 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Ways of Working with Users to Develop Physically Assistive Robots
Mar 07, 2024
Despite the growth of physically assistive robotics (PAR) research over the last decade, nearly half of PAR user studies do not involve participants with the target disabilities. There are several reasons for this -- recruitment challenges, small sample sizes, and transportation logistics -- all influenced by systemic barriers that people with disabilities face. However, it is well-established that working with end-users results in technology that better addresses their needs and integrates with their lived circumstances. In this paper, we reflect on multiple approaches we have taken to working with people with motor impairments across the design, development, and evaluation of three PAR projects: (a) assistive feeding with a robot arm; (b) assistive teleoperation with a mobile manipulator; and (c) shared control with a robot arm. We discuss these approaches to working with users along three dimensions -- individual vs. community-level insight, logistic burden on end-users vs. researchers, and benefit to researchers vs. community -- and share recommendations for how other PAR researchers can incorporate users into their work.
Online augmentation of learned grasp sequence policies for more adaptable and data-efficient in-hand manipulation
Apr 04, 2023
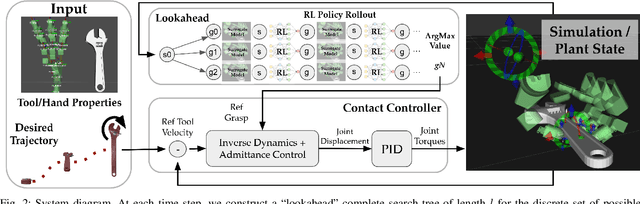
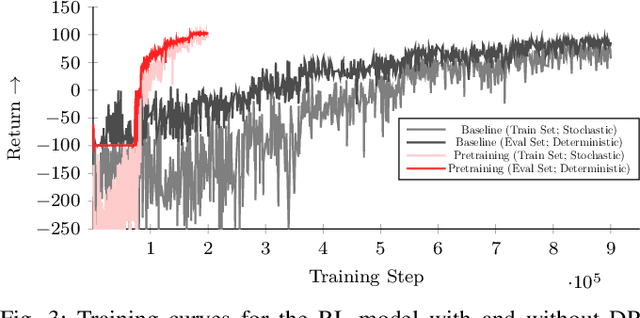
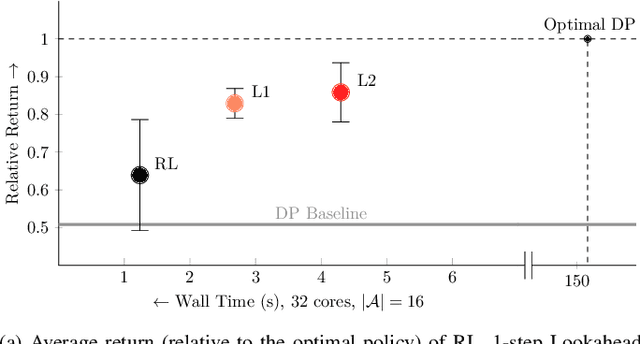
When using a tool, the grasps used for picking it up, reposing, and holding it in a suitable pose for the desired task could be distinct. Therefore, a key challenge for autonomous in-hand tool manipulation is finding a sequence of grasps that facilitates every step of the tool use process while continuously maintaining force closure and stability. Due to the complexity of modeling the contact dynamics, reinforcement learning (RL) techniques can provide a solution in this continuous space subject to highly parameterized physical models. However, these techniques impose a trade-off in adaptability and data efficiency. At test time the tool properties, desired trajectory, and desired application forces could differ substantially from training scenarios. Adapting to this necessitates more data or computationally expensive online policy updates. In this work, we apply the principles of discrete dynamic programming (DP) to augment RL performance with domain knowledge. Specifically, we first design a computationally simple approximation of our environment. We then demonstrate in physical simulation that performing tree searches (i.e., lookaheads) and policy rollouts with this approximation can improve an RL-derived grasp sequence policy with minimal additional online computation. Additionally, we show that pretraining a deep RL network with the DP-derived solution to the discretized problem can speed up policy training.
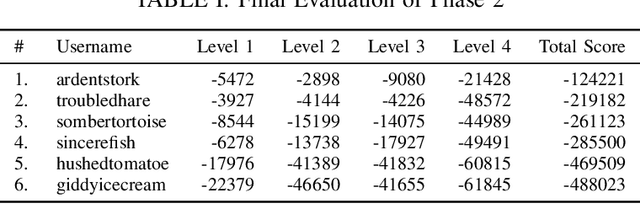
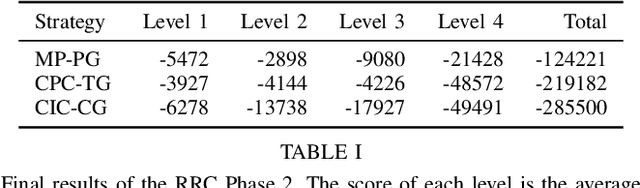
Real Robot Challenge 2021: Cartesian Position Control with Triangle Grasp and Trajectory Interpolation
Mar 19, 2022
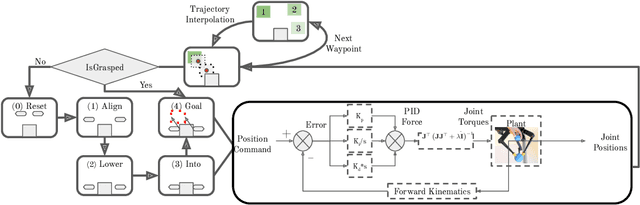


We present our runner-up approach for the Real Robot Challenge 2021. We build upon our previous approach used in Real Robot Challenge 2020. To solve the task of sequential goal-reaching we focus on two aspects to achieving near-optimal trajectory: Grasp stability and Controller performance. In the RRC 2021 simulated challenge, our method relied on a hand-designed Pinch grasp combined with Trajectory Interpolation for better stability during the motion for fast goal-reaching. In Stage 1, we observe reverting to a Triangular grasp to provide a more stable grasp when combined with Trajectory Interpolation, possibly due to the sim2real gap. The video demonstration for our approach is available at https://youtu.be/dlOueoaRWrM. The code is publicly available at https://github.com/madan96/benchmark-rrc.
Balancing Efficiency and Comfort in Robot-Assisted Bite Transfer
Nov 22, 2021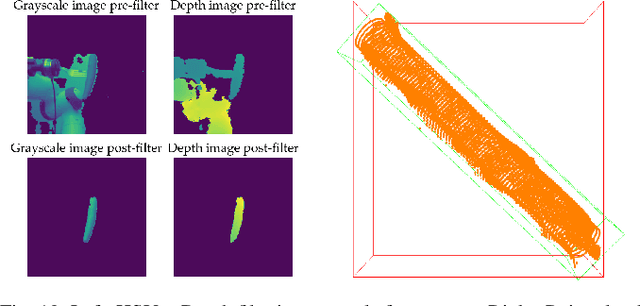
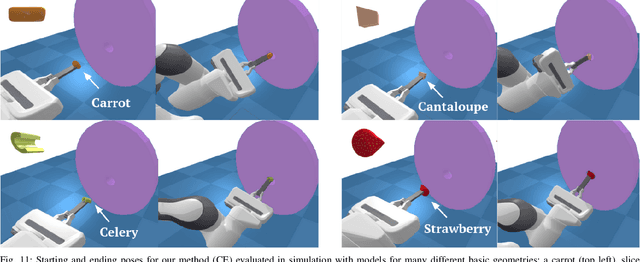

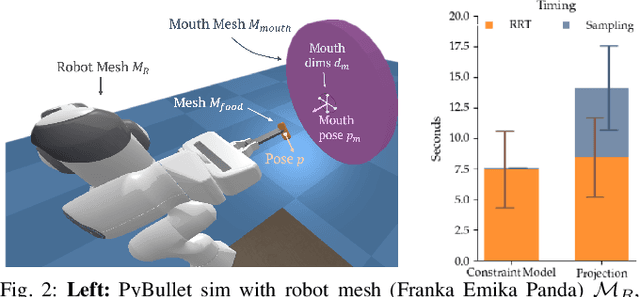
Robot-assisted feeding in household environments is challenging because it requires robots to generate trajectories that effectively bring food items of varying shapes and sizes into the mouth while making sure the user is comfortable. Our key insight is that in order to solve this challenge, robots must balance the efficiency of feeding a food item with the comfort of each individual bite. We formalize comfort and efficiency as heuristics to incorporate in motion planning. We present an approach based on heuristics-guided bi-directional Rapidly-exploring Random Trees (h-BiRRT) that selects bite transfer trajectories of arbitrary food item geometries and shapes using our developed bite efficiency and comfort heuristics and a learned constraint model. Real-robot evaluations show that optimizing both comfort and efficiency significantly outperforms a fixed-pose based method, and users preferred our method significantly more than that of a method that maximizes only user comfort. Videos and Appendices are found on our website: https://sites.google.com/view/comfortbitetransfer-icra22/home.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
Benchmarking Structured Policies and Policy Optimization for Real-World Dexterous Object Manipulation
May 05, 2021

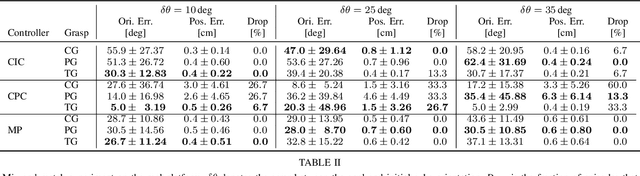
Dexterous manipulation is a challenging and important problem in robotics. While data-driven methods are a promising approach, current benchmarks require simulation or extensive engineering support due to the sample inefficiency of popular methods. We present benchmarks for the TriFinger system, an open-source robotic platform for dexterous manipulation and the focus of the 2020 Real Robot Challenge. The benchmarked methods, which were successful in the challenge, can be generally described as structured policies, as they combine elements of classical robotics and modern policy optimization. This inclusion of inductive biases facilitates sample efficiency, interpretability, reliability and high performance. The key aspects of this benchmarking is validation of the baselines across both simulation and the real system, thorough ablation study over the core features of each solution, and a retrospective analysis of the challenge as a manipulation benchmark. The code and demo videos for this work can be found on our website (https://sites.google.com/view/benchmark-rrc).
Leveraging Post Hoc Context for Faster Learning in Bandit Settings with Applications in Robot-Assisted Feeding
Nov 05, 2020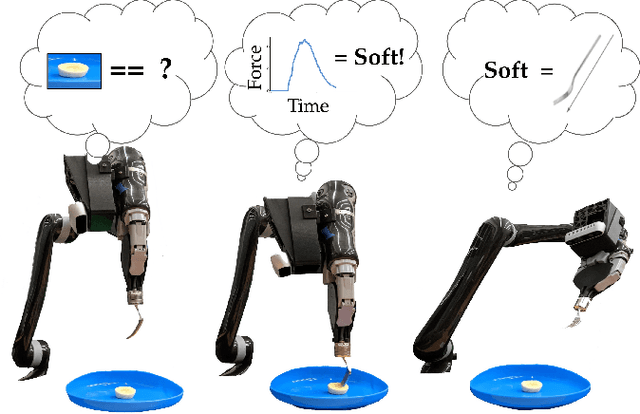
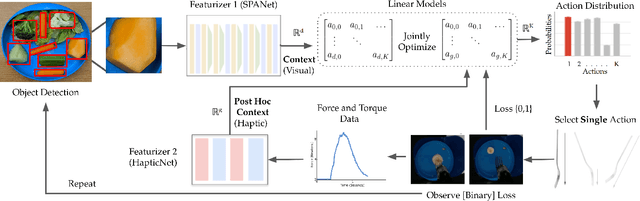


Autonomous robot-assisted feeding requires the ability to acquire a wide variety of food items. However, it is impossible for such a system to be trained on all types of food in existence. Therefore, a key challenge is choosing a manipulation strategy for a previously unseen food item. Previous work showed that the problem can be represented as a linear contextual bandit on visual information. However, food has a wide variety of multi-modal properties relevant to manipulation that can be hard to distinguish visually. Our key insight is that we can leverage the haptic information we collect during manipulation to learn some of these properties and more quickly adapt our visual model to previously unseen food. In general, we propose a modified linear contextual bandit framework augmented with post hoc context observed after action selection to empirically increase learning speed (as measured by cross-validation mean square error) and reduce cumulative regret. Experiments on synthetic data demonstrate that this effect is more pronounced when the dimensionality of the context is large relative to the post hoc context or when the post hoc context model is particularly easy to learn. Finally, we apply this framework to the bite acquisition problem and demonstrate the acquisition of 8 previously unseen types of food with 21% fewer failures across 64 attempts.
Adaptive Robot-Assisted Feeding: An Online Learning Framework for Acquiring Previously-Unseen Food Items
Sep 16, 2019
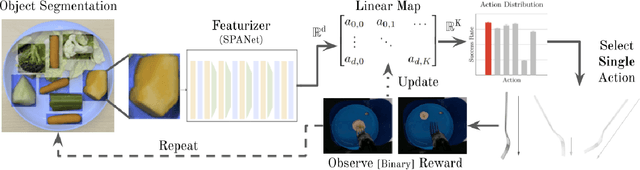
Successful robot-assisted feeding requires bite acquisition of a wide variety of food items. Different food items may require different manipulation actions for successful bite acquisition. Therefore, a key challenge is to handle previously-unseen food items with very different action distributions. By leveraging contexts from previous bite acquisition attempts, a robot should be able to learn online how to acquire those previously-unseen food items. We construct an online learning framework for this problem setting and use the $\epsilon$-greedy and LinUCB contextual bandit algorithms to minimize cumulative regret within that setting. Finally, we demonstrate empirically on a robot-assisted feeding system that this solution can adapt quickly to a food item with an action success rate distribution that differs greatly from previously-seen food items.
Robot-Assisted Feeding: Generalizing Skewering Strategies across Food Items on a Realistic Plate
Jun 05, 2019
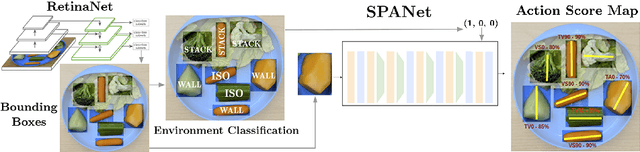


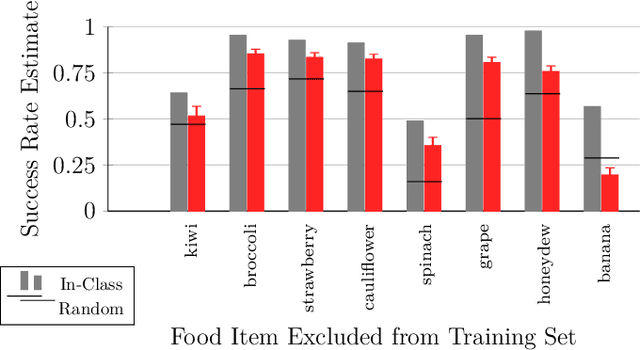
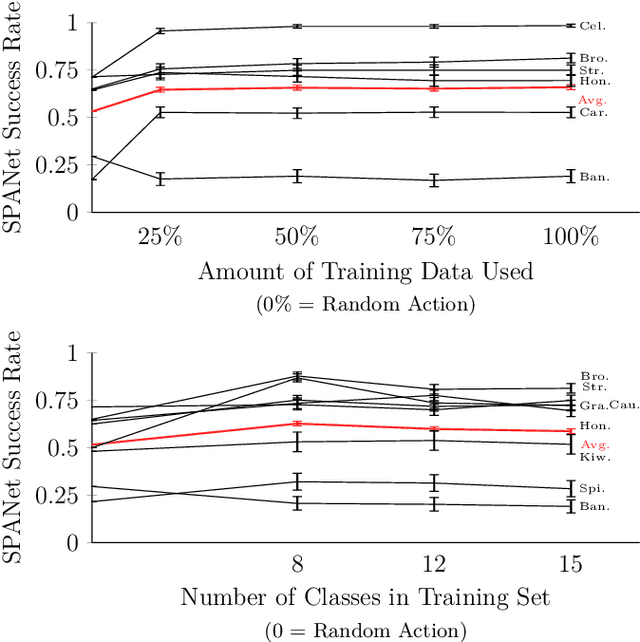
A robot-assisted feeding system must successfully acquire many different food items and transfer them to a user. A key challenge is the wide variation in the physical properties of food, demanding diverse acquisition strategies that are also capable of adapting to previously unseen items. Our key insight is that items with similar physical properties will exhibit similar success rates across an action space, allowing us to generalize to previously unseen items. To better understand which acquisition strategies work best for varied food items, we collected a large, rich dataset of 2450 robot bite acquisition trials for 16 food items with varying properties. Analyzing the dataset provided insights into how the food items' surrounding environment, fork pitch, and fork roll angles affect bite acquisition success. We then developed a bite acquisition framework that takes the image of a full plate as an input, uses RetinaNet to create bounding boxes around food items in the image, and then applies our skewering-position-action network (SPANet) to choose a target food item and a corresponding action so that the bite acquisition success rate is maximized. SPANet also uses the surrounding environment features of food items to predict action success rates. We used this framework to perform multiple experiments on uncluttered and cluttered plates with in-class and out-of-class food items. Results indicate that SPANet can successfully generalize skewering strategies to previously unseen food items.