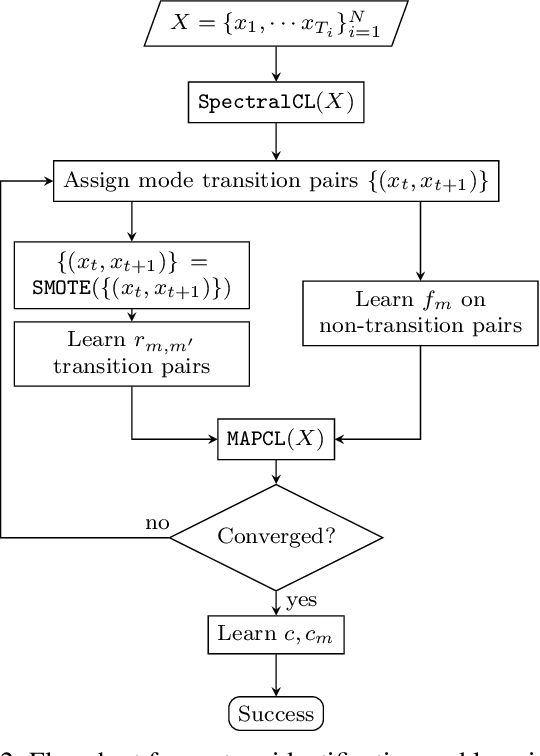
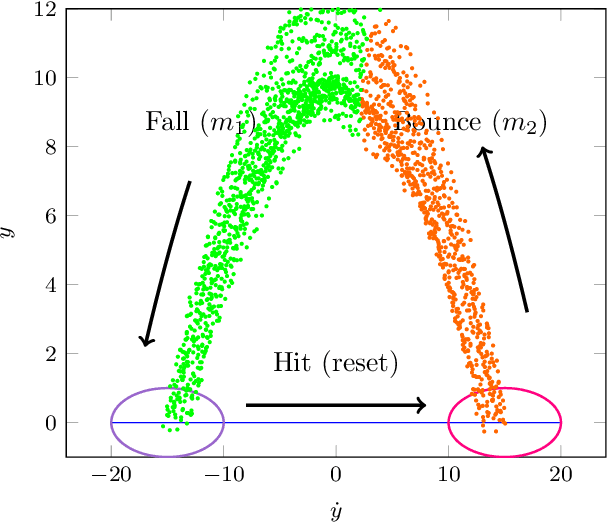
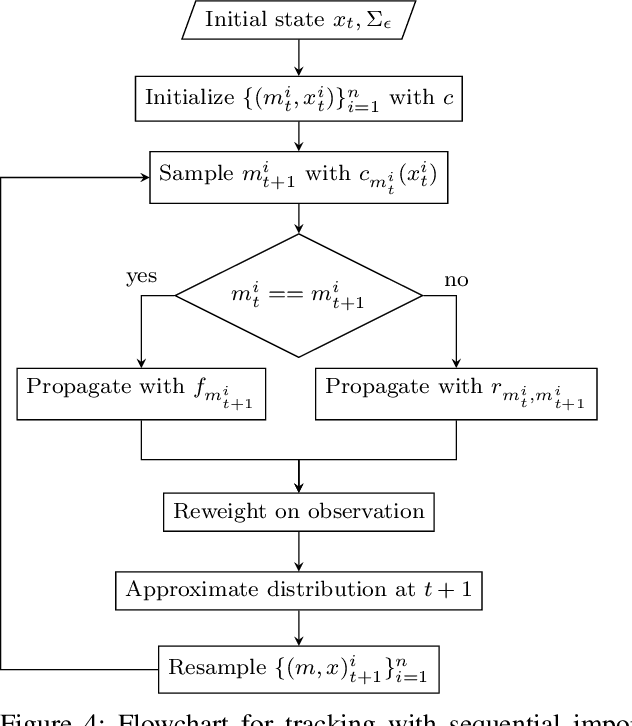
This paper introduces a novel system identification and tracking method for PieceWise Smooth (PWS) nonlinear stochastic hybrid systems. We are able to correctly identify and track challenging problems with diverse dynamics and low dimensional transitions. We exploit the composite structure system to learn a simpler model on each component/mode. We use Gaussian Process Regression techniques to learn smooth, nonlinear manifolds across mode transitions, guard-regions, and make multi-step ahead predictions on each mode dynamics. We combine a PWS non-linear model with a particle filter to effectively track multi-modal transitions. We further use synthetic oversampling techniques to address the challenge of detecting mode transition which is sparse compared to mode dynamics. This work provides an effective form of model learning in a complex hybrid system, which can be useful for future integration in a reinforcement learning setting. We compare multi-step prediction and tracking performance against traditional dynamical system tracking methods, such as EKF and Switching Gaussian Processes, and show that this framework performs significantly better, being able to correctly track complex dynamics with sparse transitions.