 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Outlier Exposure for Out-of-Distribution Detection using Pretrained Transformers
Jul 19, 2023For real-world language applications, detecting an out-of-distribution (OOD) sample is helpful to alert users or reject such unreliable samples. However, modern over-parameterized language models often produce overconfident predictions for both in-distribution (ID) and OOD samples. In particular, language models suffer from OOD samples with a similar semantic representation to ID samples since these OOD samples lie near the ID manifold. A rejection network can be trained with ID and diverse outlier samples to detect test OOD samples, but explicitly collecting auxiliary OOD datasets brings an additional burden for data collection. In this paper, we propose a simple but effective method called Pseudo Outlier Exposure (POE) that constructs a surrogate OOD dataset by sequentially masking tokens related to ID classes. The surrogate OOD sample introduced by POE shows a similar representation to ID data, which is most effective in training a rejection network. Our method does not require any external OOD data and can be easily implemented within off-the-shelf Transformers. A comprehensive comparison with state-of-the-art algorithms demonstrates POE's competitiveness on several text classification benchmarks.
* 12 pages, 2 figures
Netmarble AI Center's WMT21 Automatic Post-Editing Shared Task Submission
Sep 14, 2021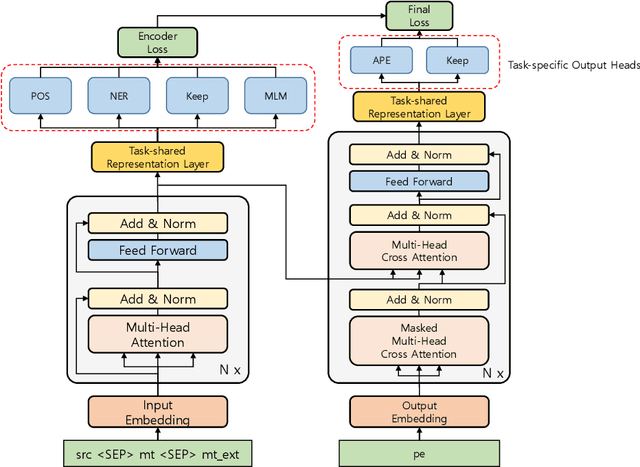
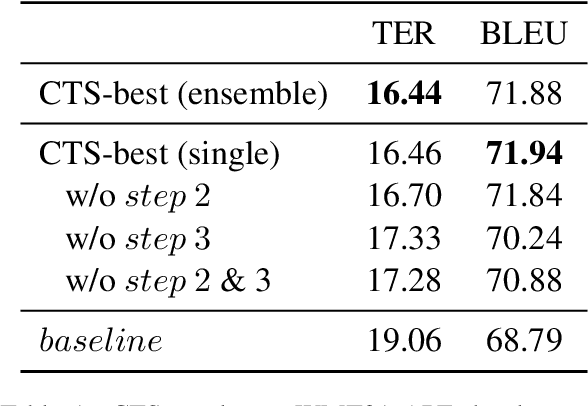
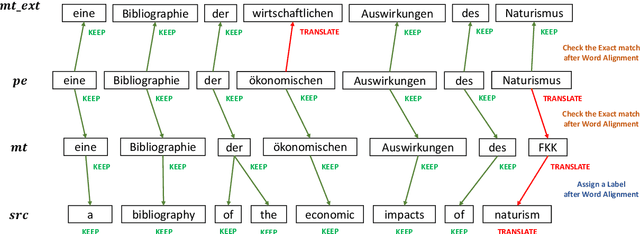

This paper describes Netmarble's submission to WMT21 Automatic Post-Editing (APE) Shared Task for the English-German language pair. First, we propose a Curriculum Training Strategy in training stages. Facebook Fair's WMT19 news translation model was chosen to engage the large and powerful pre-trained neural networks. Then, we post-train the translation model with different levels of data at each training stages. As the training stages go on, we make the system learn to solve multiple tasks by adding extra information at different training stages gradually. We also show a way to utilize the additional data in large volume for APE tasks. For further improvement, we apply Multi-Task Learning Strategy with the Dynamic Weight Average during the fine-tuning stage. To fine-tune the APE corpus with limited data, we add some related subtasks to learn a unified representation. Finally, for better performance, we leverage external translations as augmented machine translation (MT) during the post-training and fine-tuning. As experimental results show, our APE system significantly improves the translations of provided MT results by -2.848 and +3.74 on the development dataset in terms of TER and BLEU, respectively. It also demonstrates its effectiveness on the test dataset with higher quality than the development dataset.
Deep learning-based citation recommendation system for patents
Oct 21, 2020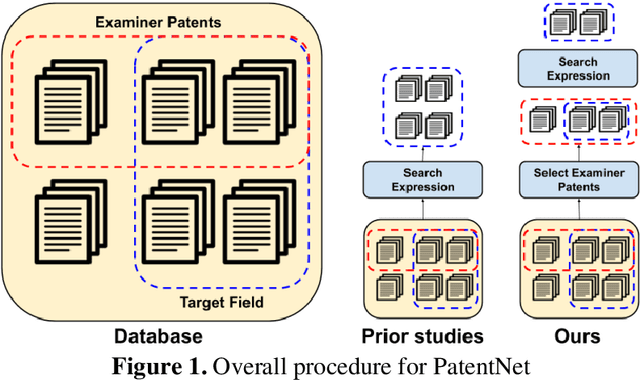
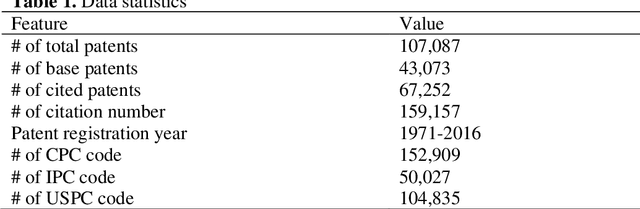
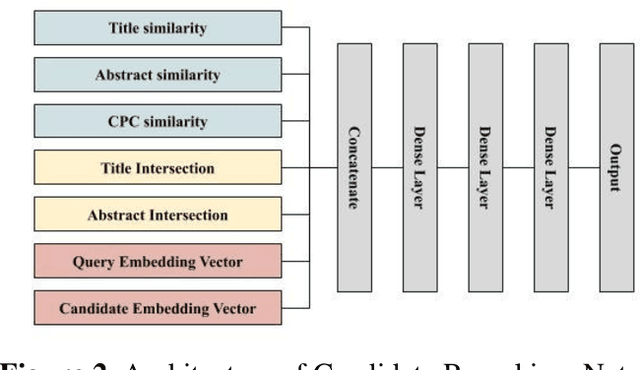

In this study, we address the challenges in developing a deep learning-based automatic patent citation recommendation system. Although deep learning-based recommendation systems have exhibited outstanding performance in various domains (such as movies, products, and paper citations), their validity in patent citations has not been investigated, owing to the lack of a freely available high-quality dataset and relevant benchmark model. To solve these problems, we present a novel dataset called PatentNet that includes textual information and metadata for approximately 110,000 patents from the Google Big Query service. Further, we propose strong benchmark models considering the similarity of textual information and metadata (such as cooperative patent classification code). Compared with existing recommendation methods, the proposed benchmark method achieved a mean reciprocal rank of 0.2377 on the test set, whereas the existing state-of-the-art recommendation method achieved 0.2073.
A Context-Aware Citation Recommendation Model with BERT and Graph Convolutional Networks
Mar 15, 2019

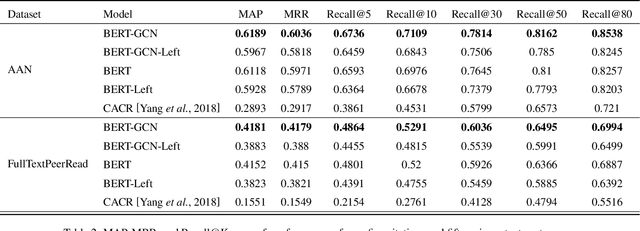
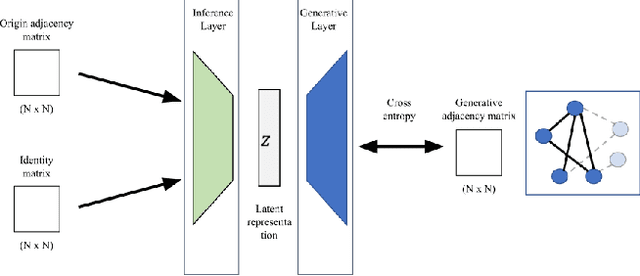
With the tremendous growth in the number of scientific papers being published, searching for references while writing a scientific paper is a time-consuming process. A technique that could add a reference citation at the appropriate place in a sentence will be beneficial. In this perspective, context-aware citation recommendation has been researched upon for around two decades. Many researchers have utilized the text data called the context sentence, which surrounds the citation tag, and the metadata of the target paper to find the appropriate cited research. However, the lack of well-organized benchmarking datasets and no model that can attain high performance has made the research difficult. In this paper, we propose a deep learning based model and well-organized dataset for context-aware paper citation recommendation. Our model comprises a document encoder and a context encoder, which uses Graph Convolutional Networks (GCN) layer and Bidirectional Encoder Representations from Transformers (BERT), which is a pre-trained model of textual data. By modifying the related PeerRead dataset, we propose a new dataset called FullTextPeerRead containing context sentences to cited references and paper metadata. To the best of our knowledge, This dataset is the first well-organized dataset for context-aware paper recommendation. The results indicate that the proposed model with the proposed datasets can attain state-of-the-art performance and achieve a more than 28% improvement in mean average precision (MAP) and recall@k.
Text Classification using Capsules
Aug 14, 2018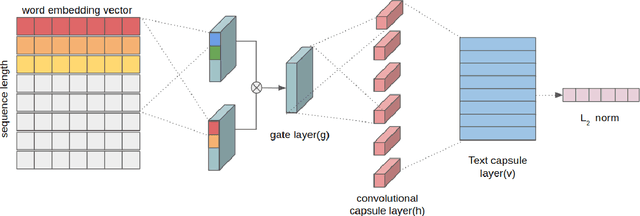
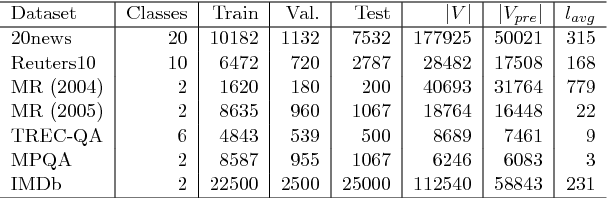
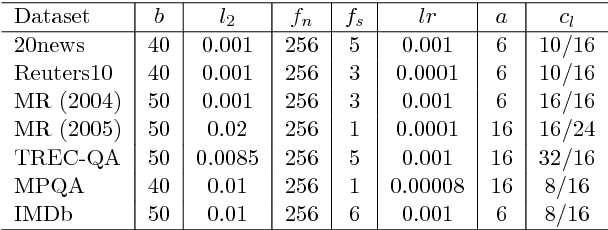

This paper presents an empirical exploration of the use of capsule networks for text classification. While it has been shown that capsule networks are effective for image classification, their validity in the domain of text has not been explored. In this paper, we show that capsule networks indeed have the potential for text classification and that they have several advantages over convolutional neural networks. We further suggest a simple routing method that effectively reduces the computational complexity of dynamic routing. We utilized seven benchmark datasets to demonstrate that capsule networks, along with the proposed routing method provide comparable results.