 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Residual Policy Optimization: Scalable Bayesian Reinforcement Learning with Clairvoyant Experts
Paper and Code
Feb 07, 2020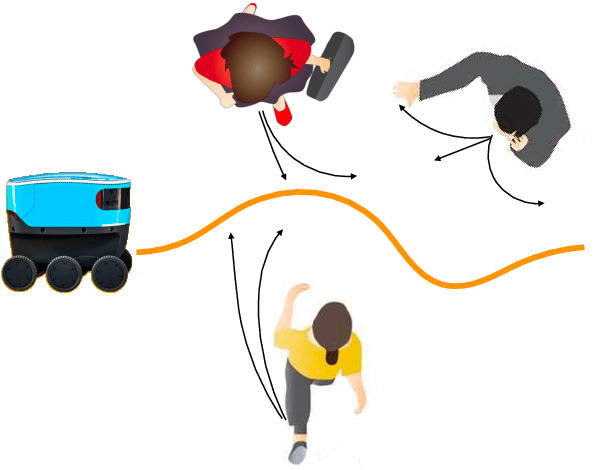
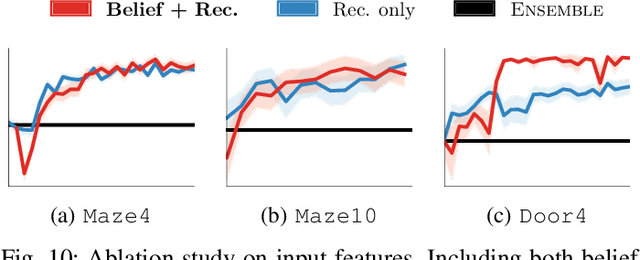
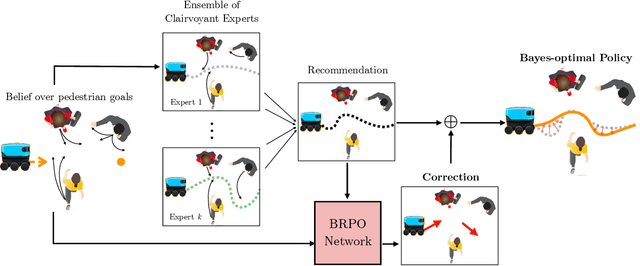
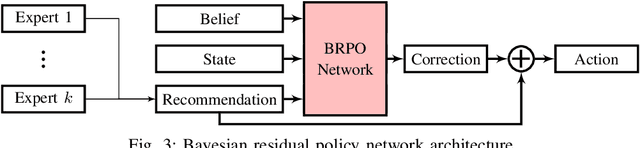
Informed and robust decision making in the face of uncertainty is critical for robots that perform physical tasks alongside people. We formulate this as Bayesian Reinforcement Learning over latent Markov Decision Processes (MDPs). While Bayes-optimality is theoretically the gold standard, existing algorithms do not scale well to continuous state and action spaces. Our proposal builds on the following insight: in the absence of uncertainty, each latent MDP is easier to solve. We first obtain an ensemble of experts, one for each latent MDP, and fuse their advice to compute a baseline policy. Next, we train a Bayesian residual policy to improve upon the ensemble's recommendation and learn to reduce uncertainty. Our algorithm, Bayesian Residual Policy Optimization (BRPO), imports the scalability of policy gradient methods and task-specific expert skills. BRPO significantly improves the ensemble of experts and drastically outperforms existing adaptive RL methods.