Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP2TV: An Empirical Study on Transformer-based Methods for Video-Text Retrieval
Nov 10, 2021

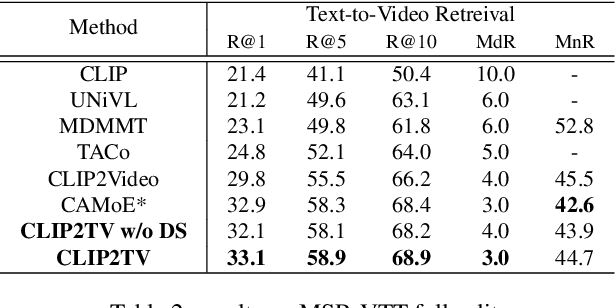

Modern video-text retrieval frameworks basically consist of three parts: video encoder, text encoder and the similarity head. With the success on both visual and textual representation learning, transformer based encoders and fusion methods have also been adopted in the field of video-text retrieval. In this report, we present CLIP2TV, aiming at exploring where the critical elements lie in transformer based methods. To achieve this, We first revisit some recent works on multi-modal learning, then introduce some techniques into video-text retrieval, finally evaluate them through extensive experiments in different configurations. Notably, CLIP2TV achieves 52.9@R1 on MSR-VTT dataset, outperforming the previous SOTA result by 4.1%.
* Tech Report
Via