 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBézierFlow: Learning Bézier Stochastic Interpolant Schedulers for Few-Step Generation
Dec 28, 2025We introduce BézierFlow, a lightweight training approach for few-step generation with pretrained diffusion and flow models. BézierFlow achieves a 2-3x performance improvement for sampling with $\leq$ 10 NFEs while requiring only 15 minutes of training. Recent lightweight training approaches have shown promise by learning optimal timesteps, but their scope remains restricted to ODE discretizations. To broaden this scope, we propose learning the optimal transformation of the sampling trajectory by parameterizing stochastic interpolant (SI) schedulers. The main challenge lies in designing a parameterization that satisfies critical desiderata, including boundary conditions, differentiability, and monotonicity of the SNR. To effectively meet these requirements, we represent scheduler functions as Bézier functions, where control points naturally enforce these properties. This reduces the problem to learning an ordered set of points in the time range, while the interpretation of the points changes from ODE timesteps to Bézier control points. Across a range of pretrained diffusion and flow models, BézierFlow consistently outperforms prior timestep-learning methods, demonstrating the effectiveness of expanding the search space from discrete timesteps to Bézier-based trajectory transformations.
MatLat: Material Latent Space for PBR Texture Generation
Dec 19, 2025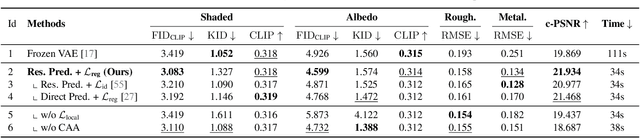
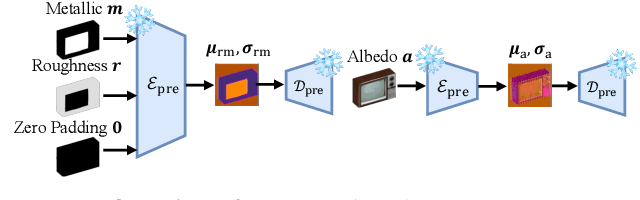
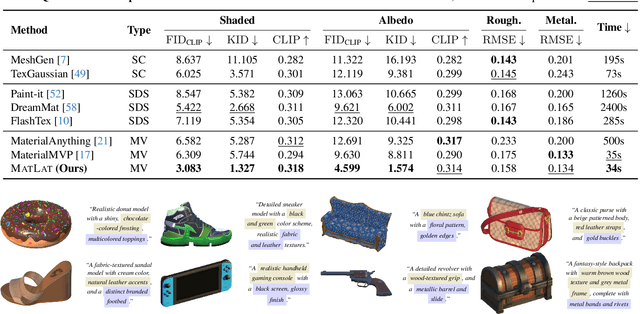
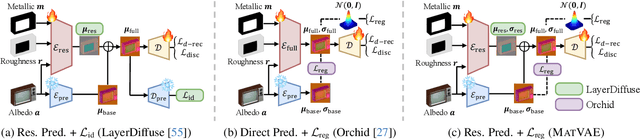
We propose a generative framework for producing high-quality PBR textures on a given 3D mesh. As large-scale PBR texture datasets are scarce, our approach focuses on effectively leveraging the embedding space and diffusion priors of pretrained latent image generative models while learning a material latent space, MatLat, through targeted fine-tuning. Unlike prior methods that freeze the embedding network and thus lead to distribution shifts when encoding additional PBR channels and hinder subsequent diffusion training, we fine-tune the pretrained VAE so that new material channels can be incorporated with minimal latent distribution deviation. We further show that correspondence-aware attention alone is insufficient for cross-view consistency unless the latent-to-image mapping preserves locality. To enforce this locality, we introduce a regularization in the VAE fine-tuning that crops latent patches, decodes them, and aligns the corresponding image regions to maintain strong pixel-latent spatial correspondence. Ablation studies and comparison with previous baselines demonstrate that our framework improves PBR texture fidelity and that each component is critical for achieving state-of-the-art performance.
BézierFlow: Bézier Stochastic Interpolant Schedulers for Few-Step Generation
Dec 15, 2025We introduce BézierFlow, a lightweight training approach for few-step generation with pretrained diffusion and flow models. BézierFlow achieves a 2-3x performance improvement for sampling with $\leq$ 10 NFEs while requiring only 15 minutes of training. Recent lightweight training approaches have shown promise by learning optimal timesteps, but their scope remains restricted to ODE discretizations. To broaden this scope, we propose learning the optimal transformation of the sampling trajectory by parameterizing stochastic interpolant (SI) schedulers. The main challenge lies in designing a parameterization that satisfies critical desiderata, including boundary conditions, differentiability, and monotonicity of the SNR. To effectively meet these requirements, we represent scheduler functions as Bézier functions, where control points naturally enforce these properties. This reduces the problem to learning an ordered set of points in the time range, while the interpretation of the points changes from ODE timesteps to Bézier control points. Across a range of pretrained diffusion and flow models, BézierFlow consistently outperforms prior timestep-learning methods, demonstrating the effectiveness of expanding the search space from discrete timesteps to Bézier-based trajectory transformations.
ORIGEN: Zero-Shot 3D Orientation Grounding in Text-to-Image Generation
Mar 28, 2025We introduce ORIGEN, the first zero-shot method for 3D orientation grounding in text-to-image generation across multiple objects and diverse categories. While previous work on spatial grounding in image generation has mainly focused on 2D positioning, it lacks control over 3D orientation. To address this, we propose a reward-guided sampling approach using a pretrained discriminative model for 3D orientation estimation and a one-step text-to-image generative flow model. While gradient-ascent-based optimization is a natural choice for reward-based guidance, it struggles to maintain image realism. Instead, we adopt a sampling-based approach using Langevin dynamics, which extends gradient ascent by simply injecting random noise--requiring just a single additional line of code. Additionally, we introduce adaptive time rescaling based on the reward function to accelerate convergence. Our experiments show that ORIGEN outperforms both training-based and test-time guidance methods across quantitative metrics and user studies.
DAFT-GAN: Dual Affine Transformation Generative Adversarial Network for Text-Guided Image Inpainting
Aug 09, 2024



In recent years, there has been a significant focus on research related to text-guided image inpainting. However, the task remains challenging due to several constraints, such as ensuring alignment between the image and the text, and maintaining consistency in distribution between corrupted and uncorrupted regions. In this paper, thus, we propose a dual affine transformation generative adversarial network (DAFT-GAN) to maintain the semantic consistency for text-guided inpainting. DAFT-GAN integrates two affine transformation networks to combine text and image features gradually for each decoding block. Moreover, we minimize information leakage of uncorrupted features for fine-grained image generation by encoding corrupted and uncorrupted regions of the masked image separately. Our proposed model outperforms the existing GAN-based models in both qualitative and quantitative assessments with three benchmark datasets (MS-COCO, CUB, and Oxford) for text-guided image inpainting.