 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuark: Real-time, High-resolution, and General Neural View Synthesis
Nov 25, 2024We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses, the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous works that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, generating the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates. Project page: https://quark-3d.github.io/
SimpleRecon: 3D Reconstruction Without 3D Convolutions
Aug 31, 2022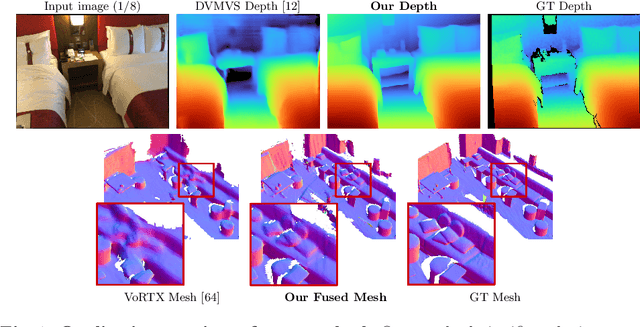
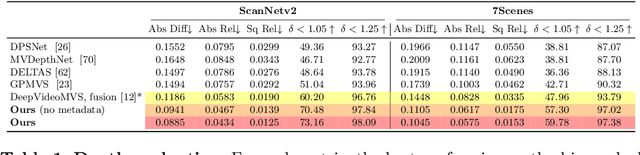
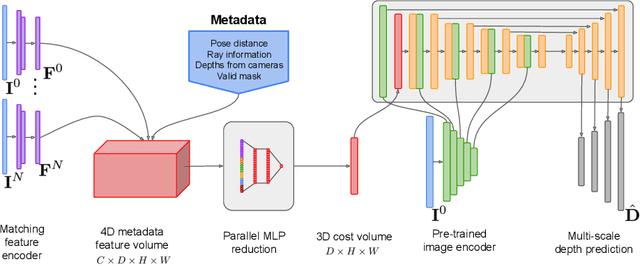
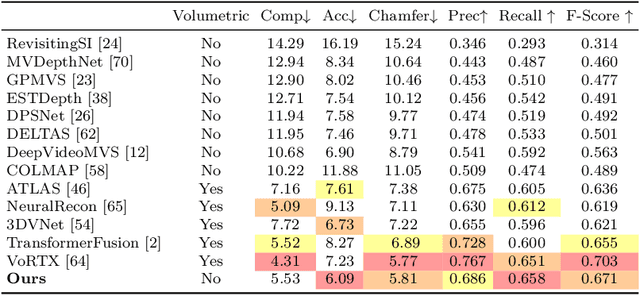
Traditionally, 3D indoor scene reconstruction from posed images happens in two phases: per-image depth estimation, followed by depth merging and surface reconstruction. Recently, a family of methods have emerged that perform reconstruction directly in final 3D volumetric feature space. While these methods have shown impressive reconstruction results, they rely on expensive 3D convolutional layers, limiting their application in resource-constrained environments. In this work, we instead go back to the traditional route, and show how focusing on high quality multi-view depth prediction leads to highly accurate 3D reconstructions using simple off-the-shelf depth fusion. We propose a simple state-of-the-art multi-view depth estimator with two main contributions: 1) a carefully-designed 2D CNN which utilizes strong image priors alongside a plane-sweep feature volume and geometric losses, combined with 2) the integration of keyframe and geometric metadata into the cost volume which allows informed depth plane scoring. Our method achieves a significant lead over the current state-of-the-art for depth estimation and close or better for 3D reconstruction on ScanNet and 7-Scenes, yet still allows for online real-time low-memory reconstruction. Code, models and results are available at https://nianticlabs.github.io/simplerecon
Digging Into Self-Supervised Monocular Depth Estimation
Jun 05, 2018
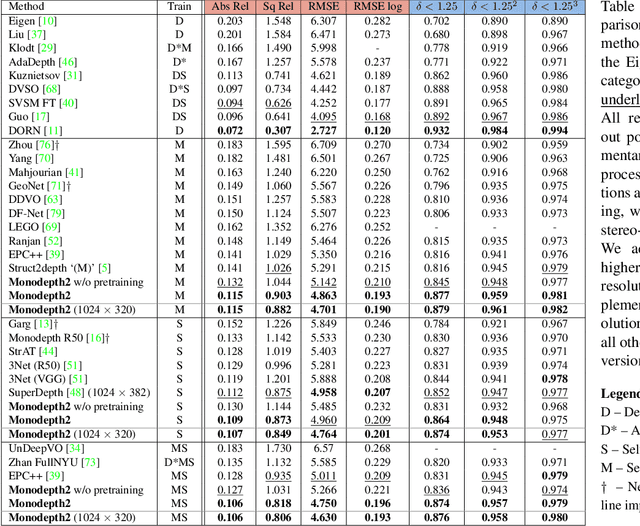


Depth-sensing is important for both navigation and scene understanding. However, procuring RGB images with corresponding depth data for training deep models is challenging; large-scale, varied, datasets with ground truth training data are scarce. Consequently, several recent methods have proposed treating the training of monocular color-to-depth estimation networks as an image reconstruction problem, thus forgoing the need for ground truth depth. There are multiple concepts and design decisions for these networks that seem sensible, but give mixed or surprising results when tested. For example, binocular stereo as the source of self-supervision seems cumbersome and hard to scale, yet results are less blurry compared to training with monocular videos. Such decisions also interplay with questions about architectures, loss functions, image scales, and motion handling. In this paper, we propose a simple yet effective model, with several general architectural and loss innovations, that surpasses all other self-supervised depth estimation approaches on KITTI.
Deep Burst Denoising
Dec 15, 2017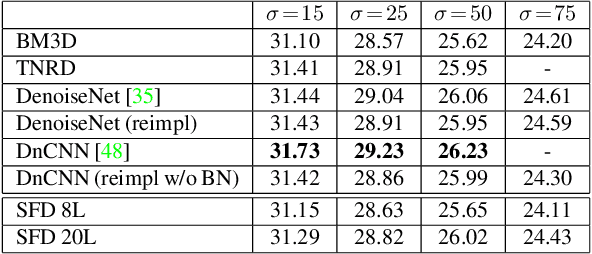
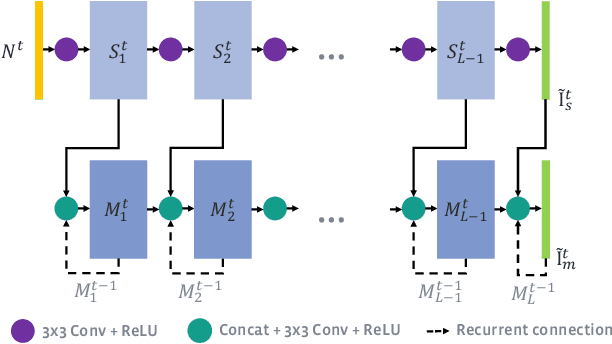

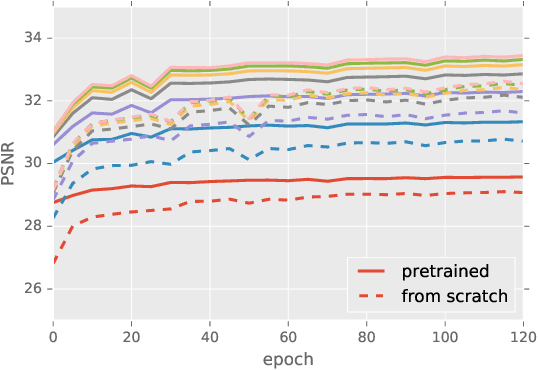
Noise is an inherent issue of low-light image capture, one which is exacerbated on mobile devices due to their narrow apertures and small sensors. One strategy for mitigating noise in a low-light situation is to increase the shutter time of the camera, thus allowing each photosite to integrate more light and decrease noise variance. However, there are two downsides of long exposures: (a) bright regions can exceed the sensor range, and (b) camera and scene motion will result in blurred images. Another way of gathering more light is to capture multiple short (thus noisy) frames in a "burst" and intelligently integrate the content, thus avoiding the above downsides. In this paper, we use the burst-capture strategy and implement the intelligent integration via a recurrent fully convolutional deep neural net (CNN). We build our novel, multiframe architecture to be a simple addition to any single frame denoising model, and design to handle an arbitrary number of noisy input frames. We show that it achieves state of the art denoising results on our burst dataset, improving on the best published multi-frame techniques, such as VBM4D and FlexISP. Finally, we explore other applications of image enhancement by integrating content from multiple frames and demonstrate that our DNN architecture generalizes well to image super-resolution.
Unsupervised Monocular Depth Estimation with Left-Right Consistency
Apr 12, 2017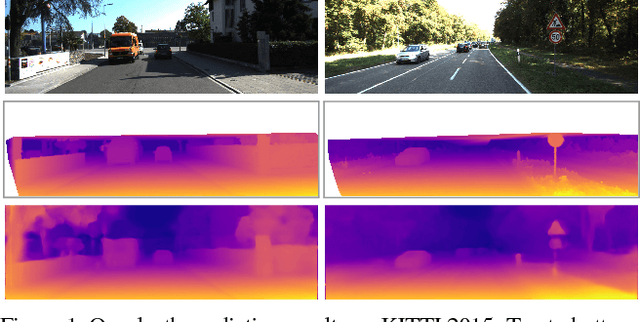

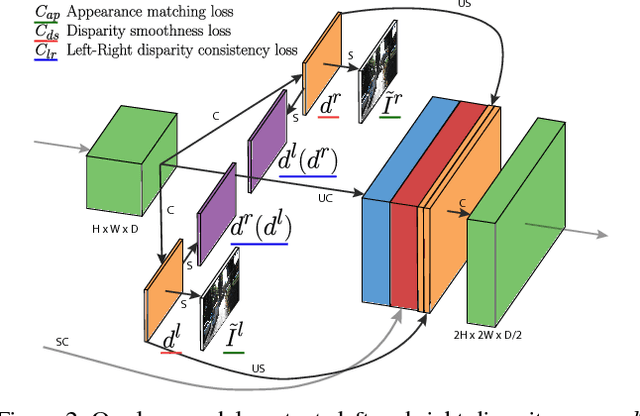
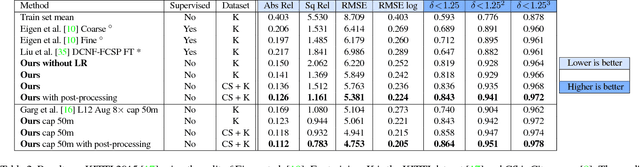
Learning based methods have shown very promising results for the task of depth estimation in single images. However, most existing approaches treat depth prediction as a supervised regression problem and as a result, require vast quantities of corresponding ground truth depth data for training. Just recording quality depth data in a range of environments is a challenging problem. In this paper, we innovate beyond existing approaches, replacing the use of explicit depth data during training with easier-to-obtain binocular stereo footage. We propose a novel training objective that enables our convolutional neural network to learn to perform single image depth estimation, despite the absence of ground truth depth data. Exploiting epipolar geometry constraints, we generate disparity images by training our network with an image reconstruction loss. We show that solving for image reconstruction alone results in poor quality depth images. To overcome this problem, we propose a novel training loss that enforces consistency between the disparities produced relative to both the left and right images, leading to improved performance and robustness compared to existing approaches. Our method produces state of the art results for monocular depth estimation on the KITTI driving dataset, even outperforming supervised methods that have been trained with ground truth depth.