 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePePe: Personalized Post-editing Model utilizing User-generated Post-edits
Sep 21, 2022
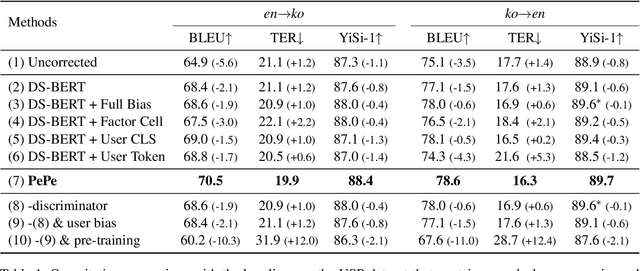
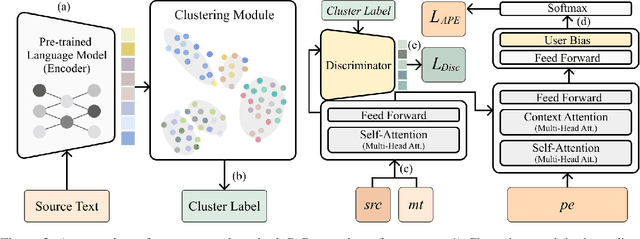
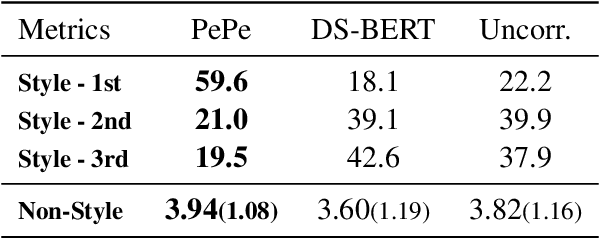
Incorporating personal preference is crucial in advanced machine translation tasks. Despite the recent advancement of machine translation, it remains a demanding task to properly reflect personal style. In this paper, we introduce a personalized automatic post-editing framework to address this challenge, which effectively generates sentences considering distinct personal behaviors. To build this framework, we first collect post-editing data that connotes the user preference from a live machine translation system. Specifically, real-world users enter source sentences for translation and edit the machine-translated outputs according to the user's preferred style. We then propose a model that combines a discriminator module and user-specific parameters on the APE framework. Experimental results show that the proposed method outperforms other baseline models on four different metrics (i.e., BLEU, TER, YiSi-1, and human evaluation).
A Visual Analytics System for Improving Attention-based Traffic Forecasting Models
Aug 11, 2022
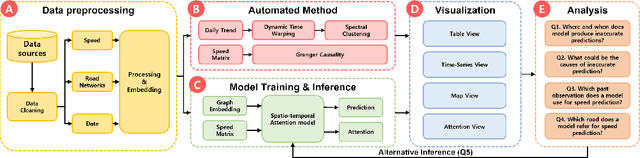
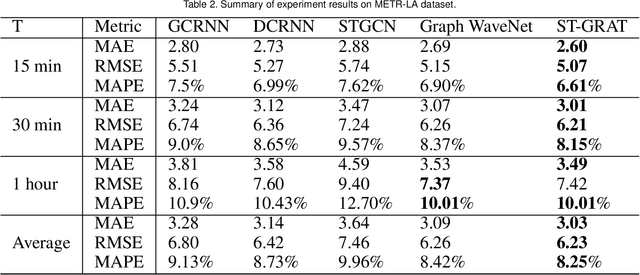
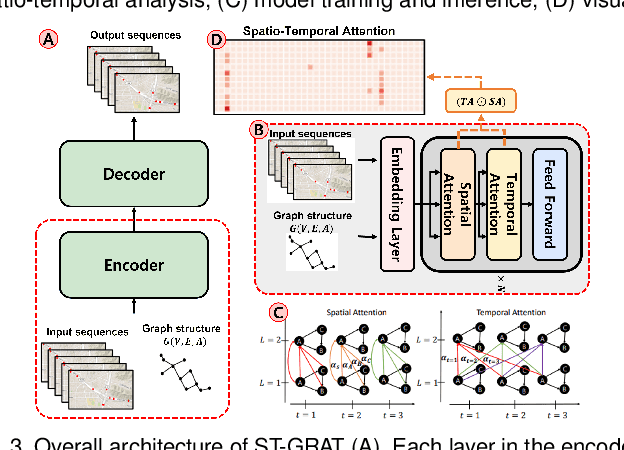
With deep learning (DL) outperforming conventional methods for different tasks, much effort has been devoted to utilizing DL in various domains. Researchers and developers in the traffic domain have also designed and improved DL models for forecasting tasks such as estimation of traffic speed and time of arrival. However, there exist many challenges in analyzing DL models due to the black-box property of DL models and complexity of traffic data (i.e., spatio-temporal dependencies). Collaborating with domain experts, we design a visual analytics system, AttnAnalyzer, that enables users to explore how DL models make predictions by allowing effective spatio-temporal dependency analysis. The system incorporates dynamic time warping (DTW) and Granger causality tests for computational spatio-temporal dependency analysis while providing map, table, line chart, and pixel views to assist user to perform dependency and model behavior analysis. For the evaluation, we present three case studies showing how AttnAnalyzer can effectively explore model behaviors and improve model performance in two different road networks. We also provide domain expert feedback.
Meta-Learning for Low-Resource Unsupervised Neural MachineTranslation
Oct 18, 2020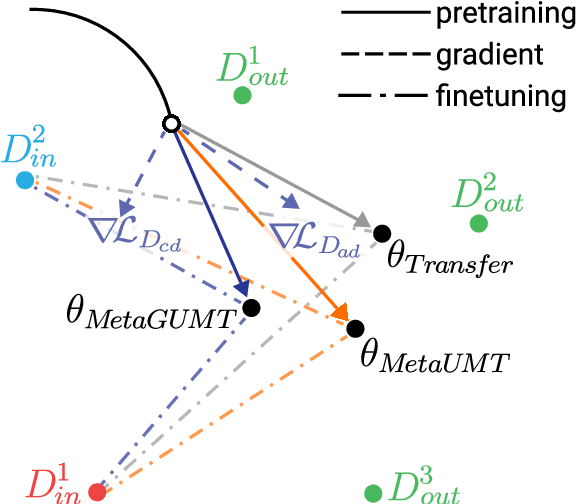
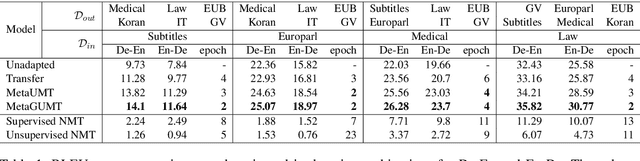

Unsupervised machine translation, which utilizes unpaired monolingual corpora as training data, has achieved comparable performance against supervised machine translation. However, it still suffers from data-scarce domains. To address this issue, this paper presents a meta-learning algorithm for unsupervised neural machine translation (UNMT) that trains the model to adapt to another domain by utilizing only a small amount of training data. We assume that domain-general knowledge is a significant factor in handling data-scarce domains. Hence, we extend the meta-learning algorithm, which utilizes knowledge learned from high-resource domains to boost the performance of low-resource UNMT. Our model surpasses a transfer learning-based approach by up to 2-4 BLEU scores. Extensive experimental results show that our proposed algorithm is pertinent for fast adaptation and consistently outperforms other baseline models.