 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuark: Real-time, High-resolution, and General Neural View Synthesis
Nov 25, 2024We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses, the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous works that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, generating the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates. Project page: https://quark-3d.github.io/
Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization
Dec 05, 2019

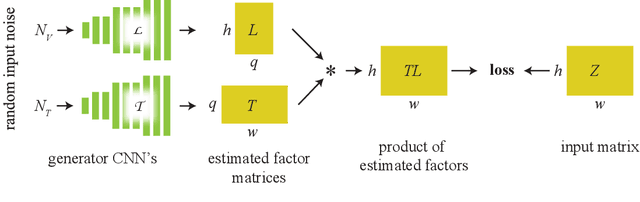

We recover a video of the motion taking place in a hidden scene by observing changes in indirect illumination in a nearby uncalibrated visible region. We solve this problem by factoring the observed video into a matrix product between the unknown hidden scene video and an unknown light transport matrix. This task is extremely ill-posed, as any non-negative factorization will satisfy the data. Inspired by recent work on the Deep Image Prior, we parameterize the factor matrices using randomly initialized convolutional neural networks trained in a one-off manner, and show that this results in decompositions that reflect the true motion in the hidden scene.
* 14 pages, 5 figures, Advances in Neural Information Processing Systems 2019
A Dataset of Multi-Illumination Images in the Wild
Oct 17, 2019
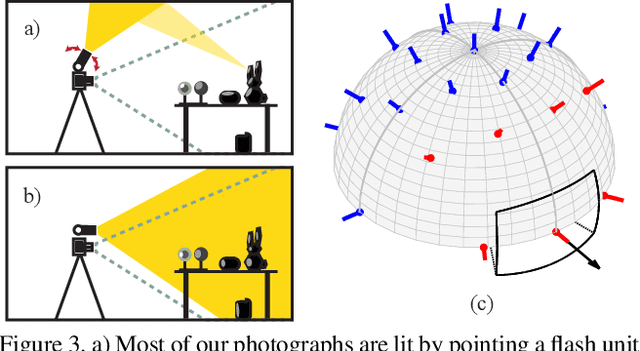
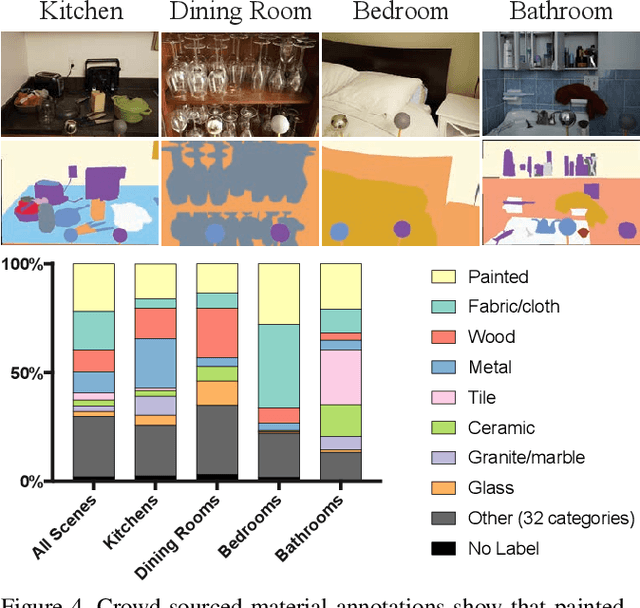

Collections of images under a single, uncontrolled illumination have enabled the rapid advancement of core computer vision tasks like classification, detection, and segmentation. But even with modern learning techniques, many inverse problems involving lighting and material understanding remain too severely ill-posed to be solved with single-illumination datasets. To fill this gap, we introduce a new multi-illumination dataset of more than 1000 real scenes, each captured under 25 lighting conditions. We demonstrate the richness of this dataset by training state-of-the-art models for three challenging applications: single-image illumination estimation, image relighting, and mixed-illuminant white balance.