 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Wildfire Localization on the NASA Autonomous Modular Sensor using Deep Learning
Jan 20, 2026High-altitude, multi-spectral, aerial imagery is scarce and expensive to acquire, yet it is necessary for algorithmic advances and application of machine learning models to high-impact problems such as wildfire detection. We introduce a human-annotated dataset from the NASA Autonomous Modular Sensor (AMS) using 12-channel, medium to high altitude (3 - 50 km) aerial wildfire images similar to those used in current US wildfire missions. Our dataset combines spectral data from 12 different channels, including infrared (IR), short-wave IR (SWIR), and thermal. We take imagery from 20 wildfire missions and randomly sample small patches to generate over 4000 images with high variability, including occlusions by smoke/clouds, easily-confused false positives, and nighttime imagery. We demonstrate results from a deep-learning model to automate the human-intensive process of fire perimeter determination. We train two deep neural networks, one for image classification and the other for pixel-level segmentation. The networks are combined into a unique real-time segmentation model to efficiently localize active wildfire on an incoming image feed. Our model achieves 96% classification accuracy, 74% Intersection-over-Union(IoU), and 84% recall surpassing past methods, including models trained on satellite data and classical color-rule algorithms. By leveraging a multi-spectral dataset, our model is able to detect active wildfire at nighttime and behind clouds, while distinguishing between false positives. We find that data from the SWIR, IR, and thermal bands is the most important to distinguish fire perimeters. Our code and dataset can be found here: https://github.com/nasa/Autonomous-Modular-Sensor-Wildfire-Segmentation/tree/main and https://drive.google.com/drive/folders/1-u4vs9rqwkwgdeeeoUhftCxrfe_4QPTn?=usp=drive_link
* 16 pages, 9 figures, published at AIAA SciTech 2026
Task-Driven Implicit Representations for Automated Design of LiDAR Systems
May 28, 2025Imaging system design is a complex, time-consuming, and largely manual process; LiDAR design, ubiquitous in mobile devices, autonomous vehicles, and aerial imaging platforms, adds further complexity through unique spatial and temporal sampling requirements. In this work, we propose a framework for automated, task-driven LiDAR system design under arbitrary constraints. To achieve this, we represent LiDAR configurations in a continuous six-dimensional design space and learn task-specific implicit densities in this space via flow-based generative modeling. We then synthesize new LiDAR systems by modeling sensors as parametric distributions in 6D space and fitting these distributions to our learned implicit density using expectation-maximization, enabling efficient, constraint-aware LiDAR system design. We validate our method on diverse tasks in 3D vision, enabling automated LiDAR system design across real-world-inspired applications in face scanning, robotic tracking, and object detection.
Blurred LiDAR for Sharper 3D: Robust Handheld 3D Scanning with Diffuse LiDAR and RGB
Nov 29, 2024



3D surface reconstruction is essential across applications of virtual reality, robotics, and mobile scanning. However, RGB-based reconstruction often fails in low-texture, low-light, and low-albedo scenes. Handheld LiDARs, now common on mobile devices, aim to address these challenges by capturing depth information from time-of-flight measurements of a coarse grid of projected dots. Yet, these sparse LiDARs struggle with scene coverage on limited input views, leaving large gaps in depth information. In this work, we propose using an alternative class of "blurred" LiDAR that emits a diffuse flash, greatly improving scene coverage but introducing spatial ambiguity from mixed time-of-flight measurements across a wide field of view. To handle these ambiguities, we propose leveraging the complementary strengths of diffuse LiDAR with RGB. We introduce a Gaussian surfel-based rendering framework with a scene-adaptive loss function that dynamically balances RGB and diffuse LiDAR signals. We demonstrate that, surprisingly, diffuse LiDAR can outperform traditional sparse LiDAR, enabling robust 3D scanning with accurate color and geometry estimation in challenging environments.
Find Rhinos without Finding Rhinos: Active Learning with Multimodal Imagery of South African Rhino Habitats
Sep 26, 2024


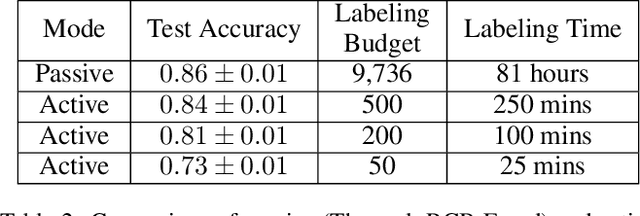
Much of Earth's charismatic megafauna is endangered by human activities, particularly the rhino, which is at risk of extinction due to the poaching crisis in Africa. Monitoring rhinos' movement is crucial to their protection but has unfortunately proven difficult because rhinos are elusive. Therefore, instead of tracking rhinos, we propose the novel approach of mapping communal defecation sites, called middens, which give information about rhinos' spatial behavior valuable to anti-poaching, management, and reintroduction efforts. This paper provides the first-ever mapping of rhino midden locations by building classifiers to detect them using remotely sensed thermal, RGB, and LiDAR imagery in passive and active learning settings. As existing active learning methods perform poorly due to the extreme class imbalance in our dataset, we design MultimodAL, an active learning system employing a ranking technique and multimodality to achieve competitive performance with passive learning models with 94% fewer labels. Our methods could therefore save over 76 hours in labeling time when used on a similarly-sized dataset. Unexpectedly, our midden map reveals that rhino middens are not randomly distributed throughout the landscape; rather, they are clustered. Consequently, rangers should be targeted at areas with high midden densities to strengthen anti-poaching efforts, in line with UN Target 15.7.
* 9 pages, 9 figures, IJCAI 2023 Special Track on AI for Good
A Decision-Language Model (DLM) for Dynamic Restless Multi-Armed Bandit Tasks in Public Health
Feb 23, 2024Efforts to reduce maternal mortality rate, a key UN Sustainable Development target (SDG Target 3.1), rely largely on preventative care programs to spread critical health information to high-risk populations. These programs face two important challenges: efficiently allocating limited health resources to large beneficiary populations, and adapting to evolving policy priorities. While prior works in restless multi-armed bandit (RMAB) demonstrated success in public health allocation tasks, they lack flexibility to adapt to evolving policy priorities. Concurrently, Large Language Models (LLMs) have emerged as adept, automated planners in various domains, including robotic control and navigation. In this paper, we propose DLM: a Decision Language Model for RMABs. To enable dynamic fine-tuning of RMAB policies for challenging public health settings using human-language commands, we propose using LLMs as automated planners to (1) interpret human policy preference prompts, (2) propose code reward functions for a multi-agent RL environment for RMABs, and (3) iterate on the generated reward using feedback from RMAB simulations to effectively adapt policy outcomes. In collaboration with ARMMAN, an India-based public health organization promoting preventative care for pregnant mothers, we conduct a simulation study, showing DLM can dynamically shape policy outcomes using only human language commands as input.
SUNDIAL: 3D Satellite Understanding through Direct, Ambient, and Complex Lighting Decomposition
Dec 24, 2023



3D modeling from satellite imagery is essential in areas of environmental science, urban planning, agriculture, and disaster response. However, traditional 3D modeling techniques face unique challenges in the remote sensing context, including limited multi-view baselines over extensive regions, varying direct, ambient, and complex illumination conditions, and time-varying scene changes across captures. In this work, we introduce SUNDIAL, a comprehensive approach to 3D reconstruction of satellite imagery using neural radiance fields. We jointly learn satellite scene geometry, illumination components, and sun direction in this single-model approach, and propose a secondary shadow ray casting technique to 1) improve scene geometry using oblique sun angles to render shadows, 2) enable physically-based disentanglement of scene albedo and illumination, and 3) determine the components of illumination from direct, ambient (sky), and complex sources. To achieve this, we incorporate lighting cues and geometric priors from remote sensing literature in a neural rendering approach, modeling physical properties of satellite scenes such as shadows, scattered sky illumination, and complex illumination and shading of vegetation and water. We evaluate the performance of SUNDIAL against existing NeRF-based techniques for satellite scene modeling and demonstrate improved scene and lighting disentanglement, novel view and lighting rendering, and geometry and sun direction estimation on challenging scenes with small baselines, sparse inputs, and variable illumination.
Towards Zero Shot Learning in Restless Multi-armed Bandits
Oct 23, 2023



Restless multi-arm bandits (RMABs), a class of resource allocation problems with broad application in areas such as healthcare, online advertising, and anti-poaching, have recently been studied from a multi-agent reinforcement learning perspective. Prior RMAB research suffers from several limitations, e.g., it fails to adequately address continuous states, and requires retraining from scratch when arms opt-in and opt-out over time, a common challenge in many real world applications. We address these limitations by developing a neural network-based pre-trained model (PreFeRMAB) that has general zero-shot ability on a wide range of previously unseen RMABs, and which can be fine-tuned on specific instances in a more sample-efficient way than retraining from scratch. Our model also accommodates general multi-action settings and discrete or continuous state spaces. To enable fast generalization, we learn a novel single policy network model that utilizes feature information and employs a training procedure in which arms opt-in and out over time. We derive a new update rule for a crucial $\lambda$-network with theoretical convergence guarantees and empirically demonstrate the advantages of our approach on several challenging, real-world inspired problems.
DISeR: Designing Imaging Systems with Reinforcement Learning
Sep 25, 2023

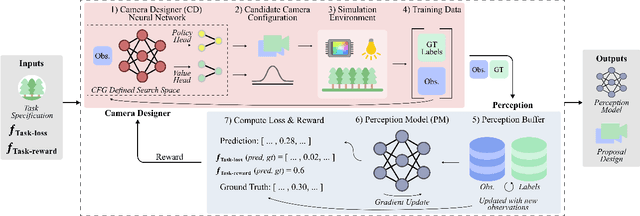

Imaging systems consist of cameras to encode visual information about the world and perception models to interpret this encoding. Cameras contain (1) illumination sources, (2) optical elements, and (3) sensors, while perception models use (4) algorithms. Directly searching over all combinations of these four building blocks to design an imaging system is challenging due to the size of the search space. Moreover, cameras and perception models are often designed independently, leading to sub-optimal task performance. In this paper, we formulate these four building blocks of imaging systems as a context-free grammar (CFG), which can be automatically searched over with a learned camera designer to jointly optimize the imaging system with task-specific perception models. By transforming the CFG to a state-action space, we then show how the camera designer can be implemented with reinforcement learning to intelligently search over the combinatorial space of possible imaging system configurations. We demonstrate our approach on two tasks, depth estimation and camera rig design for autonomous vehicles, showing that our method yields rigs that outperform industry-wide standards. We believe that our proposed approach is an important step towards automating imaging system design.
ORCa: Glossy Objects as Radiance Field Cameras
Dec 12, 2022
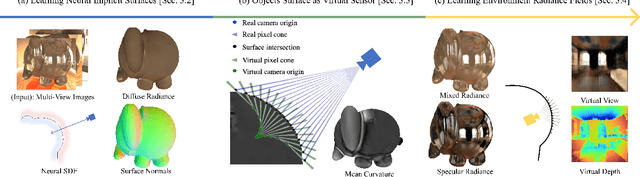
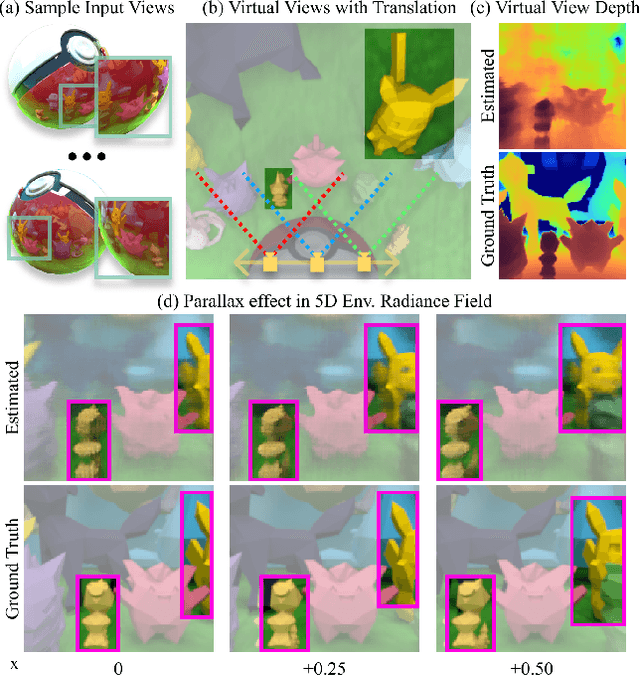
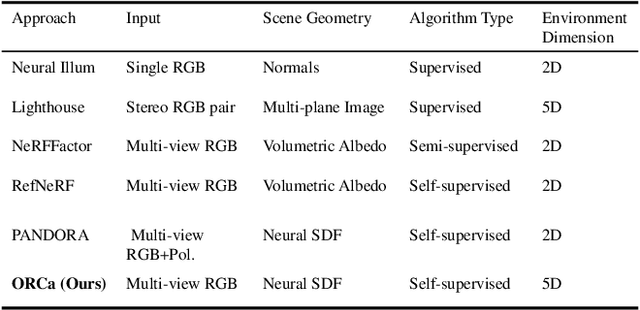
Reflections on glossy objects contain valuable and hidden information about the surrounding environment. By converting these objects into cameras, we can unlock exciting applications, including imaging beyond the camera's field-of-view and from seemingly impossible vantage points, e.g. from reflections on the human eye. However, this task is challenging because reflections depend jointly on object geometry, material properties, the 3D environment, and the observer viewing direction. Our approach converts glossy objects with unknown geometry into radiance-field cameras to image the world from the object's perspective. Our key insight is to convert the object surface into a virtual sensor that captures cast reflections as a 2D projection of the 5D environment radiance field visible to the object. We show that recovering the environment radiance fields enables depth and radiance estimation from the object to its surroundings in addition to beyond field-of-view novel-view synthesis, i.e. rendering of novel views that are only directly-visible to the glossy object present in the scene, but not the observer. Moreover, using the radiance field we can image around occluders caused by close-by objects in the scene. Our method is trained end-to-end on multi-view images of the object and jointly estimates object geometry, diffuse radiance, and the 5D environment radiance field.