 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-based citation recommendation system for patents
Oct 21, 2020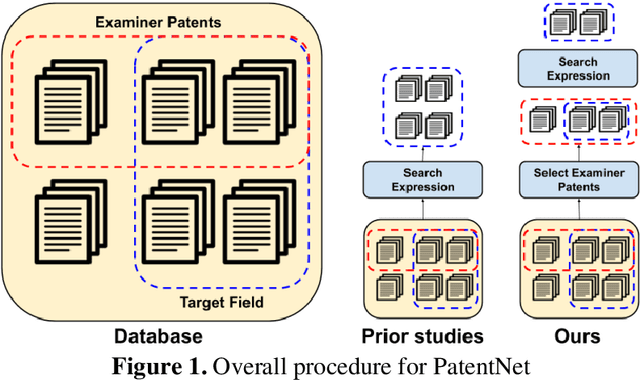
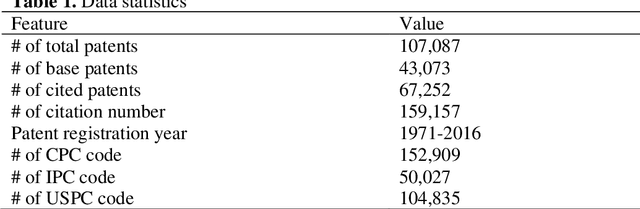
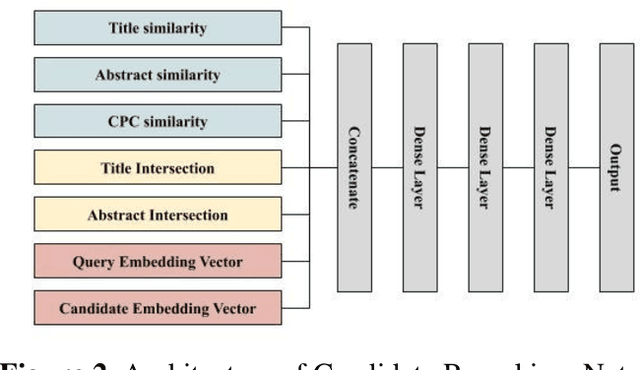

In this study, we address the challenges in developing a deep learning-based automatic patent citation recommendation system. Although deep learning-based recommendation systems have exhibited outstanding performance in various domains (such as movies, products, and paper citations), their validity in patent citations has not been investigated, owing to the lack of a freely available high-quality dataset and relevant benchmark model. To solve these problems, we present a novel dataset called PatentNet that includes textual information and metadata for approximately 110,000 patents from the Google Big Query service. Further, we propose strong benchmark models considering the similarity of textual information and metadata (such as cooperative patent classification code). Compared with existing recommendation methods, the proposed benchmark method achieved a mean reciprocal rank of 0.2377 on the test set, whereas the existing state-of-the-art recommendation method achieved 0.2073.