 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Low-Resource Unsupervised Neural MachineTranslation
Oct 18, 2020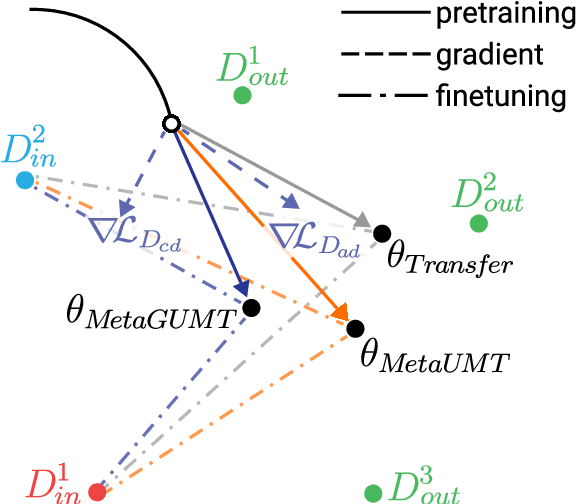
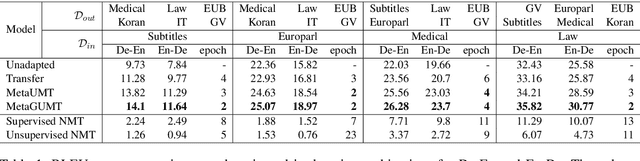
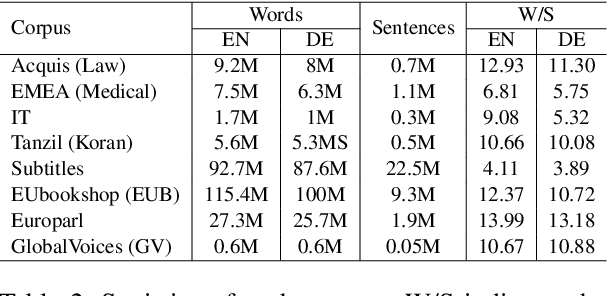

Unsupervised machine translation, which utilizes unpaired monolingual corpora as training data, has achieved comparable performance against supervised machine translation. However, it still suffers from data-scarce domains. To address this issue, this paper presents a meta-learning algorithm for unsupervised neural machine translation (UNMT) that trains the model to adapt to another domain by utilizing only a small amount of training data. We assume that domain-general knowledge is a significant factor in handling data-scarce domains. Hence, we extend the meta-learning algorithm, which utilizes knowledge learned from high-resource domains to boost the performance of low-resource UNMT. Our model surpasses a transfer learning-based approach by up to 2-4 BLEU scores. Extensive experimental results show that our proposed algorithm is pertinent for fast adaptation and consistently outperforms other baseline models.
A Context-Aware Citation Recommendation Model with BERT and Graph Convolutional Networks
Mar 15, 2019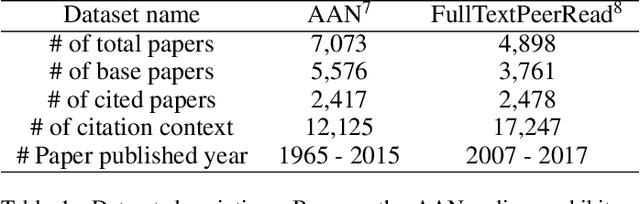

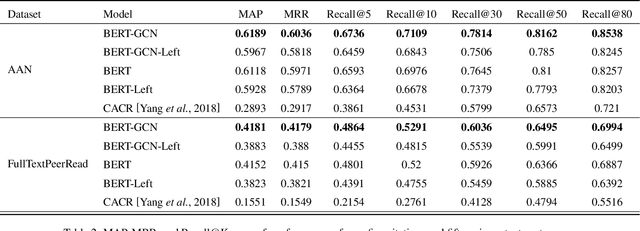
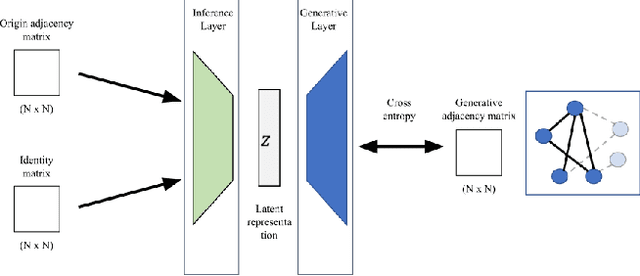
With the tremendous growth in the number of scientific papers being published, searching for references while writing a scientific paper is a time-consuming process. A technique that could add a reference citation at the appropriate place in a sentence will be beneficial. In this perspective, context-aware citation recommendation has been researched upon for around two decades. Many researchers have utilized the text data called the context sentence, which surrounds the citation tag, and the metadata of the target paper to find the appropriate cited research. However, the lack of well-organized benchmarking datasets and no model that can attain high performance has made the research difficult. In this paper, we propose a deep learning based model and well-organized dataset for context-aware paper citation recommendation. Our model comprises a document encoder and a context encoder, which uses Graph Convolutional Networks (GCN) layer and Bidirectional Encoder Representations from Transformers (BERT), which is a pre-trained model of textual data. By modifying the related PeerRead dataset, we propose a new dataset called FullTextPeerRead containing context sentences to cited references and paper metadata. To the best of our knowledge, This dataset is the first well-organized dataset for context-aware paper recommendation. The results indicate that the proposed model with the proposed datasets can attain state-of-the-art performance and achieve a more than 28% improvement in mean average precision (MAP) and recall@k.
Text Classification using Capsules
Aug 14, 2018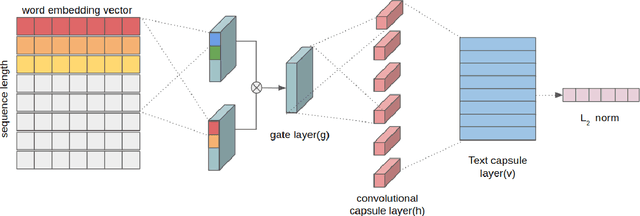
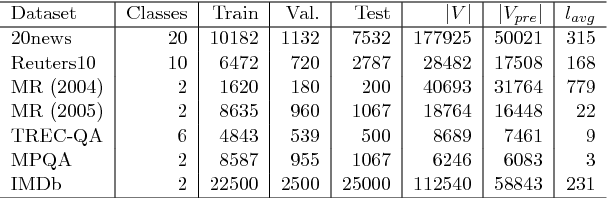
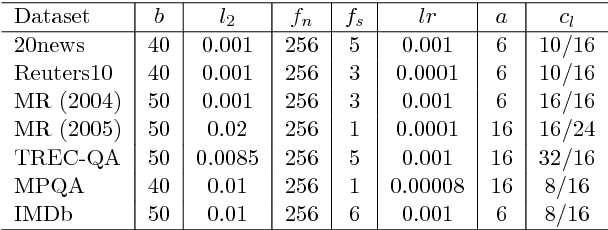

This paper presents an empirical exploration of the use of capsule networks for text classification. While it has been shown that capsule networks are effective for image classification, their validity in the domain of text has not been explored. In this paper, we show that capsule networks indeed have the potential for text classification and that they have several advantages over convolutional neural networks. We further suggest a simple routing method that effectively reduces the computational complexity of dynamic routing. We utilized seven benchmark datasets to demonstrate that capsule networks, along with the proposed routing method provide comparable results.