 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRWEN-TTS: Relation-aware Word Encoding Network for Natural Text-to-Speech Synthesis
Dec 15, 2022With the advent of deep learning, a huge number of text-to-speech (TTS) models which produce human-like speech have emerged. Recently, by introducing syntactic and semantic information w.r.t the input text, various approaches have been proposed to enrich the naturalness and expressiveness of TTS models. Although these strategies showed impressive results, they still have some limitations in utilizing language information. First, most approaches only use graph networks to utilize syntactic and semantic information without considering linguistic features. Second, most previous works do not explicitly consider adjacent words when encoding syntactic and semantic information, even though it is obvious that adjacent words are usually meaningful when encoding the current word. To address these issues, we propose Relation-aware Word Encoding Network (RWEN), which effectively allows syntactic and semantic information based on two modules (i.e., Semantic-level Relation Encoding and Adjacent Word Relation Encoding). Experimental results show substantial improvements compared to previous works.
Netmarble AI Center's WMT21 Automatic Post-Editing Shared Task Submission
Sep 14, 2021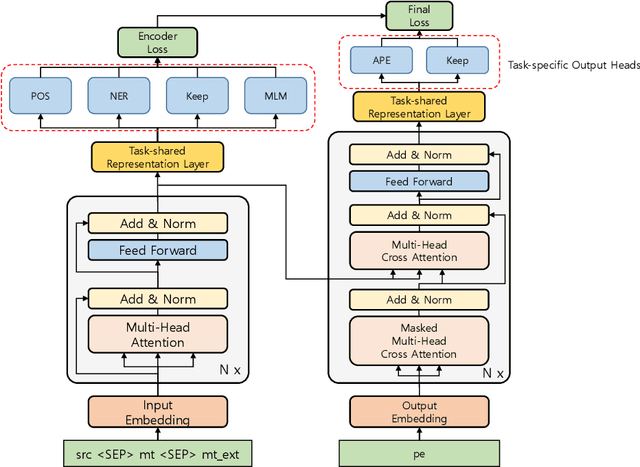
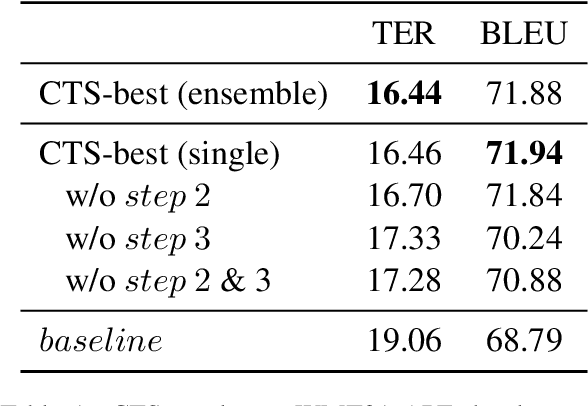
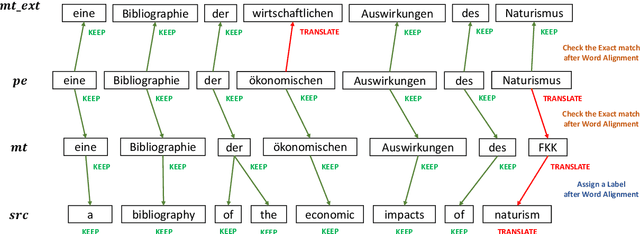

This paper describes Netmarble's submission to WMT21 Automatic Post-Editing (APE) Shared Task for the English-German language pair. First, we propose a Curriculum Training Strategy in training stages. Facebook Fair's WMT19 news translation model was chosen to engage the large and powerful pre-trained neural networks. Then, we post-train the translation model with different levels of data at each training stages. As the training stages go on, we make the system learn to solve multiple tasks by adding extra information at different training stages gradually. We also show a way to utilize the additional data in large volume for APE tasks. For further improvement, we apply Multi-Task Learning Strategy with the Dynamic Weight Average during the fine-tuning stage. To fine-tune the APE corpus with limited data, we add some related subtasks to learn a unified representation. Finally, for better performance, we leverage external translations as augmented machine translation (MT) during the post-training and fine-tuning. As experimental results show, our APE system significantly improves the translations of provided MT results by -2.848 and +3.74 on the development dataset in terms of TER and BLEU, respectively. It also demonstrates its effectiveness on the test dataset with higher quality than the development dataset.
Mel-spectrogram augmentation for sequence to sequence voice conversion
Jan 06, 2020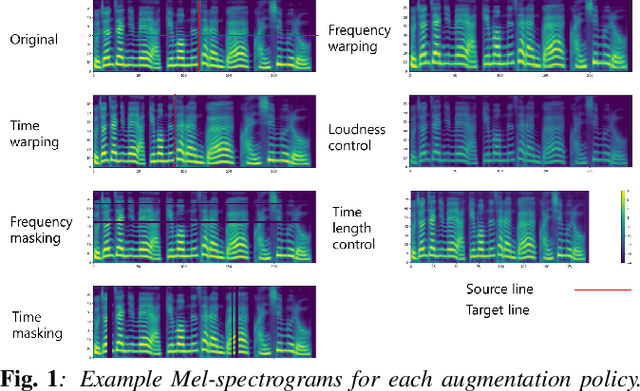

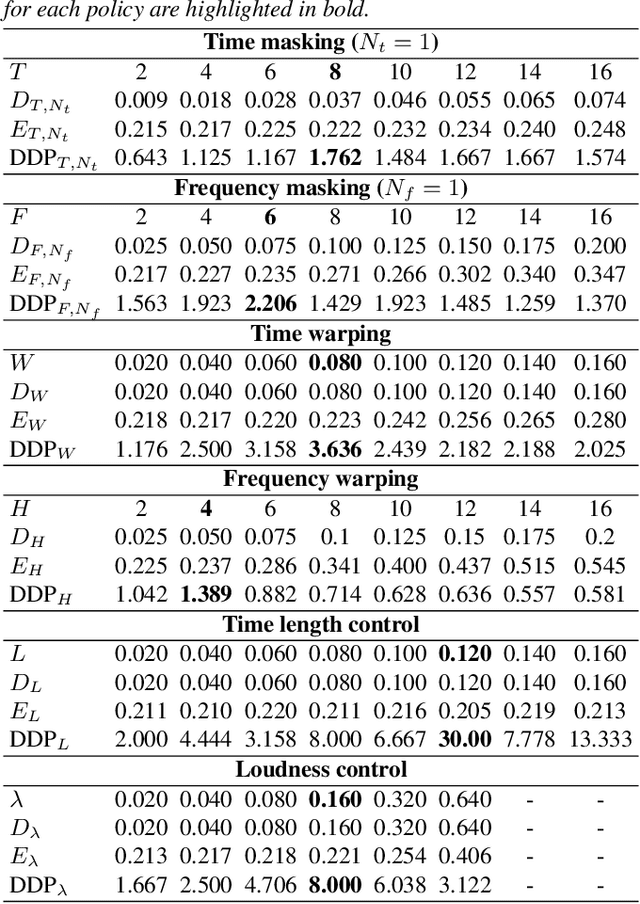
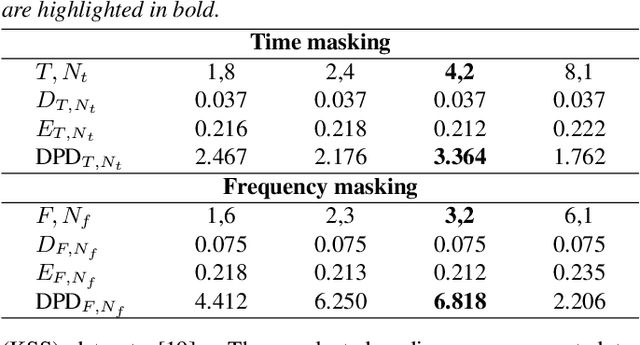
When training the sequence-to-sequence voice conversion model, we need to handle an issue of insufficient data about the number of speech tuples which consist of the same utterance. This study experimentally investigated the effects of Mel-spectrogram augmentation on the sequence-to-sequence voice conversion model. For Mel-spectrogram augmentation, we adopted the policies proposed in SpecAugment. In addition, we propose new policies for more data variations. To find the optimal hyperparameters of augmentation policies for voice conversion, we experimented based on the new metric, namely deformation per deteriorating ratio. We observed the effect of these through experiments based on various sizes of training set and combinations of augmentation policy. In the experimental results, the time axis warping based policies showed better performance than other policies.