 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Invariant Face Alignment with a Single CNN
Paper and Code
Jul 19, 2017


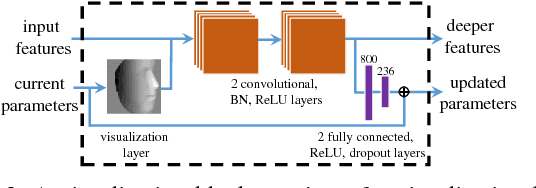
Face alignment has witnessed substantial progress in the last decade. One of the recent focuses has been aligning a dense 3D face shape to face images with large head poses. The dominant technology used is based on the cascade of regressors, e.g., CNN, which has shown promising results. Nonetheless, the cascade of CNNs suffers from several drawbacks, e.g., lack of end-to-end training, hand-crafted features and slow training speed. To address these issues, we propose a new layer, named visualization layer, that can be integrated into the CNN architecture and enables joint optimization with different loss functions. Extensive evaluation of the proposed method on multiple datasets demonstrates state-of-the-art accuracy, while reducing the training time by more than half compared to the typical cascade of CNNs. In addition, we compare multiple CNN architectures with the visualization layer to further demonstrate the advantage of its utilization.